Scala入门
一 什么是Scala
scala是运行在 JVM 上的多范式编程语言,同时支持面向对象和面向函数编程 (如java是面向对象的也是面向接口的,懂得自然懂)
早期,scala刚出现的时候,并没有怎么引起重视,随着Spark和Kafka这样基于scala的大数据框架
的兴起,scala逐步进入大数据开发者的眼帘。scala的主要优势是它的表达性。
1 使用场景:
开发大数据应用程序(Spark程序、Flink程序)
表达能力强,一行代码抵得上Java多行,开发速度快
兼容Java,可以访问庞大的Java类库,例如:操作mysql、redis、freemarker、activemq等等
2 scala与java的简单对比
scala定义三个实体类:
1 | case class User(var name:String,var orders:List[Order]) //用户实体类 |
讲一个列表中的字符串(数字类型) 转为数字列表:
1 | val ints = list.map(s => s.toInt) |
二 开发环境搭建
1 java与scala的编译流程
java
java源代码> (javac编译)>java字节码和java类库>(加载)>jvm>(解释执行)>操作系统
scala:
scala源代码>(scalac编译)>java字节码和java类库和scala类库>(加载)>jvm>(解释执行)>操作系统
scala程序运行需要依赖于Java类库,必须要有Java运行环境,scala才能正确执行.scala源文件也是编译为class文件
根据上述流程图,要编译运行scala程序,需要
jdk(jvm)
scala编译器(scala SDK)
2jdk安装
略
3安装SDK
下载安装即可.
idea安装scala插件
三scala的解释器
后续我们会使用scala解释器来学习scala基本语法,scala解释器像Linux命令一样,执行一条代
码,马上就可以让我们看到执行结果,用来测试比较方便。
启动:
win+r 后输入scala
退出:
1 | :quit |
四 语法
1 定义变量
格式:
1 | var/val 变量标识:变量类型 = 初始值 |
val 定义的是不可重新赋值的变量
var 定义的是可重新赋值的变量
注意: 句尾不用写分号.
1 | 重心赋值: |
使用类型推断来定义变量
1 | var name = "nicai" |
scala可以自动根据变量的值来自动推断变量的类型,这样编写代码更加简洁。
惰性赋值
在企业的大数据开发中,有时候会编写非常复杂的SQL语句,这些SQL语句可能有几百行甚至上千
行。这些SQL语句,如果直接加载到JVM中,会有很大的内存开销。如何解决?
当有一些变量保存的数据较大时,但是不需要马上加载到JVM内存。可以使用惰性赋值来提高效
率。
语法格式:
1 | lazy var/val 变量标书:变量类型 = 值 |
示例
在程序中需要执行一条以下复杂的SQL语句,我们希望只有用到这个SQL语句才加载它。
1 | """insert overwrite table adm.itcast_adm_personas |
2 字符串
多种定义字符串;
使用双引号
使用插值表达式
使用三引号
1使用双引号
1 | var/val name= "值" name.length 长度 |
2 使用插值表达式
scala中,可以使用插值表达式来定义字符串,有效避免大量字符串的拼接。
1 | var name="n" |
3 使用三引号
如果有大段的文本需要保存,就可以使用三引号来定义字符串。例如:保存一大段的SQL语句。三
个引号中间的所有字符串都将作为字符串的值。(包括空行,空格等)
1 | val/var 变量名 = """字符串1 |
1 | val sql = """select |
五 数据类型与操作符
scala中的类型以及操作符绝大多数和Java一样,
数据类型:
1 | 基础类型 类型说明 |
与java的区别:
1scala中所有的类型都使用大写字母开头
