#一 Lucene
全文检索:
索引&检索
倒排索引 :
1我是中国人
2 中国是全球人口最多的国家 ,中国人也最多
例如这两句 用 倒排索引
1,我 (1:1){0} 第一个1 为第一行 第二个1 为个数 0 为行偏移量
2,中国 (1:1) {2},(2:2){0,15}
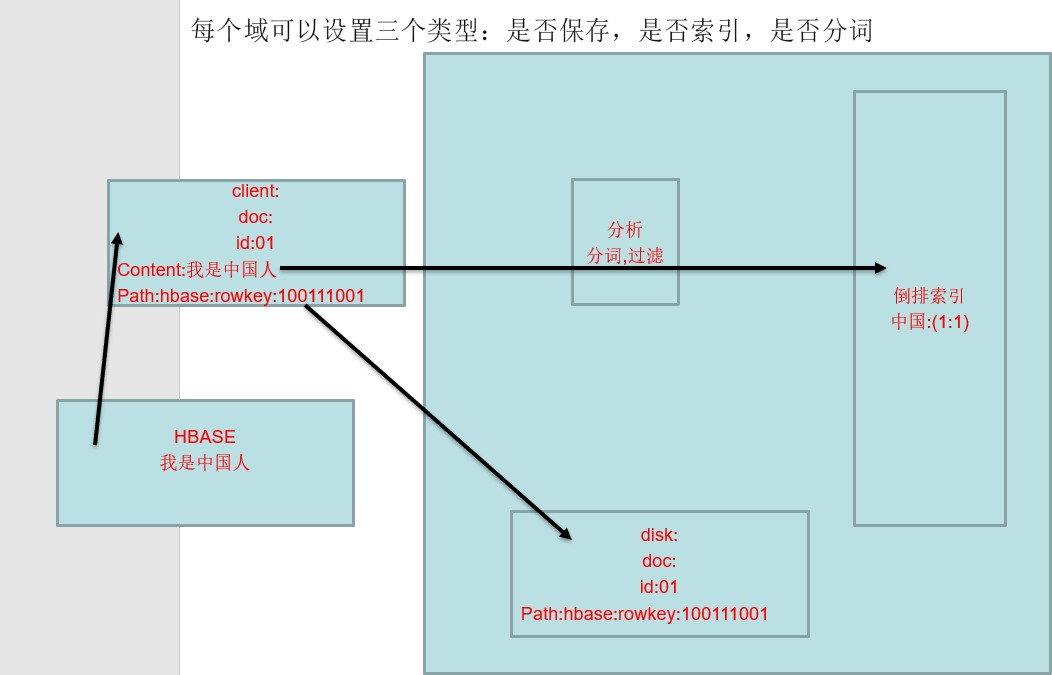
#二 es 概述
全称 Elastic Search 基于Lucene ES只是封装了Lucene es 制定了一套规则 ,发送给我的数据只要满足一定的格式即可,而不管你的数据来源,只要满足这个规则es就可以对其进行操作.
Elastic有一条完整的产品线及解决方案:Elasticsearch、Kibana、Logstash等,前面说的三个就是大家常说的ELK技术栈。
##1特点
- 分布式,无需人工搭建集群(solr就需要人为配置,使用Zookeeper作为注册中心)
- Restful风格,一切API都遵循Rest原则,容易上手
- 近实时搜索,数据更新在Elasticsearch中几乎是完全同步的。
2原理与应用
1.2.1索引结构
下图是ElasticSearch的索引结构,下边黑色部分是物理结构,上边黄色部分是逻辑结构,逻辑结构也是为了更好的去描述ElasticSearch的工作原理及去使用物理结构中的索引文件。

逻辑结构部分是一个倒排索引表:
1、将要搜索的文档内容分词,所有不重复的词组成分词列表。
2、将搜索的文档最终以Document方式存储起来。
3、每个词和docment都有关联。
如下:
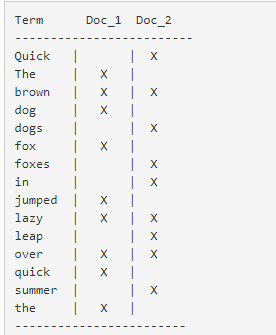
现在,如果我们想搜索 quick brown ,我们只需要查找包含每个词条的文档:

两个文档都匹配,但是第一个文档比第二个匹配度更高。如果我们使用仅计算匹配词条数量的简单 相似性算法 ,那么,我们可以说,对于我们查询的相关性来讲,第一个文档比第二个文档更佳。
3 RESTful应用方法
Elasticsearch提供 RESTful Api接口进行索引、搜索,并且支持多种客户端。
es在项目中的应用:
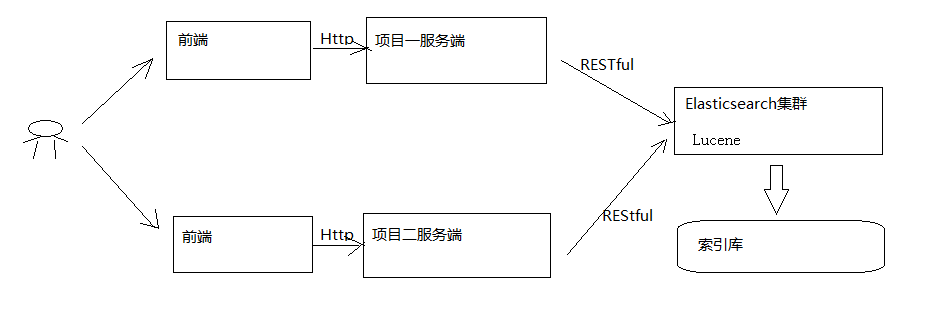
- 用户在前端搜索关键字
2)项目前端通过http方式请求项目服务端
3)项目服务端通过Http RESTful方式请求ES集群进行搜索
4)ES集群从索引库检索数据。
三 安装与部署 集群
1 新建用户
出于安全考虑,elasticsearch默认不允许以root账号运行。
1 | useradd es |
2 上传压塑包并解压
1 | tar -zxvf elasticsearch-6.2.4.tar.gz |
3 修改配置文件
要修改两个配置文件在 config目录下
1 | cd config |
elasticsearch.yml和jvm.options
3.1 修改jvm.options
Elasticsearch基于Lucene的,而Lucene底层是java实现,因此我们需要配置jvm参数。
编辑jvm.options:
1 | vim jvm.options |
3.2 修改elasticsearch.yml
1 | vim elasticsearch.yml |
修改数据和日志目录:
1 | path.data: /export/server/elasticsearch/data # 数据目录位置 |
我们把data和logs目录修改指向了elasticsearch的安装目录。但是这两个目录并不存在,因此我们需要创建出来。
进入elasticsearch的根目录,然后创建:
1 | mkdir data |
修改绑定的ip:
1 | network.host: 0.0.0.0 # 绑定到0.0.0.0,允许任何ip来访问 |
默认只允许本机访问,修改为0.0.0.0后则可以远程访问
这个是做的单机安装,如果要做集群,只需要在这个配置文件中添加其它节点信息即可。
elasticsearch.ym文件中的其他配置
| 属性名 | 说明 |
|---|---|
