#一 Spark 概述
##1 什么是Spark
Apache Spark 是一个快速的, 多用途的集群计算系统, 相对于 Hadoop MapReduce 将中间结果保存在磁盘中, Spark 使用了内存保存中间结果, 能在数据尚未写入硬盘时在内存中进行运算.
Spark 只是一个计算框架, 不像 Hadoop 一样包含了分布式文件系统和完备的调度系统, 如果要使用 Spark, 需要搭载其它的文件系统和更成熟的调度系统
Spark 产生之前, 已经有非常成熟的计算系统存在了, 例如 MapReduce, 这些计算系统提供了高层次的API, 把计算运行在集群中并提供容错能力, 从而实现分布式计算.
虽然这些框架提供了大量的对访问利用计算资源的抽象, 但是它们缺少了对利用分布式内存的抽象, 这些框架多个计算之间的数据复用就是将中间数据写到一个稳定的文件系统中(例如HDFS), 所以会产生数据的复制备份, 磁盘的I/O以及数据的序列化, 所以这些框架在遇到需要在多个计算之间复用中间结果的操作时会非常的不高效.
而这类操作是非常常见的, 例如迭代式计算, 交互式数据挖掘, 图计算等.
认识到这个问题后, 学术界的 AMPLab 提出了一个新的模型, 叫做 RDDs.
RDDs 是一个可以容错且并行的数据结构, 它可以让用户显式的将中间结果数据集保存在内中, 并且通过控制数据集的分区来达到数据存放处理最优化.
同时 RDDs 也提供了丰富的 API 来操作数据集.
后来 RDDs 被 AMPLab 在一个叫做 Spark 的框架中提供并开源.
mr 的问题
1 计算过程比较缓慢,不适应与交互式计算,和迭代计算
2 不是所有的计算都由Map和Reduce两个阶段组成
spark解决问题
1 第一个问题 解决 中间结果存在内存中
2 提供了更好的API 函数式
##2 spark特点
速度快
Spark 的在内存时的运行速度是 Hadoop MapReduce 的100倍基于硬盘的运算速度大概是 Hadoop MapReduce 的10倍Spark 实现了一种叫做 RDDs 的 DAG 执行引擎, 其数据缓存在内存中可以进行迭代处理
易用
1
2
3
4df = spark.read.json("logs.json")
df.where("age > 21") \
.select("name.first") \
.show()- Spark 支持 Java, Scala, Python, R, SQL 等多种语言的API.
- Spark 支持超过80个高级运算符使得用户非常轻易的构建并行计算程序
- Spark 可以使用基于 Scala, Python, R, SQL的 Shell 交互式查询.
通用
Spark 提供一个完整的技术栈, 包括 SQL执行, Dataset命令式API, 机器学习库MLlib, 图计算框架GraphX, 流计算SparkStreaming用户可以在同一个应用中同时使用这些工具, 这一点是划时代的
兼容
Spark 可以运行在 Hadoop Yarn, Apache Mesos, Kubernets, Spark Standalone等集群中Spark 可以访问 HBase, HDFS, Hive, Cassandra 在内的多种数据库
总结
- 支持 Java, Scala, Python 和 R 的 API
- 可扩展至超过 8K 个节点
- 能够在内存中缓存数据集, 以实现交互式数据分析
- 提供命令行窗口, 减少探索式的数据分析的反应时间
3 spark组件
Spark 最核心的功能是 RDDs, RDDs 存在于 spark-core 这个包内, 这个包也是 Spark 最核心的包.
同时 Spark 在 spark-core 的上层提供了很多工具, 以便于适应不用类型的计算.
Spark-Core 和 弹性分布式数据集(RDDs)
Spark-Core 是整个 Spark 的基础, 提供了分布式任务调度和基本的 I/O 功能Spark 的基础的程序抽象是弹性分布式数据集(RDDs), 是一个可以并行操作, 有容错的数据集合RDDs 可以通过引用外部存储系统的数据集创建(如HDFS, HBase), 或者通过现有的 RDDs 转换得到RDDs 抽象提供了 Java, Scala, Python 等语言的APIRDDs 简化了编程复杂性, 操作 RDDs 类似通过 Scala 或者 Java8 的 Streaming 操作本地数据集合