2 整形使用 Int 而不是Integer
3 scala中定义变量可以不写类型,让scala编译器自动推断
运算符
1 | 类别 操作符 |
1 | 与java的异同: |
例子:
1 | var a="aa" |
scala的类型层次结构
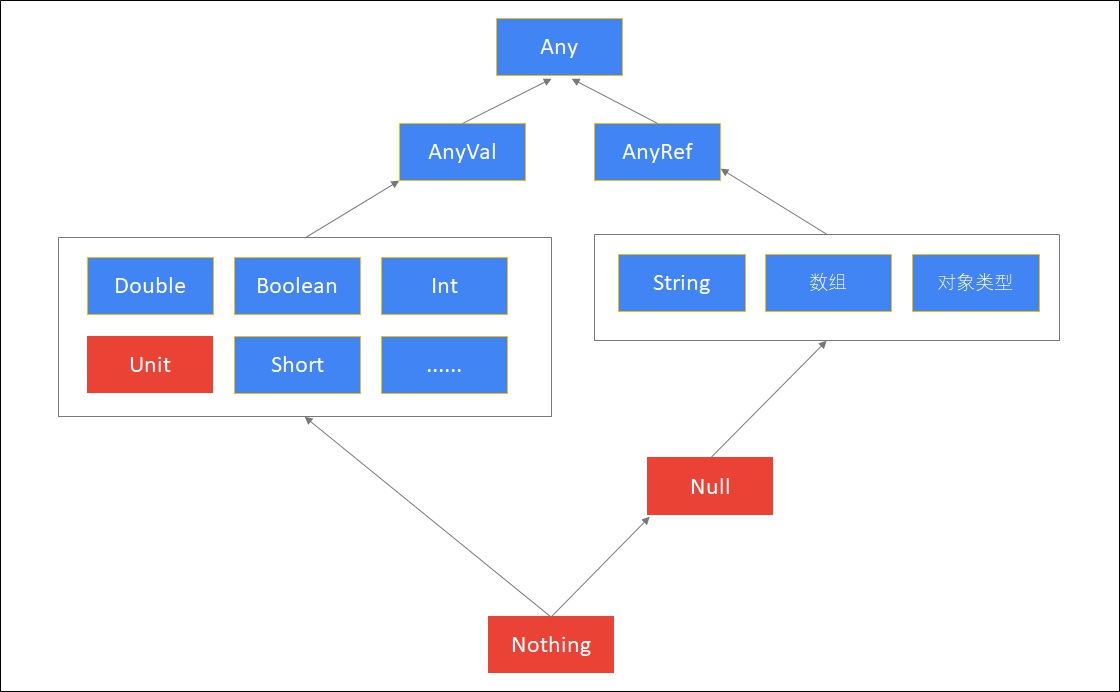
1 | 说明 |
noting 例子:
1 | def main(args: Array[String]): Unit = { |
1 | val b:Int = null 会报错 null不属于Int的子类 |
六 条件,循环表达式
1 if语句
语法与java一样
不一样的是:
在scala中,条件表达式也是有返回值的
在scala中,没有三元表达式,可以使用if表达式替代三元表达式
1 | val sex = "male" |
2 块表达式
scala中,使用{}表示一个块表达式
和if表达式一样,块表达式也是有值的
值就是最后一个表达式的值
1 | var a={ |
3 循环
语法:
1 | for(i <- 表达式/数组/集合) { |
循环打印1到10
1 | var nums=1.to(10) |
嵌套循环:
1 | for (i <- 1 to 10;j <- 1 to 3){ |
守卫:
for表达式中,可以添加if判断语句,这个if判断就称之为守卫。我们可以使用守卫让for表达式更简
洁。
语法:
1 | for(i <- 表达式/数组/集合 if 表达式) { |
1 | // 添加守卫,打印能够整除3的数字 |
for推导式:
将来可以使用for推导式生成一个新的集合(一组数据)
在for循环体中,可以使用yield表达式构建出一个集合,我们把使用yield的for表达式称之为推
导式
生成一个10,20…..100的集合
1 | // for推导式:for表达式中以yield开始,该for表达式会构建出一个集合 |
while循环
语法与java中一致
打印1到10
1 | scala> var i = 1 |
七 方法
一个类可以有自己的方法,scala中的方法和Java方法类似。但scala与Java定义方法的语法是不一
样的,而且scala支持多种调用方式。
1 定义方法
1 | def add(参数名:参数类型,参数名:参数类型): [返回值类型 return type] ={ |
参数列表的参数类型不能省略
返回值类型可以省略
返回值可以不写return,默认就是{}块表达式的值
定方法:实现两数相加:
1 | def add(a:Int,b:Int):Int ={ |
2 方法参数:
scala中的方法参数,使用比较灵活。它支持以下几种类型的参数:
默认参数
带名参数
变长参数
默认参数
在定义方法时可以给参数定义一个默认值。
1 | def add(a:Int =1,b:Int = 2): Int = a+b |
带名参数
在调用方法时,可以指定参数的名称来进行调用。
1 | def add(a:Int =1,b:Int = 2): Int = a+b |
变长参数
如果方法的参数是不固定的,可以定义一个方法的参数是变长参数。
1 | def add (num:Int*)=num.sum |
在参数类型后面加一个 * 号,表示参数可以是0个或者多个
3 方法返回值类型推断
scala定义方法可以省略返回值,由scala自动推断返回值类型。这样方法定义后更加简洁。
1 | def add(x:Int, y:Int) = x + y |
定义递归返回,不能省略返回值
1 |
4 方法调用方式
在scala中,有以下几种方法调用方式,
后缀调用法
中缀调用法
花括号调用法
无括号调用法
在spark、flink程序时,使用到这些方法。
后缀调用:
1 | 对象名.方法名(参数) |
中缀调用
1 | 对象名 方法名 参数 若有多个参数用括号 |
操作符就是方法
1 | 1 + 1 与中缀 |
在scala中,+ - * / %等这些操作符和Java一样,但在scala中,
所有的操作符都是方法
