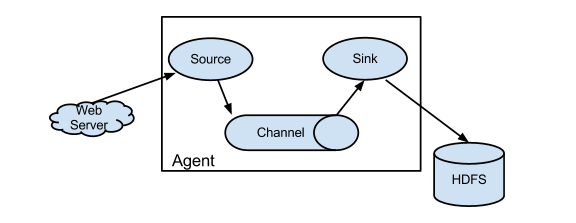
一 概述 flume是一个高可用,高可靠的,分布式的海量日志采集,聚合和传输的软件.特别指的是数据流转的过程,或者说是数据搬运的过程。把数据从一个存储介质通过flume传递到另一个存储介质中。
核心是把数据从数据源(source)收集过来,再将收集的数据送到指定的目的地(sink).为保证一定能送到目的地,再送到目的地之前,会先缓存数据(channel),等到数据到达目的地后,flume删除缓存.
flume支持定义各类数据发送方,用于收集各种类型数据,同时,Flume支持定制各种数据接受方,用于最终存储数据。一般的采集需求,通过对flume的简单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,flume可以适用于大部分的日常数据采集场景。
二 运行机制
1 核心组件
source :用于对接各个不同的数据源
sink:用于对接各个不同存储数据的目的地(数据下沉地)
channel:用于中间临时存储缓存数据
2 机制
flume本身是java程序 在需要采集数据机器上启动 —–>agent进程
agent进程里面包含了:source sink channel
在flume中,数据被包装成event 真是的数据是放在event body中
3 架构
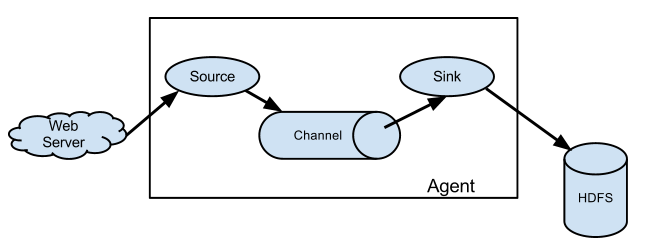
简单架构
只需要部署一个agent进程即可
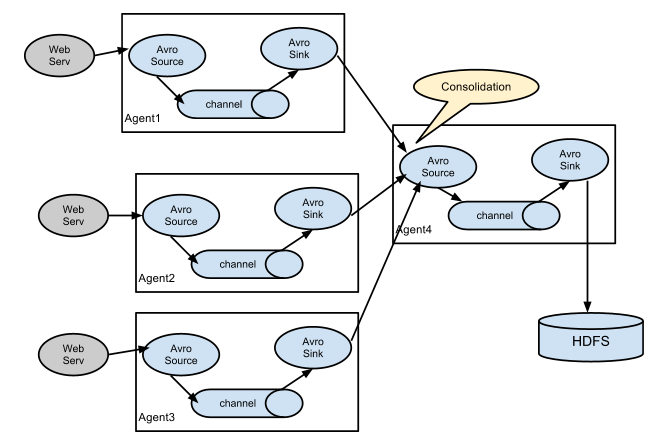
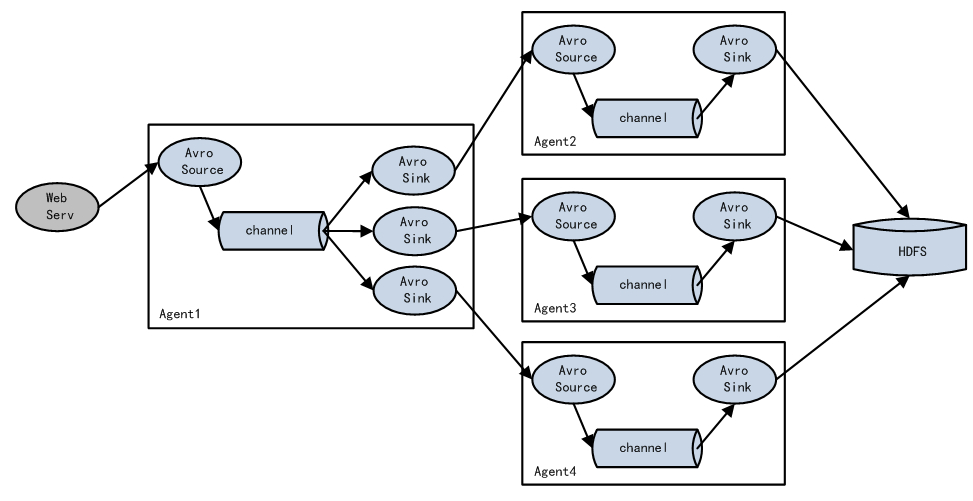
复杂架构
多个agent之间的串联 相当于大家手拉手共同完成数据的采集传输工作
在串联的架构中没有主从之分 大家的地位都是一样的
三 安装部署 上传安装包到数据源所在节点上然后解压 tar -zxvf apache-flume-1.8.0-bin.tar.gz然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
flume开发步骤
在conf中,就是根据业务需求编写采集方案配置文件
文件名见名知意 通常以souce——sink.conf
具体需要描述清楚sink source channel组件配置信息 结合官网配置
启动命令:
1 2 3 4 5 bin/flume-ng agent --conf conf --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console 命令完整版 bin/flume-ng agent -c ./conf -f ./conf/spool-hdfs.conf -n a1 -Dflume.root.logger=INFO,console 命令精简版 --conf指定配置文件的目录 --conf-file指定采集方案路径 --name agent进程名字 要跟采集方案中保持一致
四 测试环境: 在conf目录下配置:vi netcat-logger.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动agent去采集数据:
1 bin/flume-ng agent --conf conf --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console
测试:
先要往agent采集监听的端口上发送数据,让agent有数据可采。
随便在一个能跟agent节点联网的机器上:
telnetanget-hostname port (telnet localhost 44444)
五 采集目录到hdfs: 需求:服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去
l 采集源,即source——监控文件目录 : spooldir
l 下沉目标,即sink——HDFS文件系统 : hdfs sink
l source和sink之间的传递通道——channel,可用file channel 也可以用内存channel
编写配置文件:vim spooldir-hdfs.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/logs a1.sources.r1.fileHeader = true a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/ a1.sinks.k1.hdfs.filePrefix = events- a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.rollInterval = 3 a1.sinks.k1.hdfs.rollSize = 20 a1.sinks.k1.hdfs.rollCount = 5 a1.sinks.k1.hdfs.batchSize = 1 a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.fileType = DataStream a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
参数解释(sink):
1 2 3 4 5 6 7 8 9 10 11 roll控制写入hdfs文件 以何种方式进行滚动 a1.sinks.k1.hdfs.rollInterval = 3 以时间间隔 a1.sinks.k1.hdfs.rollSize = 20 以文件大小 a1.sinks.k1.hdfs.rollCount = 5 event的个数 以event个数如果三个都配置 谁先满足谁触发滚动如果不想以某种属性滚动 设置为0即可 是否开启时间上的舍弃 控制文件夹以多少时间间隔滚动 以下述为例:就会每10分钟生成一个文件夹 a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute
Channel参数解释:
capacity:默认该通道中最大的可以存储的event数量
trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量
注意:
注意其监控的文件夹下面不能有同名文件的产生
如果有 报错且罢工 后续就不再进行数据的监视采集了
在企业中通常给文件追加时间戳命名的方式保证文件不会重名
启动同上:
测试 :往源目录里存入文件
六 采集文件到HDFS 需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs
l 采集源,即source——监控文件内容更新 : exec ‘tail-F file’
l 下沉目标,即sink——HDFS文件系统 : hdfssink
l Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
编写配置文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /root/logs/test.log a1.sources.r1.channels = c1 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /flume/tailout/%y-%m-%d/%H%M/ a1.sinks.k1.hdfs.filePrefix = events- a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.rollInterval = 3 a1.sinks.k1.hdfs.rollSize = 20 a1.sinks.k1.hdfs.rollCount = 5 a1.sinks.k1.hdfs.batchSize = 1 a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.fileType = DataStream a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
参数解析:
· rollInterval
默认值:30
hdfssink间隔多长将临时文件滚动成最终目标文件,单位:秒;
如果设置成0,则表示不根据时间来滚动文件;
注:滚动(roll)指的是,hdfs sink将临时文件重命名成最终目标文件,并新打开一个临时文件来写入数据;
rollsize
默认值:1024
当临时文件达到该大小(单位:bytes)时,滚动成目标文件;
如果设置成0,则表示不根据临时文件大小来滚动文件;
rootcount
默认值:10
当events数据达到该数量时候,将临时文件滚动成目标文件;
如果设置成0,则表示不根据events数据来滚动文件;
round
默认值:false
是否启用时间上的“舍弃”,这里的“舍弃”,类似于“四舍五入”。
roundvalue
默认值:1
时间上进行“舍弃”的值;
roundunit
默认值:seconds
时间上进行“舍弃”的单位,包含:second,minute,hour
示例:
a1.sinks.k1.hdfs.path= /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.round= true
a1.sinks.k1.hdfs.roundValue= 10
a1.sinks.k1.hdfs.roundUnit= minute
当时间为2015-10-16 17:38:59时候,hdfs.path依然会被解析为:
/flume/events/20151016/17:30/00
因为设置的是舍弃10分钟内的时间,因此,该目录每10分钟新生成一个。
启动同上:
测试:exec source 可以执行指定的linux command 把命令的结果作为数据进行收集
1 2 while true; do date >> /root/logs/test.log;done 使用该脚本模拟数据实时变化的过程
七 Flume的load-balance、failover 1 负载均衡
所谓的负载均衡 用于解决一个进程或者程序处理不了所有请求 多个进程一起处理的场景
同一个请求只能交给一个进行处理 避免数据重复
如何分配请求就涉及到了负载均衡的算法:轮询(round_robin) 随机(random) 权重
例如三节点配置:
主节点:vim exec-avro.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 agent1.channels = c1 agent1.sources = r1 agent1.sinks = k1 k2 agent1.sinkgroups = g1 agent1.channels.c1.type = memory agent1.channels.c1.capacity = 1000 agent1.channels.c1.transactionCapacity = 100 agent1.sources.r1.channels = c1 agent1.sources.r1.type = exec agent1.sources.r1.command = tail -F /root/logs/123.log agent1.sinks.k1.channel = c1 agent1.sinks.k1.type = avro agent1.sinks.k1.hostname = node02 agent1.sinks.k1.port = 52020 agent1.sinks.k2.channel = c1 agent1.sinks.k2.type = avro agent1.sinks.k2.hostname = node03 agent1.sinks.k2.port = 52020 agent1.sinkgroups.g1.sinks = k1 k2 agent1.sinkgroups.g1.processor.type = load_balance agent1.sinkgroups.g1.processor.backoff = true #如果开启,则将失败的sink放入黑名单 agent1.sinkgroups.g1.processor.selector = round_robin agent1.sinkgroups.g1.processor.selector.maxTimeOut =10000 #在黑名单放置的超时时间,超时结束时,若仍然无法接收,则超时时间呈指数增长 bin/flume-ng agent -c conf -f conf/exec-avro.conf -n agent1 -Dflume.root.logger=INFO,console