Spark SQL
Spark SQL 在
spark-core基础之上带出了一个名为 DataSet 和 DataFrame 的数据抽象化的概念Spark SQL 提供了在 Dataset 和 DataFrame 之上执行 SQL 的能力Spark SQL 提供了 DSL, 可以通过 Scala, Java, Python 等语言操作 DataSet 和 DataFrame它还支持使用 JDBC/ODBC 服务器操作 SQL 语言Spark Streaming
Spark Streaming 充分利用
spark-core的快速调度能力来运行流分析它截取小批量的数据并可以对之运行 RDD Transformation它提供了在同一个程序中同时使用流分析和批量分析的能力MLlib
MLlib 是 Spark 上分布式机器学习的框架. Spark分布式内存的架构 比 Hadoop磁盘式 的 Apache Mahout 快上 10 倍, 扩展性也非常优良MLlib 可以使用许多常见的机器学习和统计算法, 简化大规模机器学习汇总统计, 相关性, 分层抽样, 假设检定, 随即数据生成支持向量机, 回归, 线性回归, 逻辑回归, 决策树, 朴素贝叶斯协同过滤, ALSK-meansSVD奇异值分解, PCA主成分分析TF-IDF, Word2Vec, StandardScalerSGD随机梯度下降, L-BFGS
GraphX
GraphX 是分布式图计算框架, 提供了一组可以表达图计算的 API, GraphX 还对这种抽象化提供了优化运行
总结
- Spark 提供了 批处理(RDDs), 结构化查询(DataFrame), 流计算(SparkStreaming), 机器学习(MLlib), 图计算(GraphX) 等组件
- 这些组件均是依托于通用的计算引擎 RDDs 而构建出的, 所以
spark-core的 RDDs 是整个 Spark 的基础
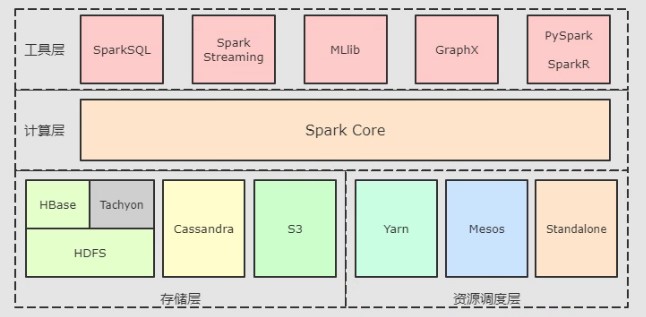
Spark和Hadoop的异同
| Hadoop | Spark | |
|---|---|---|
| 类型 | 基础平台, 包含计算, 存储, 调度 | 分布式计算工具 |
| 场景 | 大规模数据集上的批处理 | 迭代计算, 交互式计算, 流计算 |
| 延迟 | 大 | 小 |
| 易用性 | API 较为底层, 算法适应性差 | API 较为顶层, 方便使用 |
| 价格 | 对机器要求低, 便宜 | 对内存有要求, 相对较贵 |
二 集群搭建
1 spark集群结构
Spark 自身是没有集群管理工具的, 但是如果想要管理数以千计台机器的集群, 没有一个集群管理工具还不太现实, 所以 Spark 可以借助外部的集群工具来进行管理
整个流程就是使用 Spark 的 Client 提交任务, 找到集群管理工具申请资源, 后将计算任务分发到集群中运行
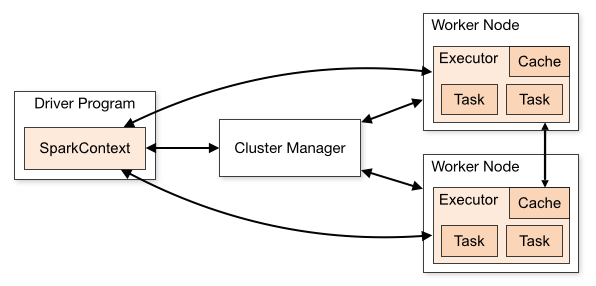
名词解释
Driver该进程调用 Spark 程序的 main 方法, 并且启动 SparkContext
Cluster Manager该进程负责和外部集群工具打交道, 申请或释放集群资源
Worker该进程是一个守护进程, 负责启动和管理 Executor
Executor该进程是一个JVM虚拟机, 负责运行 Spark Task
运行一个 Spark 程序大致经历如下几个步骤
- 启动 Drive, 创建 SparkContext
- Client 提交程序给 Drive, Drive 向 Cluster Manager 申请集群资源
- 资源申请完毕, 在 Worker 中启动 Executor
- Driver 将程序转化为 Tasks, 分发给 Executor 执行
Spark 程序可以运行在什么地方?
- 集群: 一组协同工作的计算机, 通常表现的好像是一台计算机一样, 所运行的任务由软件来控制和调度
