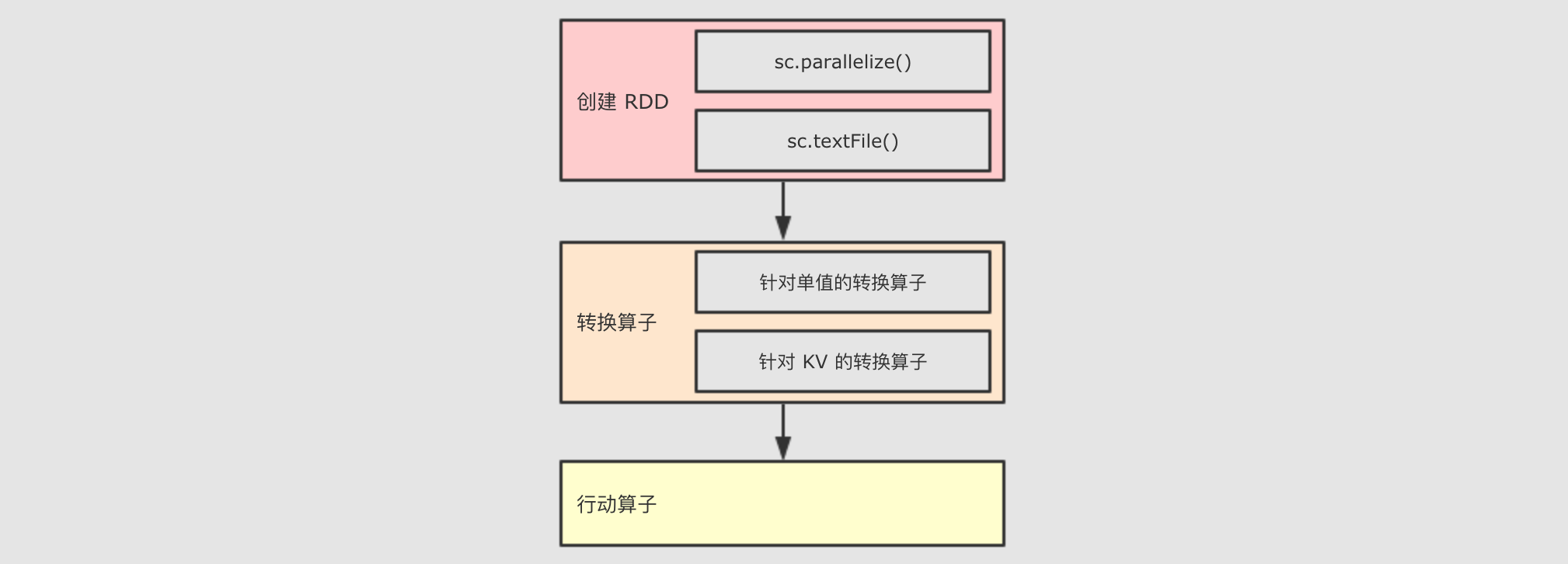
一 深入RDDS
先来个小demo
1 需求
在访问日志中,统计独立IP数量,TOP10
2 明确数据结构
IP,时间戳,http method,URL……
1 | 1/Nov/2017:00:00:15 +0000] "GET /axis2/services/WebFilteringService/getCategoryByUrl?app=chrome_antiporn&ver=0.19.7.1&url=https%3A//securepubads.g.doubleclick.net/static/3p_cookie.html&cat=business-and-economy HTTP/1.1" 200 133 "-" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36" |
3 明确编码步骤
1 取出IP,生成只有IP的数据集
2 简单清洗
3 统计IP出现次数
4 排序 按照IP出现次数
5 取出前十
1 |
|
4 解析
1假设要针对整个网站的历史数据进行处理, 量有 1T, 如何处理?
因为单机运行瓶颈太多内存,磁盘,CPU等
放在集群中, 利用集群多台计算机来并行处理
2如何放在集群中运行?
简单来讲, 并行计算就是同时使用多个计算资源解决一个问题, 有如下四个要点
- 要解决的问题必须可以分解为多个可以并发计算的部分
- 每个部分要可以在不同处理器上被同时执行
- 需要一个共享内存的机制
- 需要一个总体上的协作机制来进行调度
3 如果放在集群中的话, 可能要对整个计算任务进行分解, 如何分解?