操作符是一个方法名字是符号的方法
花括号调用发
语法
1 | Math.abs{ |
1 | Math.abs{ |
无括号调用发
如果方法没有参数,可以省略方法名后面的括号示例
定义一个无参数的方法,打印”hello”
使用无括号调用法调用该方法
参考代码
1 | def m3()=println("hello") |
八 函数
scala支持函数式编程,将来编写Spark/Flink程序中,会大量经常使用到函数
语法:
1 | val 函数变量名 = (参数名:参数类型, 参数名:参数类型....) => 函数体 |
1 | scala> val add = (x:Int, y:Int) => x + y |
1 | 方法和函数的区别 |
方法转换为函数
有时候需要将方法转换为函数,作为变量传递,就需要将方法转换为函数
使用 _ 即可将方法转换为函数
1 | scala> def add(x:Int,y:Int)=x+y |
九数组
scala中数组的概念是和Java类似,可以用数组来存放一组数据。scala中,有两种数组,一种是定
长数组,另一种是变长数组
定长数组
定长数组指的是数组的长度是不允许改变的
1 | // 通过指定长度定义数组 |
1 | scala> val a = new Array[Int](100) |
1 | // 定义包含jave、scala、python三个元素的数组 |
变长数组
变长数组指的是数组的长度是可变的,可以往数组中添加、删除元素
定义变长数组
语法
创建空的ArrayBuffer变长数组,语法结构:
1 | val/var a = ArrayBuffer[元素类型]() |
创建带有初始元素的ArrayBuffer
1 | val/var a = ArrayBuffer(元素1,元素2,元素3....) |
注意:
1 | 创建变长数组,需要提前导入ArrayBuffer类 import scala.collection.mutable.ArrayBuffer |
1 | val a = ArrayBuffer[Int]() 长度为0 |
1 | scala> val a = ArrayBuffer("hadoop", "storm", "spark") |
添加/修改/删除元素
使用 += 添加元素
使用 -= 删除元素
使用 ++= 追加一个数组到变长数组
示例
- 定义一个变长数组,包含以下元素: “hadoop”, “spark”, “flink”
- 往该变长数组添加一个”flume”元素
- 从该变长数组删除”hadoop”元素
- 再将一个数组,该数组包含”hive”, “sqoop”追加到变长数组中
1 | // 定义变长数组 |
遍历数组
可以使用以下两种方式来遍历数组:
使用 for表达式 直接遍历数组中的元素
使用 索引 遍历数组中的元素
1 | scala> val a = Array(1,2,3,4,5) |
1 | scala> val a = Array(1,2,3,4,5) |
注意:
1 | 0 until n——生成一系列的数字,包含0,不包含n |
数组常用算法:
scala中的数组封装了丰富的计算操作,将来在对数据处理的时候,不需要我们自己再重新实现。
以下为常用的几个算法:
求和——sum方法
求最大值——max方法
求最小值——min方法
排序——sorted方法
1 | scala> val a = Array(1,2,3,4) |
十 元组
元组
元组可以用来包含一组不同类型的值。例如:姓名,年龄,性别,出生年月。元组的元素是不可变
的。
语法:
1 | 使用括号来定义元组 |
1 | 例子 |
访问元组
使用_1,2,3…来访问元祖中的元素,1表示访问第一个元素,一次类推
1 | // 可以直接使用括号来定义一个元组 |
十一列表
列表
List是scala中最重要的、也是最常用的数据结构。List具备以下性质:
可以保存重复的值
有先后顺序
在scala中,也有两种列表,一种是不可变列表、另一种是可变列表
1 不可变列表