第二节点:vim avro-logger.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.channels = c1 a1.sources.r1.bind = node02 a1.sources.r1.port = 52020 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
第三节点:vim avro-logger.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.channels = c1 a1.sources.r1.bind = node03 a1.sources.r1.port = 52020 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 bin/flume-ng agent -c conf -f conf/avro-logger.conf -n a1 -Dflume.root.logger=INFO,console
flume串联跨网络传输数据
flume串联启动
通常从远离数据源的那一级开始启动
2 flume failover
容错又称之为故障转移 容忍错误的发生。
通常用于解决单点故障 给容易出故障的地方设置备份
备份越多 容错能力越强 但是资源的浪费越严重
具体流程类似loadbalance,但是内部处理机制与load balance完全不同。
Failover Sink Processor维护一个优先级Sink组件列表,只要有一个Sink组件可用,Event就被传递到下一个组件。故障转移机制的作用是将失败的Sink降级到一个池,在这些池中它们被分配一个冷却时间,随着故障的连续,在重试之前冷却时间增加。一旦Sink成功发送一个事件,它将恢复到活动池。 Sink具有与之相关的优先级,数量越大,优先级越高。
例如,具有优先级为100的sink在优先级为80的Sink之前被激活。如果在发送事件时汇聚失败,则接下来将尝试下一个具有最高优先级的Sink发送事件。如果没有指定优先级,则根据在配置中指定Sink的顺序来确定优先级。
主节点: vim exec-avro.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 agent1.channels = c1 agent1.sources = r1 agent1.sinks = k1 k2 agent1.sinkgroups = g1 agent1.channels.c1.type = memory agent1.channels.c1.capacity = 1000 agent1.channels.c1.transactionCapacity = 100 agent1.sources.r1.channels = c1 agent1.sources.r1.type = exec agent1.sources.r1.command = tail -F /root/logs/456.log agent1.sinks.k1.channel = c1 agent1.sinks.k1.type = avro agent1.sinks.k1.hostname = node02 agent1.sinks.k1.port = 52020 agent1.sinks.k2.channel = c1 agent1.sinks.k2.type = avro agent1.sinks.k2.hostname = node03 agent1.sinks.k2.port = 52020 agent1.sinkgroups.g1.sinks = k1 k2 agent1.sinkgroups.g1.processor.type = failover agent1.sinkgroups.g1.processor.priority.k1 = 10 #优先级值, 绝对值越大表示优先级越高 agent1.sinkgroups.g1.processor.priority.k2 = 1 agent1.sinkgroups.g1.processor.maxpenalty = 10000 #失败的Sink的最大回退期(millis) bin/flume-ng agent -c conf -f conf/exec-avro.conf -n agent1 -Dflume.root.logger=INFO,console
第二节点与第三节点配置 同load-balance的
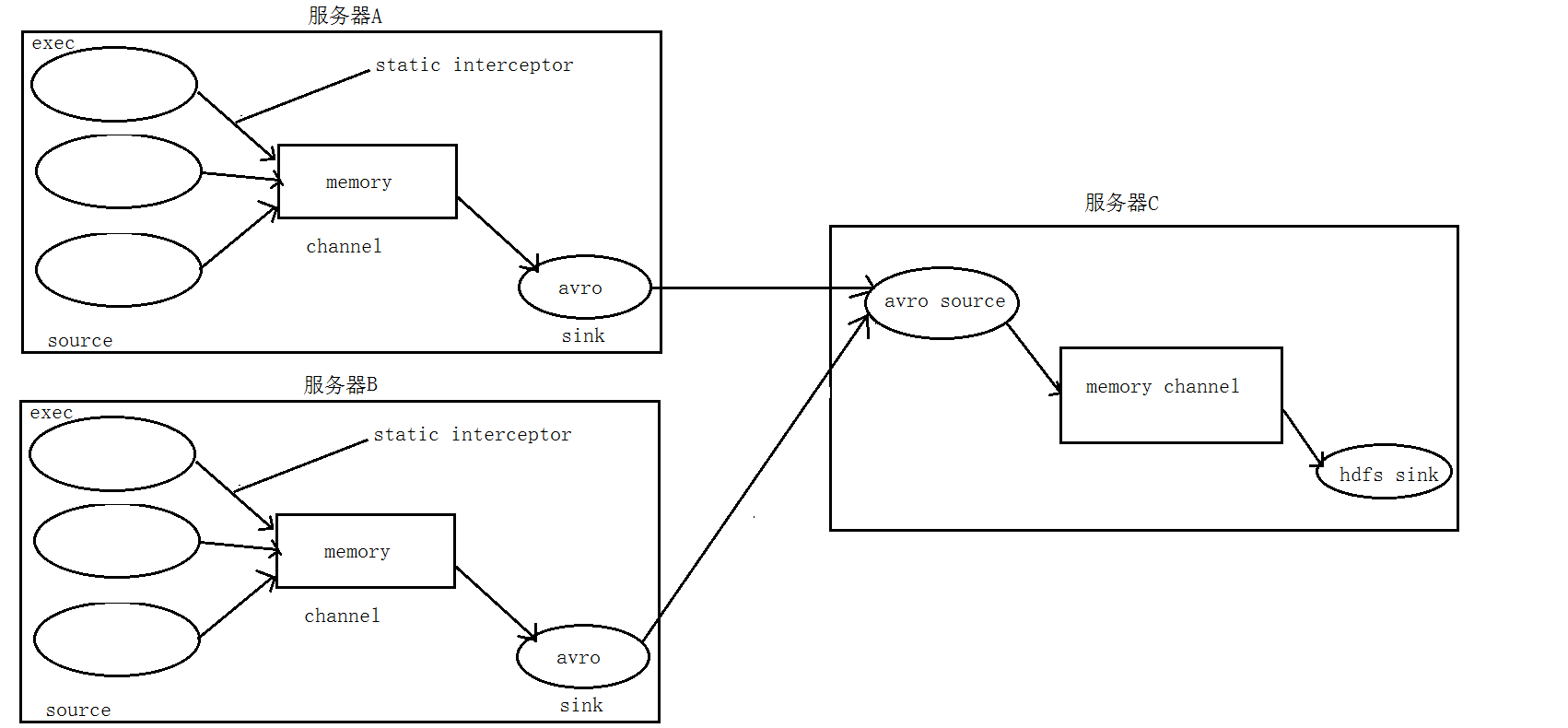
八 flume拦截器 1 静态拦截器 日志的采集与汇总 需求:
A、B两台日志服务机器实时生产日志主要类型为access.log、nginx.log、web.log
把A、B 机器中的access.log、nginx.log、web.log 采集汇总到C机器上然后统一收集到hdfs中
数据流程处理分析:
在第一台节点上配置 vim exec_source_avro_sink.