- 集群管理工具: 调度任务到集群的软件
- 常见的集群管理工具: Hadoop Yarn, Apache Mesos, Kubernetes
Spark 可以将任务运行在两种模式下:
- 单机, 使用线程模拟并行来运行程序
- 集群, 使用集群管理器来和不同类型的集群交互, 将任务运行在集群中
Spark 可以使用的集群管理工具有:
- Spark Standalone
- Hadoop Yarn
- Apache Mesos
- Kubernetes
Driver 和 Worker 什么时候被启动?
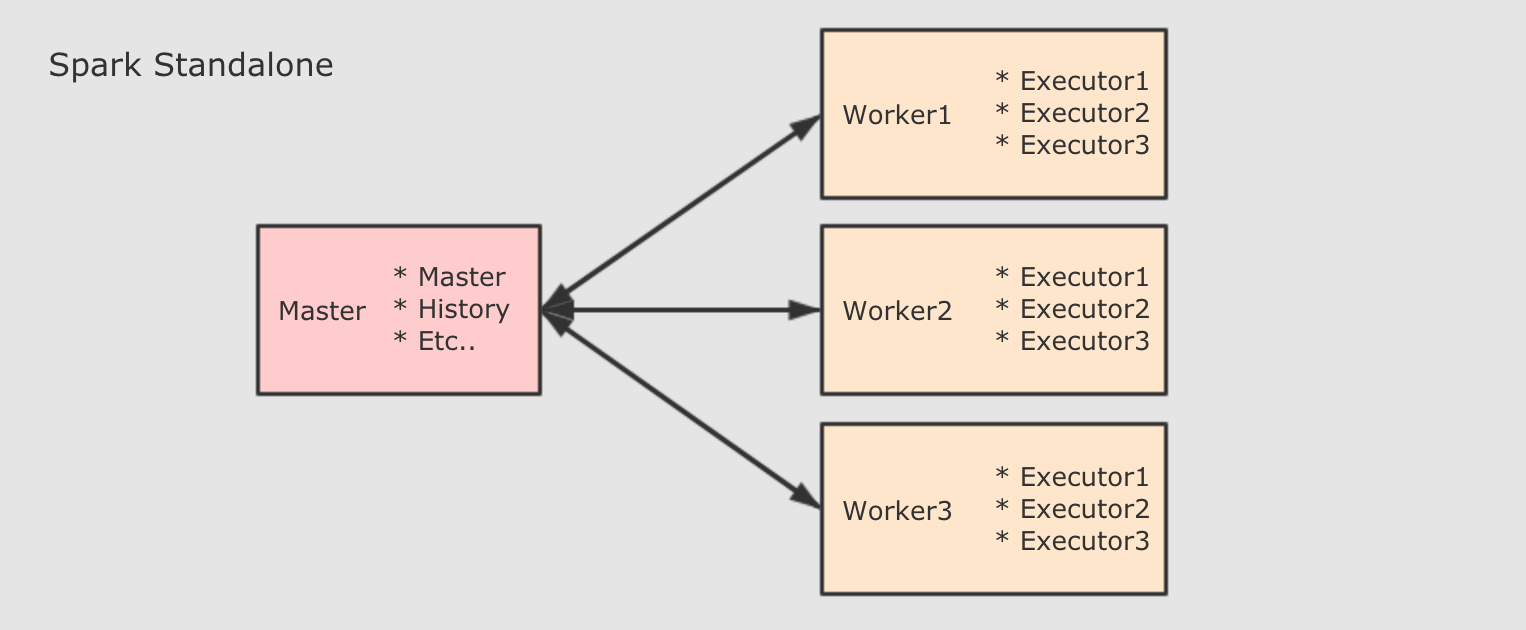
- Standalone 集群中, 分为两个角色: Master 和 Slave, 而 Slave 就是 Worker, 所以在 Standalone 集群中, 启动之初就会创建固定数量的 Worker
- Driver 的启动分为两种模式: Client 和 Cluster. 在 Client 模式下, Driver 运行在 Client 端, 在 Client 启动的时候被启动. 在 Cluster 模式下, Driver 运行在某个 Worker 中, 随着应用的提交而启动
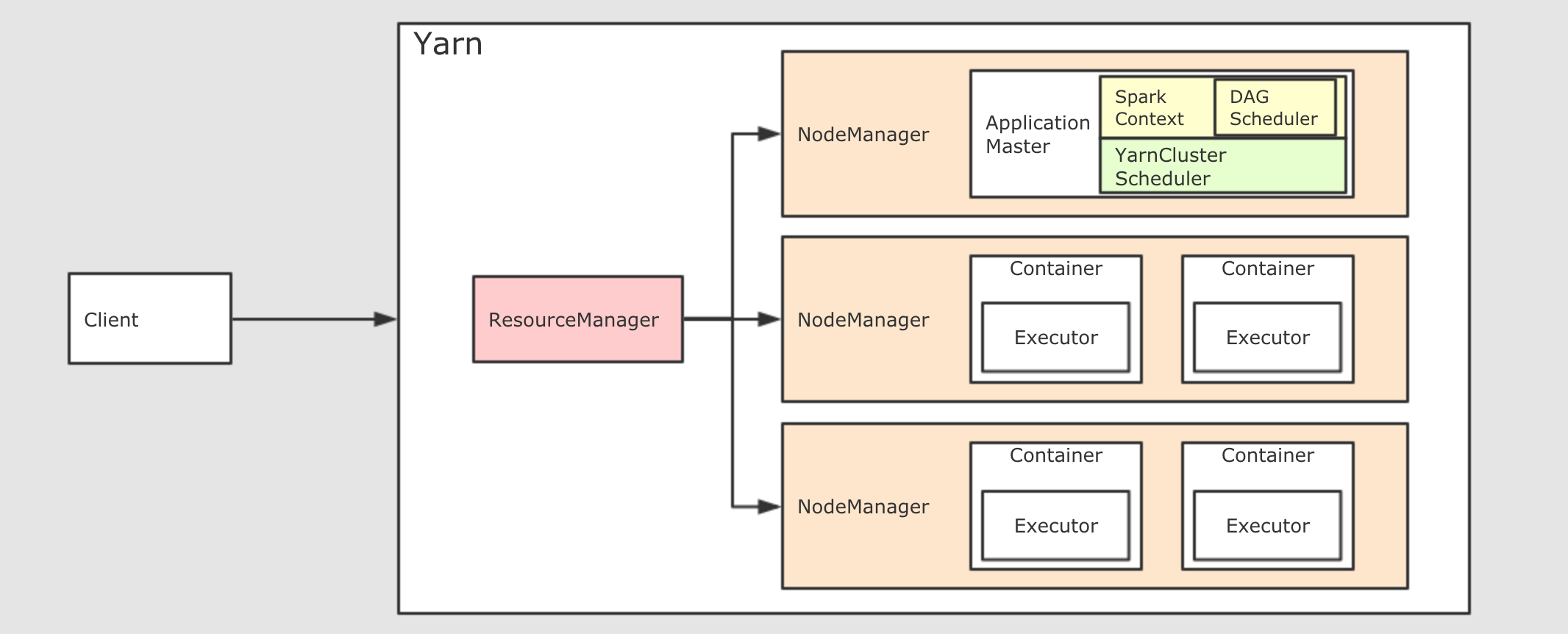
- 在 Yarn 集群模式下, 也依然分为 Client 模式和 Cluster 模式, 较新的版本中已经逐渐在废弃 Client 模式了, 所以上图所示为 Cluster 模式
- 如果要在 Yarn 中运行 Spark 程序, 首先会和 RM 交互, 开启 ApplicationMaster, 其中运行了 Driver, Driver创建基础环境后, 会由 RM 提供对应的容器, 运行 Executor, Executor会反向向 Driver 反向注册自己, 并申请 Tasks 执行
总结
Master负责总控, 调度, 管理和协调 Worker, 保留资源状况等Slave对应 Worker 节点, 用于启动 Executor 执行 Tasks, 定期向 Master汇报Driver运行在 Client 或者 Slave(Worker) 中, 默认运行在 Slave(Worker) 中
2 集群搭建
集群规划
| Node01 | Node02 | Node03 |
|---|---|---|
| Master | Slave | Slave |
| History Server |
2.1 下载解压
1 | 网址 |
1 | 上传解压 |
解压后改名为spark
修改配置文件spark-env.sh, 以指定运行参数
进入配置目录, 并复制一份新的配置文件, 以供在此基础之上进行修改
1
2
3cd /export/servers/spark/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.sh将以下内容复制进配置文件末尾
1
2
3
4
5
6# 指定 Java Home
export JAVA_HOME=/export/servers/jdk1.8.0_141
# 指定 Spark Master 地址
export SPARK_MASTER_HOST=node01
export SPARK_MASTER_PORT=7077
2.2 配置
修改配置文件
slaves, 以指定从节点为止, 从在使用sbin/start-all.sh启动集群的时候, 可以一键启动整个集群所有的 Worker进入配置目录, 并复制一份新的配置文件, 以供在此基础之上进行修改
1
2
3cd /export/servers/spark/conf
cp slaves.template slaves
vi slaves配置所有从节点的地址
1
2node02
node03
配置
HistoryServer默认情况下, Spark 程序运行完毕后, 就无法再查看运行记录的 Web UI 了, 通过 HistoryServer 可以提供一个服务, 通过读取日志文件, 使得我们可以在程序运行结束后, 依然能够查看运行过程
复制
spark-defaults.conf, 以供修改1