| cluster.name | 配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。 |
| node.name | 节点名,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理 |
| path.conf | 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch |
| path.data | 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开 |
| path.logs | 设置日志文件的存储路径,默认是es根目录下的logs文件夹 |
| path.plugins | 设置插件的存放路径,默认是es根目录下的plugins文件夹 |
| bootstrap.memory_lock | 设置为true可以锁住ES使用的内存,避免内存进行swap |
| network.host | 设置bind_host和publish_host,设置为0.0.0.0允许外网访问 |
| http.port | 设置对外服务的http端口,默认为9200。 |
| transport.tcp.port | 集群结点之间通信端口 |
| discovery.zen.ping.timeout | 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些 |
| discovery.zen.minimum_master_nodes | 主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2 |
cluster.name:
配置elasticsearch的集群名称,默认是elasticsearch。建议修改成一个有意义的名称。
node.name:
节点名,通常一台物理服务器就是一个节点,es会默认随机指定一个名字,建议指定一个有意义的名称,方便管理
一个或多个节点组成一个cluster集群,集群是一个逻辑的概念,节点是物理概念,后边章节会详细介绍。
path.conf: 设置配置文件的存储路径,tar或zip包安装默认在es根目录下的config文件夹,rpm安装默认在/etc/ elasticsearch
path.data: 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开。 path.logs: 设置日志文件的存储路径,默认是es根目录下的logs文件夹
path.plugins: 设置插件的存放路径,默认是es根目录下的plugins文件夹
bootstrap.memory_lock: true 设置为true可以锁住ES使用的内存,避免内存与swap分区交换数据。
network.host: 设置绑定主机的ip地址,设置为0.0.0.0表示绑定任何ip,允许外网访问,生产环境建议设置为具体的ip。 http.port: 9200 设置对外服务的http端口,默认为9200。
transport.tcp.port: 9300 集群结点之间通信端口
node.master: 指定该节点是否有资格被选举成为master结点,默认是true,如果原来的master宕机会重新选举新的master。
node.data: 指定该节点是否存储索引数据,默认为true。
discovery.zen.ping.unicast.hosts: [“host1:port”, “host2:port”, “…”] 设置集群中master节点的初始列表。
discovery.zen.ping.timeout: 3s 设置ES自动发现节点连接超时的时间,默认为3秒,如果网络延迟高可设置大些。 discovery.zen.minimum_master_nodes:
主结点数量的最少值 ,此值的公式为:(master_eligible_nodes / 2) + 1 ,比如:有3个符合要求的主结点,那么这里要设置为2。
node.max_local_storage_nodes:
单机允许的最大存储结点数,通常单机启动一个结点建议设置为1,开发环境如果单机启动多个节点可设置大于1.