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 a1.sources = r1 r2 r3 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /root/logs/access.log a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = static a1.sources.r1.interceptors.i1.key = type a1.sources.r1.interceptors.i1.value = access a1.sources.r2.type = exec a1.sources.r2.command = tail -F /root/logs/nginx.log a1.sources.r2.interceptors = i2 a1.sources.r2.interceptors.i2.type = static a1.sources.r2.interceptors.i2.key = type a1.sources.r2.interceptors.i2.value = nginx a1.sources.r3.type = exec a1.sources.r3.command = tail -F /root/logs/web.log a1.sources.r3.interceptors = i3 a1.sources.r3.interceptors.i3.type = static a1.sources.r3.interceptors.i3.key = type a1.sources.r3.interceptors.i3.value = web a1.sinks.k1.type = avro a1.sinks.k1.hostname = node02 a1.sinks.k1.port = 41414 a1.channels.c1.type = memory a1.channels.c1.capacity = 2000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sources.r2.channels = c1 a1.sources.r3.channels = c1 a1.sinks.k1.channel = c1
在第三台上配置vim avro_source_hdfs_sink.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = avro a1.sources.r1.bind = node02 a1.sources.r1.port =41414 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder a1.channels.c1.type = memory a1.channels.c1.capacity = 20000 a1.channels.c1.transactionCapacity = 10000 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path =hdfs://node01:9000/source/logs/%{type}/%Y%m%d a1.sinks.k1.hdfs.filePrefix =events a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.writeFormat = Text a1.sinks.k1.hdfs.rollCount = 0 a1.sinks.k1.hdfs.rollInterval = 20 a1.sinks.k1.hdfs.rollSize = 10485760 a1.sinks.k1.hdfs.batchSize = 20 flume操作hdfs的线程数(包括新建,写入等) a1.sinks.k1.hdfs.threadsPoolSize =10 a1.sinks.k1.hdfs.callTimeout =30000 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
使用静态拦截器前后对比:
1 2 3 4 5 6 7 如果没有使用静态拦截器 Event : { headers:{} body: 36 Sun Jun 2 18:26 } 使用静态拦截器之后 自己添加kv标识对 Event : { headers:{type=access} body: 36 Sun Jun 2 18:26 } Event : { headers:{type=nginx} body: 36 Sun Jun 2 18:26 } Event : { headers:{type=web} body: 36 Sun Jun 2 18:26 }
后续在存放数据的时候可以使用flume的规则语法获取到拦截器添加的kv内容
模拟数据实时产生:
1 2 3 while true; do echo "access access....." >> /root/logs/access.log;sleep 0.5;done while true; do echo "web web....." >> /root/logs/web.log;sleep 0.5;done while true; do echo "nginx nginx....." >> /root/logs/nginx.log;sleep 0.5;done
配置完成后:
配置完成之后,在服务器A上的/root/data有数据文件access.log、nginx.log、web.log。
先启动服务器C上的flume,启动命令在flume安装目录下执行 :
bin/flume-ng agent -c conf -f conf/avro_source_hdfs_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
然后在启动服务器上的A,启动命令
在flume安装目录下执行 :
bin/flume-ng agent -c conf -f conf/exec_source_avro_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
2 自定义拦截器 拦截器简介:
Flume有各种自带的拦截器,比如:TimestampInterceptor、HostInterceptor、RegexExtractorInterceptor等,通过使用不同的拦截器,实现不同的功能。但是以上的这些拦截器,不能改变原有日志数据的内容或者对日志信息添加一定的处理逻辑,当一条日志信息有几十个甚至上百个字段的时候,在传统的Flume处理下,收集到的日志还是会有对应这么多的字段,也不能对你想要的字段进行对应的处理。
自定义拦截器:
根据实际业务的需求,为了更好的满足数据在应用层的处理,通过自定义Flume拦截器,过滤掉不需要的字段,并对指定字段加密处理,将源数据进行预处理。减少了数据的传输量,降低了存储的开销.