2
3cd /export/servers/spark/conf
cp spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf将以下内容复制到
spark-defaults.conf末尾处, 通过这段配置, 可以指定 Spark 将日志输入到 HDFS 中1
2
3spark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/spark_log
spark.eventLog.compress true将以下内容复制到
spark-env.sh的末尾, 配置 HistoryServer 启动参数, 使得 HistoryServer 在启动的时候读取 HDFS 中写入的 Spark 日志1
2# 指定 Spark History 运行参数
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"为 Spark 创建 HDFS 中的日志目录
1
hdfs dfs -mkdir -p /spark_log
2.3 分发运行
将 Spark 安装包分发给集群中其它机器
1
2
3cd /export/servers
scp -r spark/ node03:$PWD
scp -r spark/ node02:$PWD启动 Spark Master 和 Slaves, 以及 HistoryServer
1
2
3cd /export/servers/spark
sbin/start-all.sh
sbin/start-history-server.sh
3 spark集群高可用搭建
了解如何使用 Zookeeper 帮助 Spark Standalone 高可用
对于 Spark Standalone 集群来说, 当 Worker 调度出现问题的时候, 会自动的弹性容错, 将出错的 Task 调度到其它 Worker 执行
但是对于 Master 来说, 是会出现单点失败的, 为了避免可能出现的单点失败问题, Spark 提供了两种方式满足高可用
- 使用 Zookeeper 实现 Masters 的主备切换
- 使用文件系统做主备切换
使用文件系统做主备切换的场景实在太小, 所以此处不做探讨
3.1 停止spark集群
1 | cd /export/servers/spark |
3.2 修改配置文件, 增加 Spark 运行时参数, 从而指定 Zookeeper 的位置
进入
spark-env.sh所在目录, 打开 vi 编辑1
2cd /export/servers/spark/conf
vi spark-env.sh编辑
spark-env.sh, 添加 Spark 启动参数, 并去掉 SPARK_MASTER_HOST 地址
1 | # 指定 Java Home |
3.3 分发配置文件到整个集群
1 | cd /export/servers/spark/conf |
3.4 启动
在
node01上启动整个集群1
2
3cd /export/servers/spark
sbin/start-all.sh
sbin/start-history-server.sh在
node02上单独再启动一个 Master1
2cd /export/servers/spark
sbin/start-master.sh
3.5 查看 node01 master 和 node02 master 的 WebUI
你会发现一个是 ALIVE(主), 另外一个是 STANDBY(备)
如果关闭一个, 则另外一个成为ALIVE, 但是这个过程可能要持续两分钟左右, 需要耐心等待
1 | 在 Node01 中执行如下指令 |
Spark HA 选举
Spark HA 的 Leader 选举使用了一个叫做 Curator 的 Zookeeper 客户端来进行
Zookeeper 是一个分布式强一致性的协调服务, Zookeeper 最基本的一个保证是: 如果多个节点同时创建一个 ZNode, 只有一个能够成功创建. 这个做法的本质使用的是 Zookeeper 的 ZAB 协议, 能够在分布式环境下达成一致.