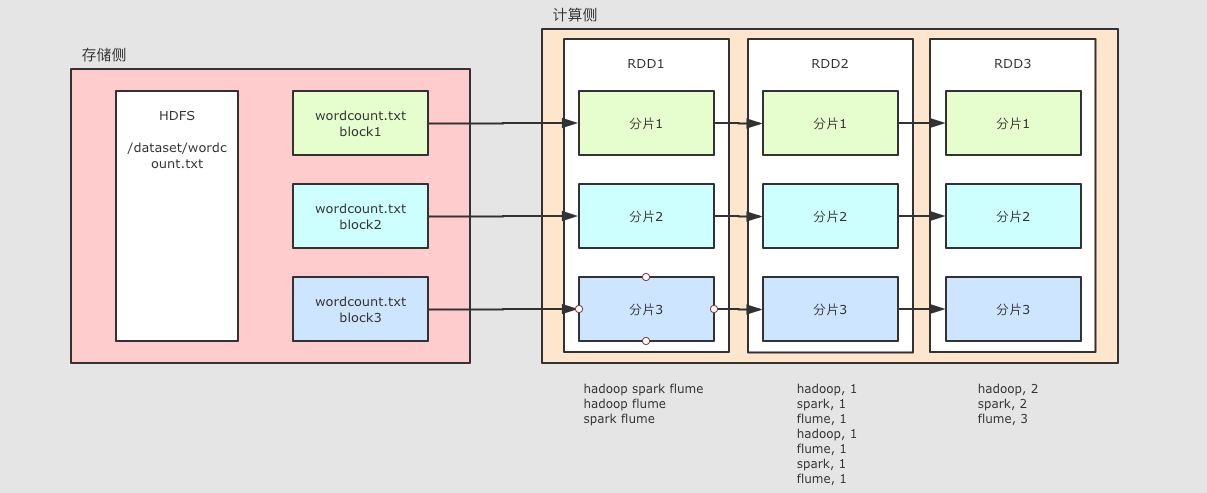
概述
- 对于 HDFS 中的文件, 是分为不同的 Block 的
- 在进行计算的时候, 就可以按照 Block 来划分, 每一个 Block 对应一个不同的计算单元
扩展
RDD并没有真实的存放数据, 数据是从 HDFS 中读取的, 在计算的过程中读取即可RDD至少是需要可以 分片 的, 因为HDFS中的文件就是分片的,RDD分片的意义在于表示对源数据集每个分片的计算,RDD可以分片也意味着 可以并行计算
4 移动数据不如移动计算是一个基础的优化, 如何做到?
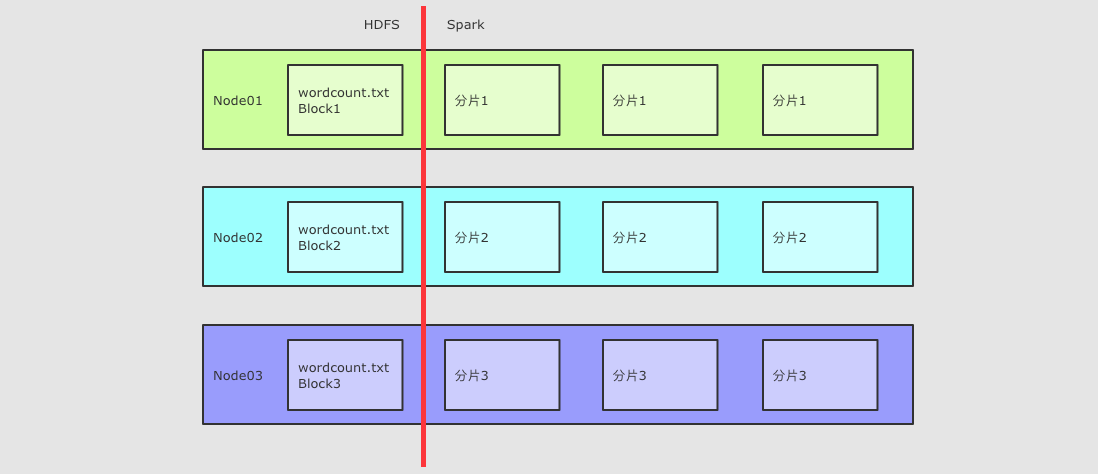
每一个计算单元需要记录其存储单元的位置, 尽量调度过去
5 在集群中运行, 需要很多节点之间配合, 出错的概率也更高, 出错了怎么办?

RDD1 → RDD2 → RDD3 这个过程中, RDD2 出错了, 有两种办法可以解决
- 缓存 RDD2 的数据, 直接恢复 RDD2, 类似 HDFS 的备份机制
- 记录 RDD2 的依赖关系, 通过其父级的 RDD 来恢复 RDD2, 这种方式会少很多数据的交互和保存
如何通过父级 RDD 来恢复?