分为两部分;
1 编写java代码,自定义拦截器
pom.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 <?xml version="1.0" encoding="UTF-8"?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <groupId > cn.baidu.cloud</groupId > <artifactId > example-flume-intercepter</artifactId > <version > 1.0-SNAPSHOT</version > <dependencies > <dependency > <groupId > org.apache.flume</groupId > <artifactId > flume-ng-sdk</artifactId > <version > 1.8.0</version > </dependency > <dependency > <groupId > org.apache.flume</groupId > <artifactId > flume-ng-core</artifactId > <version > 1.8.0</version > </dependency > </dependencies > <build > <plugins > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-compiler-plugin</artifactId > <version > 3.0</version > <configuration > <source > 1.8</source > <target > 1.8</target > <encoding > UTF-8</encoding > </configuration > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-shade-plugin</artifactId > <version > 3.1.1</version > <executions > <execution > <phase > package</phase > <goals > <goal > shade</goal > </goals > <configuration > <filters > <filter > <artifact > *:*</artifact > <excludes > <exclude > META-INF/*.SF</exclude > <exclude > META-INF/*.DSA</exclude > <exclude > META-INF/*.RSA</exclude > </excludes > </filter > </filters > <transformers > <transformer implementation ="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer" > <mainClass > </mainClass > </transformer > </transformers > </configuration > </execution > </executions > </plugin > </plugins > </build > </project >
java代码:
定义一个类CustomParameterInterceptor实现Interceptor接口。
在CustomParameterInterceptor类中定义变量,这些变量是需要到
添加CustomParameterInterceptor的有参构造方法。并对相应的变量进行处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 import com.google.common.base.Charsets;import org.apache.flume.Context;import org.apache.flume.Event;import org.apache.flume.interceptor.Interceptor;import java.security.MessageDigest;import java.security.NoSuchAlgorithmException;import java.util.ArrayList;import java.util.List;import java.util.regex.Matcher;import java.util.regex.Pattern;import static cn.baidu.interceptor.CustomParameterInterceptor.Constants.*;public class CustomParameterInterceptor implements Interceptor private final String fields_separator; private final String indexs; private final String indexs_separator; private final String encrypted_field_index; public CustomParameterInterceptor ( String fields_separator, String indexs, String indexs_separator,String encrypted_field_index) String f = fields_separator.trim(); String i = indexs_separator.trim(); this .indexs = indexs; this .encrypted_field_index=encrypted_field_index.trim(); if (!f.equals("" )) { f = UnicodeToString(f); } this .fields_separator =f; if (!i.equals("" )) { i = UnicodeToString(i); } this .indexs_separator = i; }
\t 制表符 的UNicode编码格式为(‘\u0009’)
将配置文件中传过来的unicode编码进行转换为字符串。
写具体的要处理的逻辑intercept()方法,一个是单个处理的,一个是批量处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 public static String UnicodeToString (String str) Pattern pattern = Pattern.compile("(\\\\u(\\p{XDigit}{4}))" ); Matcher matcher = pattern.matcher(str); char ch; while (matcher.find()) { ch = (char ) Integer.parseInt(matcher.group(2 ), 16 ); str = str.replace(matcher.group(1 ), ch + "" ); } return str; } public Event intercept (Event event) if (event == null ) { return null ; } try { String line = new String(event.getBody(), Charsets.UTF_8); String[] fields_spilts = line.split(fields_separator); String[] indexs_split = indexs.split(indexs_separator); String newLine="" ; for (int i = 0 ; i < indexs_split.length; i++) { int parseInt = Integer.parseInt(indexs_split[i]); if (!"" .equals(encrypted_field_index)&&encrypted_field_index.equals(indexs_split[i])){ newLine+=StringUtils.GetMD5Code(fields_spilts[parseInt]); }else { newLine+=fields_spilts[parseInt]; } if (i!=indexs_split.length-1 ){ newLine+=fields_separator; } } event.setBody(newLine.getBytes(Charsets.UTF_8)); return event; } catch (Exception e) { return event; } } public List<Event> intercept (List<Event> events) List<Event> out = new ArrayList<Event>(); for (Event event : events) { Event outEvent = intercept(event); if (outEvent != null ) { out.add(outEvent); } } return out; } public void initialize () } public void close () }
接口中定义了一个内部接口Builder,在configure方法中,进行一些参数配置。并给出,在flume的conf中没配置一些参数时,给出其默认值。通过其builder方法,返回一个CustomParameterInterceptor对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public static class Builder implements Interceptor .Builder private String fields_separator; private String indexs; private String indexs_separator; private String encrypted_field_index; public void configure (Context context) fields_separator = context.getString(FIELD_SEPARATOR, DEFAULT_FIELD_SEPARATOR); indexs = context.getString(INDEXS, DEFAULT_INDEXS); indexs_separator = context.getString(INDEXS_SEPARATOR, DEFAULT_INDEXS_SEPARATOR); encrypted_field_index= context.getString(ENCRYPTED_FIELD_INDEX, DEFAULT_ENCRYPTED_FIELD_INDEX); } public Interceptor build () return new CustomParameterInterceptor(fields_separator, indexs, indexs_separator,encrypted_field_index); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public static class Constants public static final String FIELD_SEPARATOR = "fields_separator" ; public static final String DEFAULT_FIELD_SEPARATOR =" " ; public static final String INDEXS = "indexs" ; public static final String DEFAULT_INDEXS = "0" ; public static final String INDEXS_SEPARATOR = "indexs_separator" ; public static final String DEFAULT_INDEXS_SEPARATOR = "," ; public static final String ENCRYPTED_FIELD_INDEX = "encrypted_field_index" ; public static final String DEFAULT_ENCRYPTED_FIELD_INDEX = "" ; public static final String PROCESSTIME = "processTime" ; public static final String DEFAULT_PROCESSTIME = "a" ; }