spark各服务端口
| Service | port |
|---|---|
| Master WebUI | node01:8080 |
| Worker WebUI | node01:8081 |
| History Server | node01:4000 |
4 第一个应用程序
流程:
Step 1 进入 Spark 安装目录中
1 | cd /export/servers/spark/ |
Step 2 运行 Spark 示例任务
1 | bin/spark-submit \ |
Step 3 运行结果
1 | Pi is roughly 3.1424627142462715 |
刚才所运行的程序是 Spark 的一个示例程序, 使用 Spark 编写了一个以蒙特卡洛算法来计算圆周率的任务
- 蒙特卡洛算法概述
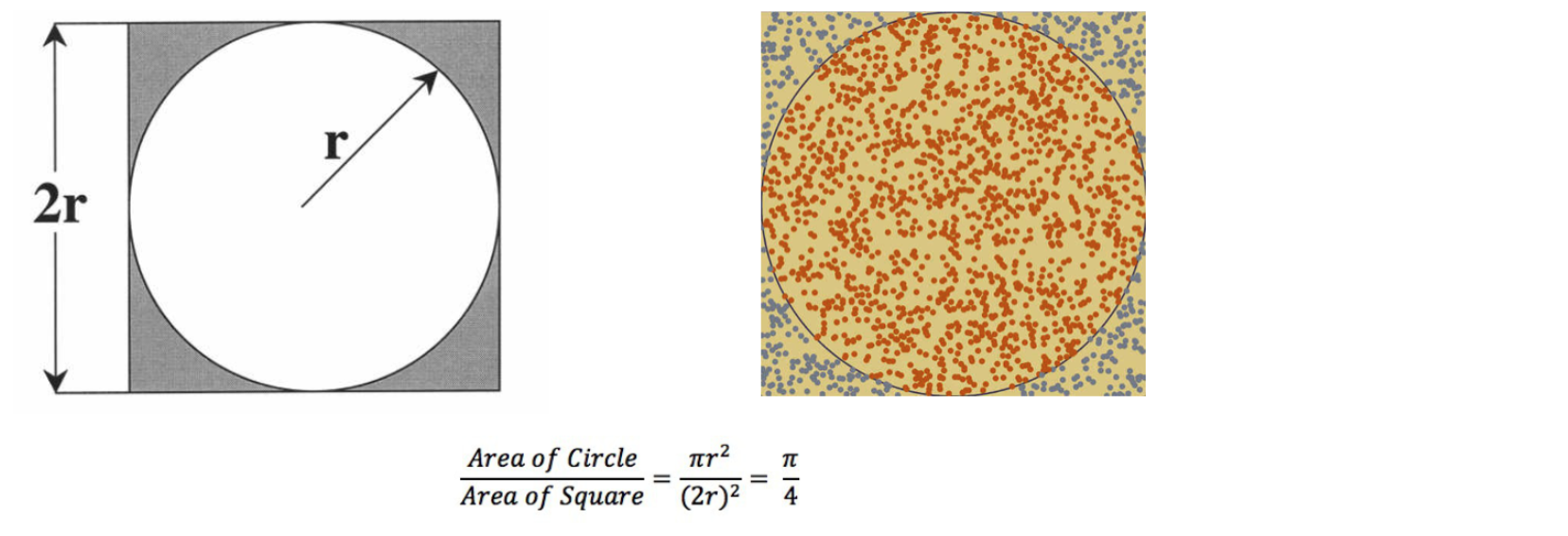
通过迭代循环投点的方式实现蒙特卡洛算法求圆周率
计算过程
1不断的生成随机的点, 根据点距离圆心是否超过半径来判断是否落入园内
2通过 来计算圆周率
3不断的迭代
三 spark入门
Spark 官方提供了两种方式编写代码, 都比较重要, 分别如下
spark-shell
Spark shell 是 Spark 提供的一个基于 Scala 语言的交互式解释器, 类似于 Scala 提供的交互式解释器, Spark shell 也可以直接在 Shell 中编写代码执行
这种方式也比较重要, 因为一般的数据分析任务可能需要探索着进行, 不是一蹴而就的, 使用 Spark shell 先进行探索, 当代码稳定以后, 使用独立应用的方式来提交任务, 这样是一个比较常见的流程spark-submit
Spark submit 是一个命令, 用于提交 Scala 编写的基于 Spark 框架, 这种提交方式常用作于在集群中运行任务上面的计算pi就是一个spark-submit
1 Spark shell 的方式编写 WordCount (本地文件)
Spark shell 简介
- 启动 Spark shell
进入 Spark 安装目录后执行spark-shell --master master就可以提交Spark 任务 - Spark shell 的原理是把每一行 Scala 代码编译成类, 最终交由 Spark 执行
Master地址的设置
| 地址 | 解释 |
|---|---|
local[N] |
使用 N 条 Worker 线程在本地运行 |
spark://host:port |
在 Spark standalone 中运行, 指定 Spark 集群的 Master 地址, 端口默认为 7077 |
mesos://host:port |
在 Apache Mesos 中运行, 指定 Mesos 的地址 |
yarn |
在 Yarn 中运行, Yarn 的地址由环境变量 HADOOP_CONF_DIR 来指定 |
接下来使用 Spark shell 的方式编写一个 WordCount
1.1 准备文件
在 Node01 中创建文件 /export/data/wordcount.txt
1 | word,hello,world,hadoop |
2.2 启动spark-shell 本地线程模式
1 | cd /export/servers/spark |
2.3 执行代码
1 | //获取文件 |
上述代码中 sc 变量指的是 SparkContext, 是 Spark 程序的上下文和入口
正常情况下我们需要自己创建, 但是如果使用 Spark shell 的话, Spark shell 会帮助我们创建, 并且以变量 sc 的形式提供给我们调用
运行流程
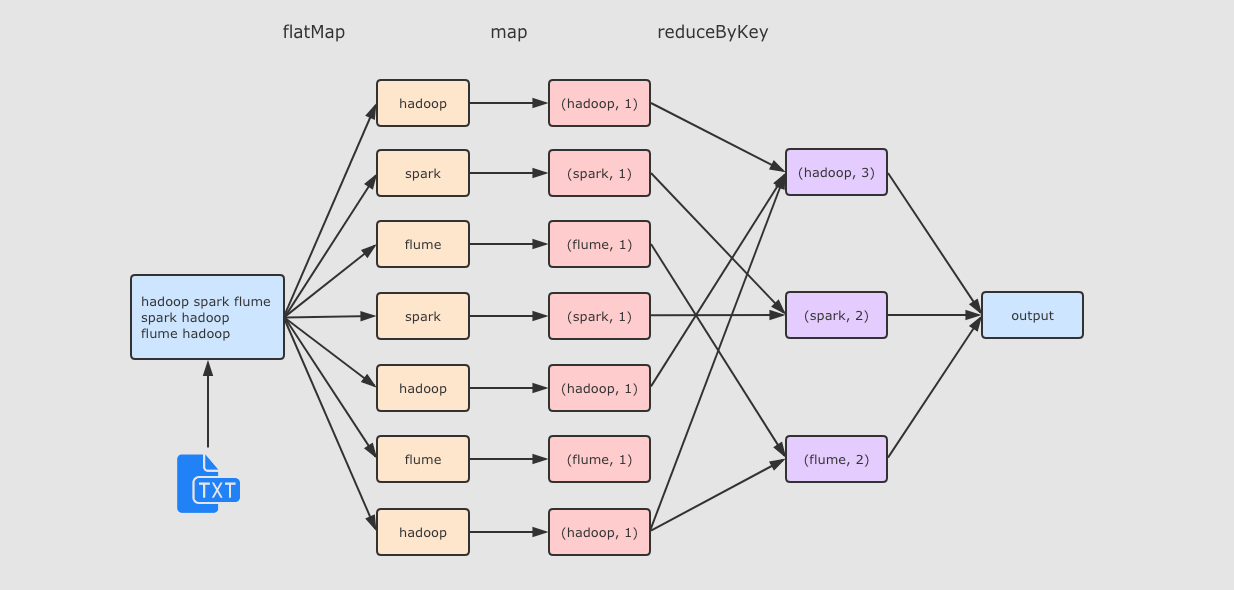
flatMap(_.split(" "))将数据转为数组的形式, 并展平为多个数据map_, 1将数据转换为元组的形式reduceByKey(_ + _)计算每个 Key 出现的次数
总结
- 使用 Spark shell 可以快速验证想法
- Spark 框架下的代码非常类似 Scala 的函数式调用
2 读取hdfs上的文件
2.1 上传文件呢到hdfs
1 | hdfs dfs -put wordcount.txt /data |
2.2 在spark-shell中访问hdfs
1 | //获取文件 |
也可以通过向 Spark 配置 Hadoop 的路径, 来通过路径直接访问
1.在
spark-env.sh中添加 Hadoop 的配置路径export HADOOP_CONF_DIR="/etc/hadoop/conf"2.在配置过后, 可以直接使用
hdfs:///路径的形式直接访问
在配置过后, 也可以直接使用路径访问
(“/data”)
3 编写独立应用提交spark任务
创建maven工程
3.1 添加依赖