- 记录 RDD2 的父亲是 RDD1
- 记录 RDD2 的计算函数, 例如记录
RDD2 = RDD1.map(…),map(…)就是计算函数 - 当 RDD2 计算出错的时候, 可以通过父级 RDD 和计算函数来恢复 RDD2
6 假如任务特别复杂, 流程特别长, 有很多 RDD 之间有依赖关系, 如何优化?
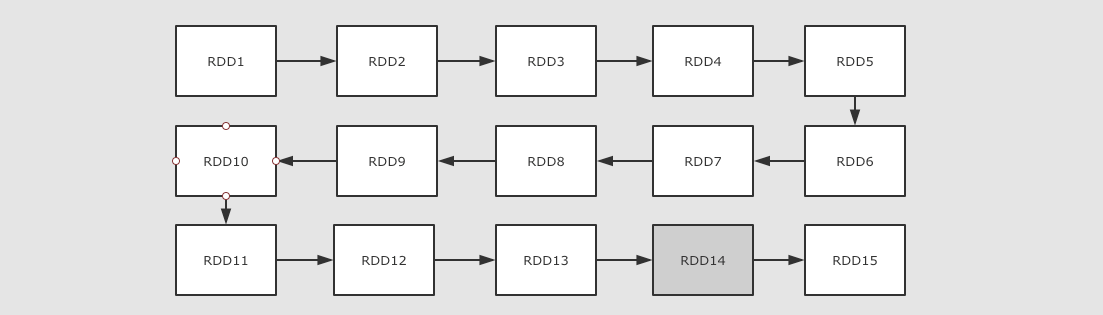
上面提到了可以使用依赖关系来进行容错, 但是如果依赖关系特别长的时候, 这种方式其实也比较低效, 这个时候就应该使用另外一种方式, 也就是记录数据集的状态
- 在 Spark 中有两个手段可以做到
- 缓存Checkpoint
5 rdd出现解决了什么问题
在 RDD 出现之前, 当时 MapReduce 是比较主流的, 而 MapReduce 如何执行迭代计算的任务呢?

多个 MapReduce 任务之间没有基于内存的数据共享方式, 只能通过磁盘来进行共享
这种方式明显比较低效
rdd 执行迭代计算任务

在 Spark 中, 其实最终 Job3 从逻辑上的计算过程是: Job3 = (Job1.map).filter, 整个过程是共享内存的, 而不需要将中间结果存放在可靠的分布式文件系统中
这种方式可以在保证容错的前提下, 提供更多的灵活, 更快的执行速度, RDD 在执行迭代型任务时候的表现可以通过下面代码体现
1 | // 线性回归 |
6 rdd的特点
RDD 不仅是数据集, 也是编程模型
RDD 即是一种数据结构, 同时也提供了上层 API, 同时 RDD 的 API 和 Scala 中对集合运算的 API 非常类似, 同样也都是各种算子
RDD 的算子大致分为两类:
- Transformation 转换操作, 例如
mapflatMapfilter等 - Action 动作操作, 例如
reducecollectshow等
执行 RDD 的时候, 在执行到转换操作的时候, 并不会立刻执行, 直到遇见了 Action 操作, 才会触发真正的执行, 这个特点叫做 惰性求值
rdd可以分区
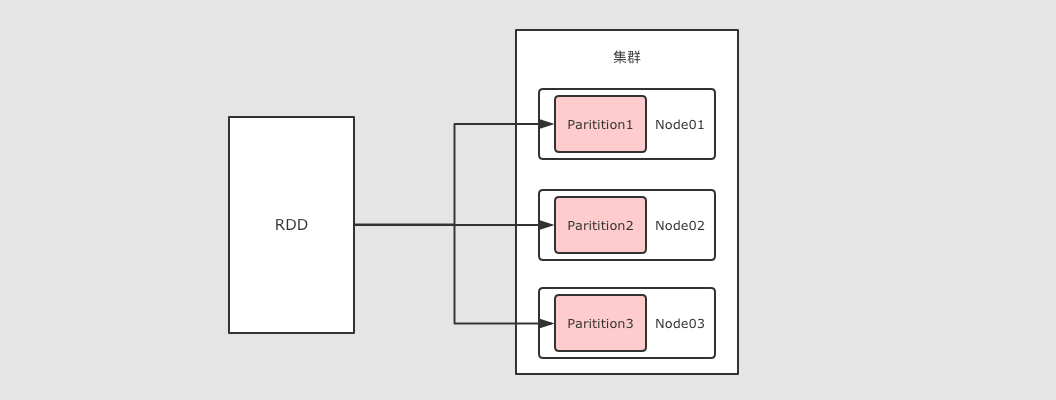
RDD 是一个分布式计算框架, 所以, 一定是要能够进行分区计算的, 只有分区了, 才能利用集群的并行计算能力
同时, RDD 不需要始终被具体化, 也就是说: RDD 中可以没有数据, 只要有足够的信息知道自己是从谁计算得来的就可以, 这是一种非常高效的容错方式
rdd是只读的
RDD 是只读的, 不允许任何形式的修改. 虽说不能因为 RDD 和 HDFS 是只读的, 就认为分布式存储系统必须设计为只读的. 但是设计为只读的, 会显著降低问题的复杂度, 因为 RDD 需要可以容错, 可以惰性求值, 可以移动计算, 所以很难支持修改.