定义一个静态类,类中封装MD5加密方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public static class StringUtils private final static String[] strDigits = { "0" , "1" , "2" , "3" , "4" , "5" , "6" , "7" , "8" , "9" , "a" , "b" , "c" , "d" , "e" , "f" }; private static String byteToArrayString (byte bByte) int iRet = bByte; if (iRet < 0 ) { iRet += 256 ; } int iD1 = iRet / 16 ; int iD2 = iRet % 16 ; return strDigits[iD1] + strDigits[iD2]; } private static String byteToNum (byte bByte) int iRet = bByte; System.out.println("iRet1=" + iRet); if (iRet < 0 ) { iRet += 256 ; } return String.valueOf(iRet); } private static String byteToString (byte [] bByte) StringBuffer sBuffer = new StringBuffer(); for (int i = 0 ; i < bByte.length; i++) { sBuffer.append(byteToArrayString(bByte[i])); } return sBuffer.toString(); } public static String GetMD5Code (String strObj) String resultString = null ; try { resultString = new String(strObj); MessageDigest md = MessageDigest.getInstance("MD5" ); resultString = byteToString(md.digest(strObj.getBytes())); } catch (NoSuchAlgorithmException ex) { ex.printStackTrace(); } return resultString; } } }
通过以上步骤,自定义拦截器的代码开发已完成,然后打包成jar,放到Flume的根目录下的lib中
新增配置文件: vim spool-interceptor-hdfs.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 a1.channels = c1 a1.sources = r1 a1.sinks = s1 a1.channels.c1.type = memory a1.channels.c1.capacity =1000 a1.channels.c1.transactionCapacity =200 a1.sources.r1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /root/logs4/ a1.sources.r1.batchSize = 50 a1.sources.r1.inputCharset = UTF-8 a1.sources.r1.interceptors =i1 i2 a1.sources.r1.interceptors.i1.type =cn.baidu.interceptor.CustomParameterInterceptor$Builder a1.sources.r1.interceptors.i1.fields_separator =\\u0009 a1.sources.r1.interceptors.i1.indexs =0,1,3,5,6 a1.sources.r1.interceptors.i1.indexs_separator =\\u002c a1.sources.r1.interceptors.i1.encrypted_field_index =0 a1.sources.r1.interceptors.i2.type = org.apache.flume.interceptor.TimestampInterceptor$Builder a1.sinks.s1.channel = c1 a1.sinks.s1.type = hdfs a1.sinks.s1.hdfs.path =hdfs://node01:9000/intercept/%Y%m%d a1.sinks.s1.hdfs.filePrefix = itcasr a1.sinks.s1.hdfs.fileSuffix = .dat a1.sinks.s1.hdfs.rollSize = 10485760 a1.sinks.s1.hdfs.rollInterval =20 a1.sinks.s1.hdfs.rollCount = 0 a1.sinks.s1.hdfs.batchSize = 2 a1.sinks.s1.hdfs.round = true a1.sinks.s1.hdfs.roundUnit = minute a1.sinks.s1.hdfs.threadsPoolSize = 25 a1.sinks.s1.hdfs.useLocalTimeStamp = true a1.sinks.s1.hdfs.minBlockReplicas = 1 a1.sinks.s1.hdfs.fileType =DataStream a1.sinks.s1.hdfs.writeFormat = Text a1.sinks.s1.hdfs.callTimeout = 60000 a1.sinks.s1.hdfs.idleTimeout =60 //启动 bin/flume-ng agent -c conf -f conf/spool-interceptor-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
九 自定义组件 1flume自定义source 说明: Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。官方提供的source类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些source。
如:实时监控MySQL,从MySQL中获取数据传输到HDFS或者其他存储框架,所以此时需要我们自己实现MySQLSource 。
官方也提供了自定义source的接口:
官网说明:https://flume.apache.org/FlumeDeveloperGuide.html#source
实现原理: 根据官方说明自定义mysqlsource需要继承AbstractSource类并实现Configurable和PollableSource接口。
实现相应方法:
getBackOffSleepIncrement() //此处暂不用
getMaxBackOffSleepInterval() //此处暂不用
configure(Context context) //初始化context
process() //获取数据(从mysql获取数据,业务处理比较复杂,所以我们定义一个专门的类——QueryMysql来处理跟mysql的交互),封装成event并写入channel,这个方法被循环调用
stop() //关闭相关的资源
###实现:
创建数据库及表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 CREATE DATABASE `mysqlsource` ;USE `mysqlsource` ;DROP TABLE IF EXISTS `flume_meta` ;CREATE TABLE `flume_meta` ( `source_tab` VARCHAR (255 ) NOT NULL , `currentIndex` VARCHAR (255 ) NOT NULL , PRIMARY KEY (`source_tab` ) ) ENGINE = INNODB DEFAULT CHARSET = utf8; DROP TABLE IF EXISTS `student` ;CREATE TABLE `student` ( `id` INT (11 ) NOT NULL AUTO_INCREMENT, `name` VARCHAR (255 ) NOT NULL , PRIMARY KEY (`id` ) ) ENGINE = INNODB AUTO_INCREMENT = 5 DEFAULT CHARSET = utf8; INSERT INTO `student` (`id` , `name` )VALUES (1 , 'zhangsan' ), (2 , 'lisi' ), (3 , 'wangwu' ), (4 , 'zhaoliu' );
pom.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 <?xml version="1.0" encoding="UTF-8"?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <groupId > cn.baidu.cloud</groupId > <artifactId > example-flume</artifactId > <version > 1.1</version > <dependencies > <dependency > <groupId > org.apache.flume</groupId > <artifactId > flume-ng-core</artifactId > <version > 1.8.0</version > <scope > provided</scope > </dependency > <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 5.1.38</version > </dependency > <dependency > <groupId > org.apache.commons</groupId > <artifactId > commons-lang3</artifactId > <version > 3.6</version > </dependency > <dependency > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > <version > 1.16.22</version > </dependency > </dependencies > <build > <plugins > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-compiler-plugin</artifactId > <version > 3.0</version > <configuration > <source > 1.8</source > <target > 1.8</target > <encoding > UTF-8</encoding > </configuration > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-shade-plugin</artifactId > <version > 3.1.1</version > <executions > <execution > <phase > package</phase > <goals > <goal > shade</goal > </goals > <configuration > <filters > <filter > <artifact > *:*</artifact > <excludes > <exclude > META-INF/*.SF</exclude > <exclude > META-INF/*.DSA</exclude > <exclude > META-INF/*.RSA</exclude > </excludes > </filter > </filters > <transformers > <transformer implementation ="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer" > <mainClass > </mainClass > </transformer > </transformers > </configuration > </execution > </executions > </plugin > </plugins > </build > </project >