1 | <properties> |
编写代码
1 | package com.nicai.sparkwordcount |
3.2 运行
####1以上代码可以直接在本地运行
若是本地运行有错:
1 | Error:scalac: error while loading <root>, Error accessing G:\apache-maven-3.3.9\apache-maven-3.3.9\repository_pinyougou\javax\ws\rs\javax.ws.rs-api\2.0.1\javax.ws.rs-api-2.0.1.jar |
2 打包在集群运行spark-submit
修改代码
1 | val conf: SparkConf =new SparkConf().setAppName("word_count") |
使用maven打包
spark-submit 命令
1 | spark-submit [options] <app jar> <app options> |
options 参数
| 参数 | 解释 |
|---|---|
--master <url> |
同 Spark shell 的 Master, 可以是spark, yarn, mesos, kubernetes等 URL |
--deploy-mode <client or cluster> |
Driver 运行位置, 可选 Client 和 Cluster, 分别对应运行在本地和集群(Worker)中 |
--class <class full name> |
Jar 中的 Class, 程序入口 |
--jars <dependencies path> |
依赖 Jar 包的位置 |
--driver-memory <memory size> |
Driver 程序运行所需要的内存, 默认 512M |
--executor-memory <memory size> |
Executor 的内存大小, 默认 1G |
打包后有两个jar包 一个带有依赖 (大) 一个(小) 因为集群中的spark自带有Hadoop和spark的jar包 所以不需要上传大的,只需上传小的即可
在上传的jar包所在目录执行:
1 | spark-submit --master spark://node01:7077 \ |
若想在任意目录执行 shell-submit 配置一下:
1 | vim /etc/profile |
4 三种方式总结
Spark shell
- 作用
- 一般用作于探索阶段, 通过 Spark shell 快速的探索数据规律
- 当探索阶段结束后, 代码确定以后, 通过独立应用的形式上线运行
- 功能
- Spark shell 可以选择在集群模式下运行, 还是在线程模式下运行
- Spark shell 是一个交互式的运行环境, 已经内置好了 SparkContext 和 SparkSession 对象, 可以直接使用
- Spark shell 一般运行在集群中安装有 Spark client 的服务器中, 所以可以自有的访问 HDFS
本地运行
- 作用
- 在编写独立应用的时候, 每次都要提交到集群中还是不方便, 另外很多时候需要调试程序, 所以在 IDEA 中直接运行会比较方便, 无需打包上传了
- 功能
- 因为本地运行一般是在开发者的机器中运行, 而不是集群中, 所以很难直接使用 HDFS 等集群服务, 需要做一些本地配置, 用的比较少
- 需要手动创建 SparkContext
集群运行
- 作用
- 正式环境下比较多见, 独立应用编写好以后, 打包上传到集群中, 使用
spark-submit来运行, 可以完整的使用集群资源
- 正式环境下比较多见, 独立应用编写好以后, 打包上传到集群中, 使用
- 功能
- 同时在集群中通过
spark-submit来运行程序也可以选择是用线程模式还是集群模式 - 集群中运行是全功能的, HDFS 的访问, Hive 的访问都比较方便
- 需要手动创建 SparkContext
- 同时在集群中通过
四 RDD简介
在idea中的wc代码中
- 使用
sc.textFile()方法读取 HDFS 中的文件, 并生成一个RDD - 使用
flatMap算子将读取到的每一行字符串打散成单词, 并把每个单词变成新的行 - 使用
map算子将每个单词转换成(word, 1)这种元组形式 - 使用
reduceByKey统计单词对应的频率
其中所使用到的算子有如下几个:
flatMap是一对多map是一对一reduceByKey是按照 Key 聚合, 类似 MapReduce 中的 Shuffled
1 rdd
定义
RDD, 全称为 Resilient Distributed Datasets, 是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数据的分区.