1 | 不可变列表就是列表的元素、长度都是不可变的。 |
例子:
1 | 示例一 |
2 可变列表
可变列表就是列表的元素、长度都是可变的。
要使用可变列表,先要导入 import scala.collection.mutable.ListBuffer
注意:
可变集合都在 mutable 包中
不可变集合都在 immutable 包中(默认导入)
1 | 初始化列表 |
1 | 例子: |
列表操作
获取元素(使用括号访问 (索引值) )
添加元素( += )
追加一个列表( ++= )
更改元素( 使用括号获取元素,然后进行赋值 )
删除元素( -= )
转换为List( toList )
转换为Array( toArray )
1 | // 导入不可变列表 |
列表操作
以下是列表常用的操作
判断列表是否为空( isEmpty )
拼接两个列表( ++ )
获取列表的首个元素( head )和剩余部分( tail )
反转列表( reverse )
获取前缀( take )、获取后缀( drop )
扁平化( flaten )
扁平化表示将列表中的列表中的所有元素放到一个列表中。
拉链( zip )和拉开( unzip )
转换字符串( toString )
生成字符串( mkString )
并集( union )
交集( intersect )
差集( diff )
例子:
1 | a.isEmpty |
1 | 扁平化表示将列表中的列表中的所有元素放到一个列表中。 |
1 | 拉链:使用zip将两个列表,组合成一个元素为元组的列表 |
1 | 转换字符串( toString ) |
1 | 并集 |
1 | 交集 |
1 | 差集 |
集 set
Set(集)是代表没有重复元素的集合。Set具备以下性质:
- 元素不重复
- 不保证插入顺序
scala中的集也分为两种,一种是不可变集,另一种是可变集。
不可变集
语法:
1 | val/var 变量名 = Set[类型]() |
给定元素来创建一个不可变集,语法格式:
1 | val/var 变量名 = Set(元素1, 元素2, 元素3...) |
操作:
1 | 获取集的大小(size) a.size |
可变集
可变集合不可变集的创建方式一致,只不过需要提前导入一个可变集类。
1 | import scala.collection.mutable.Set |
1 | scala> val a = Set(1,2,3,4) |
映射
Map可以称之为映射。它是由键值对组成的集合。在scala中,Map也分为不可变Map和可变Map。
不可变Map
语法:
1 | val/var map = Map(键->值, 键->值, 键->值...) // 推荐,可读性更好 |
可变Map
定义语法与不可变Map一致。但定义可变Map需要手动导入import scala.collection.mutable.Map
1 | val map = Map("zhangsan"->30, "lisi"->40) |
interator 迭代器
scala针对每一类集合都提供了一个迭代器(iterator)用来迭代访问集合
使用迭代器遍历集合
- 使用
iterator方法可以从集合获取一个迭代器 - 迭代器的两个基本操作
- hasNext——查询容器中是否有下一个元素
- next——返回迭代器的下一个元素,如果没有,抛出NoSuchElementException
- 每一个迭代器都是有状态的
- 迭代完后保留在最后一个元素的位置
- 再次使用则抛出NoSuchElementException
- 可以使用while或者for来逐个返回元素
例子:
1 | val ite = a.iterator |
函数式编程
我们将来使用Spark/Flink的大量业务代码都会使用到函数式编程。下面的这些操作是学习的重点。
遍历(
foreach)映射(
map)映射扁平化(
flatmap)过滤(
filter)是否存在(
exists)排序(
sorted、sortBy、sortWith)分组(