自定义QueryMySql工具类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 package cn.baidu.flumesource;import org.apache.flume.Context;import org.apache.flume.conf.ConfigurationException;import org.apache.http.ParseException;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import java.sql.*;import java.util.ArrayList;import java.util.List;import java.util.Properties;@Data @Getter @Setter public class QueryMySql private static final Logger LOG = LoggerFactory.getLogger(QueryMySql.class); private int runQueryDelay, startFrom, currentIndex, recordSixe = 0 , maxRow; private String table, columnsToSelect, customQuery, query, defaultCharsetResultSet; private Context context; private static final int DEFAULT_QUERY_DELAY = 10000 ; private static final int DEFAULT_START_VALUE = 0 ; private static final int DEFAULT_MAX_ROWS = 2000 ; private static final String DEFAULT_COLUMNS_SELECT = "*" ; private static final String DEFAULT_CHARSET_RESULTSET = "UTF-8" ; private static Connection conn = null ; private static PreparedStatement ps = null ; private static String connectionURL, connectionUserName, connectionPassword; static { Properties p = new Properties(); try { p.load(QueryMySql.class.getClassLoader().getResourceAsStream("jdbc.properties" )); connectionURL = p.getProperty("dbUrl" ); connectionUserName = p.getProperty("dbUser" ); connectionPassword = p.getProperty("dbPassword" ); Class.forName(p.getProperty("dbDriver" )); } catch (Exception e) { LOG.error(e.toString()); } } private static Connection InitConnection (String url, String user, String pw) try { Connection conn = DriverManager.getConnection(url, user, pw); if (conn == null ) throw new SQLException(); return conn; } catch (SQLException e) { e.printStackTrace(); } return null ; } QueryMySql(Context context) throws ParseException { this .context = context; this .columnsToSelect = context.getString("columns.to.select" , DEFAULT_COLUMNS_SELECT); this .runQueryDelay = context.getInteger("run.query.delay" , DEFAULT_QUERY_DELAY); this .startFrom = context.getInteger("start.from" , DEFAULT_START_VALUE); this .defaultCharsetResultSet = context.getString("default.charset.resultset" , DEFAULT_CHARSET_RESULTSET); this .table = context.getString("table" ); this .customQuery = context.getString("custom.query" ); connectionURL = context.getString("connection.url" ); connectionUserName = context.getString("connection.user" ); connectionPassword = context.getString("connection.password" ); conn = InitConnection(connectionURL, connectionUserName, connectionPassword); checkMandatoryProperties(); currentIndex = getStatusDBIndex(startFrom); query = buildQuery(); } private void checkMandatoryProperties () if (table == null ) { throw new ConfigurationException("property table not set" ); } if (connectionURL == null ) { throw new ConfigurationException("connection.url property not set" ); } if (connectionUserName == null ) { throw new ConfigurationException("connection.user property not set" ); } if (connectionPassword == null ) { throw new ConfigurationException("connection.password property not set" ); } } private String buildQuery () String sql = "" ; currentIndex = getStatusDBIndex(startFrom); LOG.info(currentIndex + "" ); if (customQuery == null ) { sql = "SELECT " + columnsToSelect + " FROM " + table; } else { sql = customQuery; } StringBuilder execSql = new StringBuilder(sql); if (!sql.contains("where" )) { execSql.append(" where " ); execSql.append("id" ).append(">" ).append(currentIndex); return execSql.toString(); } else { int length = execSql.toString().length(); return execSql.toString().substring(0 , length - String.valueOf(currentIndex).length()) + currentIndex; } } List<List<Object>> executeQuery() { try { customQuery = buildQuery(); List<List<Object>> results = new ArrayList<>(); if (ps == null ) { ps = conn.prepareStatement(customQuery); } ResultSet result = ps.executeQuery(customQuery); while (result.next()) { List<Object> row = new ArrayList<>(); for (int i = 1 ; i <= result.getMetaData().getColumnCount(); i++) { row.add(result.getObject(i)); } results.add(row); } LOG.info("execSql:" + customQuery + "\nresultSize:" + results.size()); return results; } catch (SQLException e) { LOG.error(e.toString()); conn = InitConnection(connectionURL, connectionUserName, connectionPassword); } return null ; } List<String> getAllRows (List<List<Object>> queryResult) { List<String> allRows = new ArrayList<>(); if (queryResult == null || queryResult.isEmpty()) return allRows; StringBuilder row = new StringBuilder(); for (List<Object> rawRow : queryResult) { Object value = null ; for (Object aRawRow : rawRow) { value = aRawRow; if (value == null ) { row.append("," ); } else { row.append(aRawRow.toString()).append("," ); } } allRows.add(row.toString()); row = new StringBuilder(); } return allRows; } void updateOffset2DB (int size) String sql = "insert into flume_meta(source_tab,currentIndex) VALUES('" + this .table + "','" + (recordSixe += size) + "') on DUPLICATE key update source_tab=values(source_tab),currentIndex=values(currentIndex)" ; LOG.info("updateStatus Sql:" + sql); execSql(sql); } private void execSql (String sql) try { ps = conn.prepareStatement(sql); LOG.info("exec::" + sql); ps.execute(); } catch (SQLException e) { e.printStackTrace(); } } private Integer getStatusDBIndex (int startFrom) String dbIndex = queryOne("select currentIndex from flume_meta where source_tab='" + table + "'" ); if (dbIndex != null ) { return Integer.parseInt(dbIndex); } return startFrom; } private String queryOne (String sql) ResultSet result = null ; try { ps = conn.prepareStatement(sql); result = ps.executeQuery(); while (result.next()) { return result.getString(1 ); } } catch (SQLException e) { e.printStackTrace(); } return null ; } void close () try { ps.close(); conn.close(); } catch (SQLException e) { e.printStackTrace(); } } }
自定义MySqlSource主类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 package cn.baidu.flumesource;import org.apache.flume.Context;import org.apache.flume.Event;import org.apache.flume.EventDeliveryException;import org.apache.flume.PollableSource;import org.apache.flume.conf.Configurable;import org.apache.flume.event.SimpleEvent;import org.apache.flume.source.AbstractSource;import org.slf4j.Logger;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import static org.slf4j.LoggerFactory.*;public class MySqlSource extends AbstractSource implements Configurable , PollableSource private static final Logger LOG = getLogger(MySqlSource.class); private QueryMySql sqlSourceHelper; @Override public long getBackOffSleepIncrement () return 0 ; } @Override public long getMaxBackOffSleepInterval () return 0 ; } @Override public void configure (Context context) sqlSourceHelper = new QueryMySql(context); } @Override public PollableSource.Status process () throws EventDeliveryException { try { List<List<Object>> result = sqlSourceHelper.executeQuery(); List<Event> events = new ArrayList<>(); HashMap<String, String> header = new HashMap<>(); if (!result.isEmpty()) { List<String> allRows = sqlSourceHelper.getAllRows(result); Event event = null ; for (String row : allRows) { event = new SimpleEvent(); event.setBody(row.getBytes()); event.setHeaders(header); events.add(event); } this .getChannelProcessor().processEventBatch(events); sqlSourceHelper.updateOffset2DB(result.size()); } Thread.sleep(sqlSourceHelper.getRunQueryDelay()); return Status.READY; } catch (InterruptedException e) { LOG.error("Error procesing row" , e); return Status.BACKOFF; } } @Override public synchronized void stop () LOG.info("Stopping sql source {} ..." , getName()); try { sqlSourceHelper.close(); } finally { super .stop(); } } }
使用maven对工程进行打包,需要将mysql的依赖包一起打到jar包里,然后将打包好的jar包放到flume的lib目录下。
配置文件: vim mysqlsource.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = cn.baidu.flumesource.MySqlSource a1.sources.r1.connection.url = jdbc:mysql://node01:3306/mysqlsource a1.sources.r1.connection.user = root a1.sources.r1.connection.password = hadoop a1.sources.r1.table = student a1.sources.r1.columns.to.select = * a1.sources.r1.incremental.column.name = id a1.sources.r1.incremental.value = 0 a1.sources.r1.run.query.delay=3000 # Describe the sink a1.sinks.k1.type = logger # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动:
1 bin/flume-ng agent -c conf -fconf/mysqlsource.conf -n a1 -Dflume.root.logger=INFO,console
2flume自定义sink ###说明:
同自定义source类似,对于某些sink如果没有我们想要的,我们也可以自定义sink实现将数据保存到我们想要的地方去,例如kafka,或者mysql,或者文件等等都可以
需求:从网络端口当中发送数据,自定义sink,使用sink从网络端口接收数据,然后将数据保存到本地文件当中去。
pom.xml 同自定义source
自定义mysink
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 package cn.baidu.flumesink;import org.apache.commons.io.FileUtils;import org.apache.flume.*;import org.apache.flume.conf.Configurable;import org.apache.flume.sink.AbstractSink;import java.io.*;public class MySink extends AbstractSink implements Configurable private Context context ; private String filePath = "" ; private String fileName = "" ; private File fileDir; @Override public void configure (Context context) try { this .context = context; filePath = context.getString("filePath" ); fileName = context.getString("fileName" ); fileDir = new File(filePath); if (!fileDir.exists()){ fileDir.mkdirs(); } } catch (Exception e) { e.printStackTrace(); } } @Override public Status process () throws EventDeliveryException Event event = null ; Channel channel = this .getChannel(); Transaction transaction = channel.getTransaction(); transaction.begin(); while (true ){ event = channel.take(); if (null != event){ break ; } } byte [] body = event.getBody(); String line = new String(body); try { FileUtils.write(new File(filePath+File.separator+fileName),line,true ); transaction.commit(); } catch (IOException e) { transaction.rollback(); e.printStackTrace(); return Status.BACKOFF; }finally { transaction.close(); } return Status.READY; } }
将代码使用打包插件,打成jar包,注意一定要将commons-langs这个依赖包打进去,放到flume的lib目录下
配置conf文件 vim filesink.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = netcat a1.sources.r1.bind = node01 a1.sources.r1.port = 5678 a1.sources.r1.channels = c1 a1.sinks.k1.type = cn.baidu.flumesink.MySink a1.sinks.k1.filePath =/export/servers a1.sinks.k1.fileName =filesink.txt a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动
1 bin/flume-ng agent -c conf -f conf/filesink.conf -n a1 -Dflume.root.logger=INFO,console
Telnet node01 5678 连接到机器端口上输入数据