同时, RDD 还提供了一组丰富的操作来操作这些数据. 在这些操作中, 诸如 map, flatMap, filter 等转换操作实现了 Monad 模式, 很好地契合了 Scala 的集合操作. 除此之外, RDD 还提供了诸如 join, groupBy, reduceByKey 等更为方便的操作, 以支持常见的数据运算.
通常来讲, 针对数据处理有几种常见模型, 包括: Iterative Algorithms, Relational Queries, MapReduce, Stream Processing. 例如 Hadoop MapReduce 采用了 MapReduce 模型, Storm 则采用了 Stream Processing 模型. RDD 混合了这四种模型, 使得 Spark 可以应用于各种大数据处理场景.
RDD 作为数据结构, 本质上是一个只读的分区记录集合. 一个 RDD 可以包含多个分区, 每个分区就是一个 DataSet 片段.
RDD 之间可以相互依赖, 如果 RDD 的每个分区最多只能被一个子 RDD 的一个分区使用,则称之为窄依赖, 若被多个子 RDD 的分区依赖,则称之为宽依赖. 不同的操作依据其特性, 可能会产生不同的依赖. 例如 map 操作会产生窄依赖, 而 join 操作则产生宽依赖.
特点
- RDD 是一个编程模型
- RDD 允许用户显式的指定数据存放在内存或者磁盘
- RDD 是分布式的, 用户可以控制 RDD 的分区
- RDD 是一个编程模型
- RDD 提供了丰富的操作
- RDD 提供了 map, flatMap, filter 等操作符, 用以实现 Monad 模式
- RDD 提供了 reduceByKey, groupByKey 等操作符, 用以操作 Key-Value 型数据
- RDD 提供了 max, min, mean 等操作符, 用以操作数字型的数据
- RDD 是混合型的编程模型, 可以支持迭代计算, 关系查询, MapReduce, 流计算
- RDD 是只读的
- RDD 之间有依赖关系, 根据执行操作的操作符的不同, 依赖关系可以分为宽依赖和窄依赖
2 rdd 分区
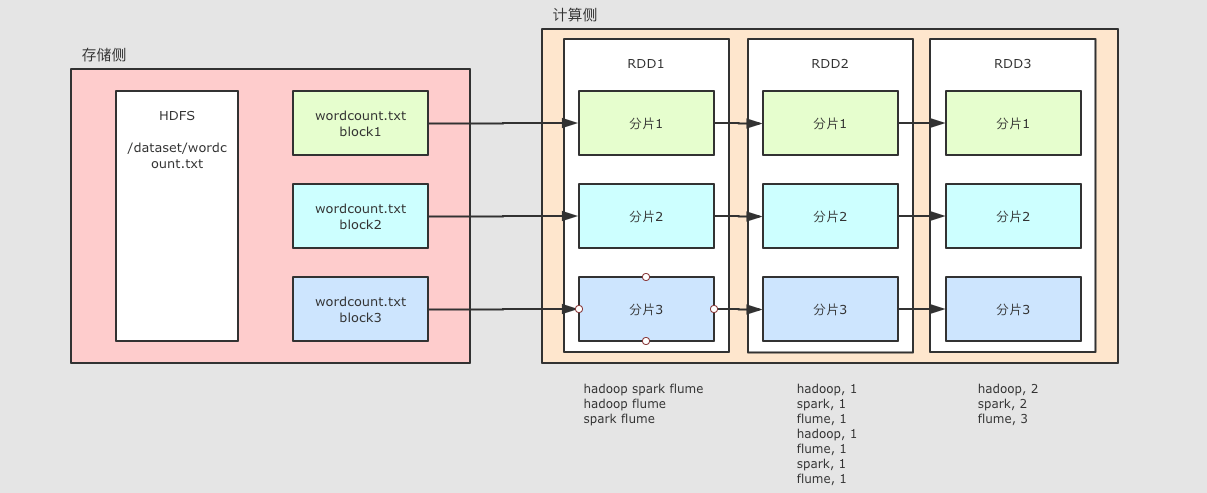
整个 WordCount 案例的程序从结构上可以用上图表示, 分为两个大部分
存储
文件如果存放在 HDFS 上, 是分块的, 类似上图所示, 这个 wordcount.txt 分了三块
计算
Spark 不止可以读取 HDFS, Spark 还可以读取很多其它的数据集, Spark 可以从数据集中创建出 RDD
例如上图中, 使用了一个 RDD 表示 HDFS 上的某一个文件, 这个文件在 HDFS 中是分三块, 那么 RDD 在读取的时候就也有三个分区, 每个 RDD 的分区对应了一个 HDFS 的分块
后续 RDD 在计算的时候, 可以更改分区, 也可以保持三个分区, 每个分区之间有依赖关系, 例如说 RDD2 的分区一依赖了 RDD1 的分区一
RDD 之所以要设计为有分区的, 是因为要进行分布式计算, 每个不同的分区可以在不同的线程, 或者进程, 甚至节点中, 从而做到并行计算
总结
- RDD 是弹性分布式数据集
- RDD 一个非常重要的前提和基础是 RDD 运行在分布式环境下, 其可以分区
3 创建rdd
程序入口 SparkContext
1 | val conf = new SparkConf().setMaster("local[2]") |
SparkContext 是 spark-core 的入口组件, 是一个 Spark 程序的入口, 在 Spark 0.x 版本就已经存在 SparkContext 了, 是一个元老级的 API
如果把一个 Spark 程序分为前后端, 那么服务端就是可以运行 Spark 程序的集群, 而 Driver 就是 Spark 的前端, 在 Driver中 SparkContext 是最主要的组件, 也是 Driver 在运行时首先会创建的组件, 是 Driver 的核心
SparkContext 从提供的 API 来看, 主要作用是连接集群, 创建 RDD, 累加器, 广播变量等
简略的说, RDD 有三种创建方式
- RDD 可以通过本地集合直接创建
- RDD 也可以通过读取外部数据集来创建
- RDD 也可以通过其它的 RDD 衍生而来
###1 通过本地集合直接创建
1 | val conf = new SparkConf().setMaster("local[2]") |
通过 parallelize 和 makeRDD 这两个 API 可以通过本地集合创建 RDD
这两个 API 本质上是一样的, 在 makeRDD 这个方法的内部, 最终也是调用了 parallelize
因为不是从外部直接读取数据集的, 所以没有外部的分区可以借鉴, 于是在这两个方法都都有两个参数, 第一个参数是本地集合, 第二个参数是分区数