groupBy)聚合计算(
reduce)折叠(
fold)
可以使用类型推断简化函数定义
- scala可以自动来推断出来集合中每个元素参数的类型
- 创建函数时,可以省略其参数列表的类型
使用下划线简化函数定义
函数参数,只在函数体中出现一次,而且函数体没有嵌套调用时,可以使用下划线来简化函数定义
如果方法参数是函数,如果出现了下划线,scala编译器会自动将代码封装到一个函数中
参数列表也是由scala编译器自动处理
1 遍历
1 | val a = List(1,2,3,4) |
2 映射
集合的映射操作是将来在编写Spark/Flink用得最多的操作,是我们必须要掌握的。因为进行数据计算的时候,就是一个将一种数据类型转换为另外一种数据类型的过程。
map方法接收一个函数,将这个函数应用到每一个元素,返回一个新的列表
用法:
1 | def map[B](f: (A) ⇒ B): TraversableOnce[B] |
| map方法 | API | 说明 |
|---|---|---|
| 泛型 | [B] | 指定map方法最终返回的集合泛型 |
| 参数 | f: (A) ⇒ B | 传入一个函数对象 该函数接收一个类型A(要转换的列表元素),返回值为类型B |
| 返回值 | TraversableOnce[B] | B类型的集合 |
例:
1 | var a=List(1,2,3,4) |
1 | val a = List(1,2,3,4) |
3 扁平化映射
扁平化映射也是将来用得非常多的操作,也是必须要掌握的。
定义
1 | 可以把flatMap,理解为先map,然后再flatten |
方法签名:
1 | def flatMap[B](f: (A) ⇒ GenTraversableOnce[B]): TraversableOnce[B] |
| flatmap方法 | API | 说明 |
|---|---|---|
| 泛型 | [B] | 最终要转换的集合元素类型 |
| 参数 | f: (A) ⇒ GenTraversableOnce[B] | 传入一个函数对象 函数的参数是集合的元素 函数的返回值是一个集合 |
| 返回值 | TraversableOnce[B] | B类型的集合 |
案例说明
- 有一个包含了若干个文本行的列表:”hadoop hive spark flink flume”, “kudu hbase sqoop storm”
- 获取到文本行中的每一个单词,并将每一个单词都放到列表中
1 | // 定义文本行列表 |
使用flatMap简化操作
1 | scala> val a = List("hadoop hive spark flink flume", "kudu hbase sqoop storm") |
4 过滤
过滤符合一定条件的元素
1 | def filter(p: (A) ⇒ Boolean): TraversableOnce[A] |
| filter方法 | API | 说明 |
|---|---|---|
| 参数 | p: (A) ⇒ Boolean | 传入一个函数对象 接收一个集合类型的参数 返回布尔类型,满足条件返回true, 不满足返回false |
| 返回值 | TraversableOnce[A] | 列表 |
1 | //过滤偶数 结果得到的权威偶数 |
5 排序
在scala集合中,可以使用以下几种方式来进行排序
- sorted默认排序
- sortBy指定字段排序
- sortWith自定义排序
1 | //默认排序 |
指定字段排序
1 | def sortBy[B](f: (A) ⇒ B): List[A] |
| sortBy方法 | API | 说明 |
|---|---|---|
| 泛型 | [B] | 按照什么类型来进行排序 |
| 参数 | f: (A) ⇒ B | 传入函数对象 接收一个集合类型的元素参数 返回B类型的元素进行排序 |
| 返回值 | List[A] | 返回排序后的列表 |