2 通过读取外部文件创建 RDD
1 | val conf = new SparkConf().setMaster("local[2]") |
- 访问方式
- 支持访问文件夹, 例如
sc.textFile("hdfs:///dataset") - 支持访问压缩文件, 例如
sc.textFile("hdfs:///dataset/words.gz") - 支持通过通配符访问, 例如
sc.textFile("hdfs:///dataset/*.txt")
- 支持访问文件夹, 例如
如果把 Spark 应用跑在集群上, 则 Worker 有可能在任何一个节点运行所以如果使用 file:///…; 形式访问本地文件的话, 要确保所有的 Worker 中对应路径上有这个文件, 否则可能会报错无法找到文件 |
|
|---|---|
- 分区
- 默认情况下读取 HDFS 中文件的时候, 每个 HDFS 的
block对应一个 RDD 的partition,block的默认是128M - 通过第二个参数, 可以指定分区数量, 例如
sc.textFile("hdfs://node01:8020/dataset/wordcount.txt", 20) - 如果通过第二个参数指定了分区, 这个分区数量一定不能小于
block数
- 默认情况下读取 HDFS 中文件的时候, 每个 HDFS 的
| 通常每个 CPU core 对应 2 - 4 个分区是合理的值 | |
|---|---|
- 支持的平台
- 支持 Hadoop 的几乎所有数据格式, 支持 HDFS 的访问
- 通过第三方的支持, 可以访问AWS和阿里云中的文件, 详情查看对应平台的 API
3 通过其它的 RDD 衍生新的 RDD
1 | val conf = new SparkConf().setMaster("local[2]") |
source是通过读取 HDFS 中的文件所创建的words是通过source调用算子map生成的新 RDD
总结
RDD 的可以通过三种方式创建, 通过本地集合创建, 通过外部数据集创建, 通过其它的 RDD 衍生
4 rdd算子
1 Map 算子
1 | sc.parallelize(Seq(1, 2, 3)) |
作用
把 RDD 中的数据 一对一 的转为另一种形式
调用
1 | def map[U: ClassTag](f: T ⇒ U): RDD[U] |
参数
f → Map 算子是 原RDD → 新RDD 的过程, 这个函数的参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据
注意点
Map 是一对一, 如果函数是 String → Array[String] 则新的 RDD 中每条数据就是一个数组
2 FlatMap
1 | sc.parallelize(Seq("Hello lily", "Hello lucy", "Hello tim")) |
作用
FlatMap 算子和 Map 算子类似, 但是 FlatMap 是一对多
调用
1 | def flatMap[U: ClassTag](f: T ⇒ List[U]): RDD[U] |
参数
f → 参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据, 需要注意的是返回值是一个集合, 集合中的数据会被展平后再放入新的 RDD
注意点
flatMap 其实是两个操作, 是 map + flatten, 也就是先转换, 后把转换而来的 List 展开
3ReduceByKey
1 | sc.parallelize(Seq(("a", 1), ("a", 1), ("b", 1))) |
作用
首先按照 Key 分组, 接下来把整组的 Value 计算出一个聚合值, 这个操作非常类似于 MapReduce 中的 Reduce
调用
1 | def reduceByKey(func: (V, V) ⇒ V): RDD[(K, V)] |
参数
func → 执行数据处理的函数, 传入两个参数, 一个是当前值, 一个是局部汇总, 这个函数需要有一个输出, 输出就是这个 Key 的汇总结果
注意点
- ReduceByKey 只能作用于 Key-Value 型数据, Key-Value 型数据在当前语境中特指 Tuple2
- ReduceByKey 是一个需要 Shuffled 的操作
- 和其它的 Shuffled 相比, ReduceByKey是高效的, 因为类似 MapReduce 的, 在 Map 端有一个 Cominer, 这样 I/O 的数据便会减少
总结
- map 和 flatMap 算子都是转换, 只是 flatMap 在转换过后会再执行展开, 所以 map 是一对一, flatMap 是一对多
- reduceByKey 类似 MapReduce 中的 Reduce