1 | val a = List("01 hadoop", "02 flume", "03 hive", "04 spark") |
自定义排序
自定义排序,根据一个函数来进行自定义排序
方法签名
1 | def sortWith(lt: (A, A) ⇒ Boolean): List[A] |
| sortWith方法 | API | 说明 |
|---|---|---|
| 参数 | lt: (A, A) ⇒ Boolean | 传入一个比较大小的函数对象 接收两个集合类型的元素参数 返回两个元素大小,小于返回true,大于返回false |
| 返回值 | List[A] | 返回排序后的列表 |
1 | scala> val a = List(2,3,1,6,4,5) |
使用下划线简写上述案例
1 | scala> val a = List(2,3,1,6,4,5) |
分组
我们如果要将数据按照分组来进行统计分析,就需要使用到分组方法
groupBy表示按照函数将列表分成不同的组
1 | //方法签名 |
| groupBy方法 | API | 说明 |
|---|---|---|
| 泛型 | [K] | 分组字段的类型 |
| 参数 | f: (A) ⇒ K | 传入一个函数对象 接收集合元素类型的参数 返回一个K类型的key,这个key会用来进行分组,相同的key放在一组中 |
| 返回值 | Map[K, List[A]] | 返回一个映射,K为分组字段,List为这个分组字段对应的一组数据 |
有一个列表,包含了学生的姓名和性别:
1
2
3"张三", "男"
"李四", "女"
"王五", "男"请按照性别进行分组,统计不同性别的学生人数
1 | scala> val a = List("张三"->"男", "李四"->"女", "王五"->"男") |
聚合
聚合操作,可以将一个列表中的数据合并为一个。这种操作经常用来统计分析中
reduce表示将列表,传入一个函数进行聚合计算
方法签名
1 | def reduce[A1 >: A](op: (A1, A1) ⇒ A1): A1 |
| reduce方法 | API | 说明 |
|---|---|---|
| 泛型 | [A1 >: A] | (下界)A1必须是集合元素类型的父类 |
| 参数 | op: (A1, A1) ⇒ A1 | 传入函数对象,用来不断进行聚合操作 第一个A1类型参数为:当前聚合后的变量 第二个A1类型参数为:当前要进行聚合的元素 |
| 返回值 | A1 | 列表最终聚合为一个元素 |
注意:
- reduce和reduceLeft效果一致,表示从左到右计算
- reduceRight表示从右到左计算
- 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10
- 使用reduce计算所有元素的和
1 | scala> val a = List(1,2,3,4,5,6,7,8,9,10) |
折叠
fold与reduce很像,但是多了一个指定初始值参数
方法签名
1 | def fold[A1 >: A](z: A1)(op: (A1, A1) ⇒ A1): A1 |
| reduce方法 | API | 说明 |
|---|---|---|
| 泛型 | [A1 >: A] | (下界)A1必须是集合元素类型的父类 |
| 参数1 | z: A1 | 初始值 |
| 参数2 | op: (A1, A1) ⇒ A1 | 传入函数对象,用来不断进行折叠操作 第一个A1类型参数为:当前折叠后的变量 第二个A1类型参数为:当前要进行折叠的元素 |
| 返回值 | A1 | 列表最终折叠为一个元素 |
注意:
- fold和foldLet效果一致,表示从左往右计算
- foldRight表示从右往左计算
- 定义一个列表,包含以下元素:1,2,3,4,5,6,7,8,9,10
- 使用fold方法计算所有元素的和
1 | scala> val a = List(1,2,3,4,5,6,7,8,9,10) |