- RDD2 中可能没有数据, 只是保留了依赖关系和计算函数, 那修改啥?
- 如果因为支持修改, 而必须保存数据的话, 怎么容错?
- 如果允许修改, 如何定位要修改的那一行? RDD 的转换是粗粒度的, 也就是说, RDD 并不感知具体每一行在哪.
rdd是可以容错的
RDD 的容错有两种方式
- 保存 RDD 之间的依赖关系, 以及计算函数, 出现错误重新计算
- 直接将 RDD 的数据存放在外部存储系统, 出现错误直接读取, Checkpoint
弹性分布式数据集
分布式
RDD 支持分区, 可以运行在集群中
弹性
- RDD 支持高效的容错
- RDD 中的数据即可以缓存在内存中, 也可以缓存在磁盘中, 也可以缓存在外部存储中
数据集
- RDD 可以不保存具体数据, 只保留创建自己的必备信息, 例如依赖和计算函数
- RDD 也可以缓存起来, 相当于存储具体数据
总结 rdd的五大属性
首先整理一下上面所提到的 RDD 所要实现的功能:
- RDD 有分区
- RDD 要可以通过依赖关系和计算函数进行容错
- RDD 要针对数据本地性进行优化
- RDD 支持 MapReduce 形式的计算, 所以要能够对数据进行 Shuffled
对于 RDD 来说, 其中应该有什么内容呢? 如果站在 RDD 设计者的角度上, 这个类中, 至少需要什么属性?
Partition List分片列表, 记录 RDD 的分片, 可以在创建 RDD 的时候指定分区数目, 也可以通过算子来生成新的 RDD 从而改变分区数目Compute Function为了实现容错, 需要记录 RDD 之间转换所执行的计算函数RDD DependenciesRDD 之间的依赖关系, 要在 RDD 中记录其上级 RDD 是谁, 从而实现容错和计算Partitioner为了执行 Shuffled 操作, 必须要有一个函数用来计算数据应该发往哪个分区Preferred Location优先位置, 为了实现数据本地性操作, 从而移动计算而不是移动存储, 需要记录每个 RDD 分区最好应该放置在什么位置
二 rdd算子
1 分类
RDD 中的算子从功能上分为两大类
- Transformation(转换) 它会在一个已经存在的 RDD 上创建一个新的 RDD, 将旧的 RDD 的数据转换为另外一种形式后放入新的 RDD(map,flatMap等) 转换算子的本质就是生成各种rdd,让rdd之间具有联系,只是生成rdd链条,执行到转换的时候,并不会真的执行整个程序,而是在Action被调用后,程序才可以执行
- Action(动作) 执行各个分区的计算任务, 将的到的结果返回到 Driver 中 执行操作
RDD 中可以存放各种类型的数据, 那么对于不同类型的数据, RDD 又可以分为三类
- 针对基础类型(例如 String)处理的普通算子
- 针对
Key-Value数据处理的byKey算子 (reduceByKey等) - 针对数字类型数据处理的计算算子
2 特点
- Spark 中所有的 Transformations 是 Lazy(惰性) 的, 它们不会立即执行获得结果. 相反, 它们只会记录在数据集上要应用的操作. 只有当需要返回结果给 Driver 时, 才会执行这些操作, 通过 DAGScheduler 和 TaskScheduler 分发到集群中运行, 这个特性叫做 惰性求值
- 默认情况下, 每一个 Action 运行的时候, 其所关联的所有 Transformation RDD 都会重新计算, 但是也可以使用
presist方法将 RDD 持久化到磁盘或者内存中. 这个时候为了下次可以更快的访问, 会把数据保存到集群上.
3 TransFormation算子
1 map
1 | sc.parallelize(Seq(1, 2, 3)) |
map(T ⇒ U)
作用
- 把 RDD 中的数据 一对一 的转为另一种形式
签名
1 | def map[U: ClassTag](f: T ⇒ U): RDD[U] |
参数
f→ Map 算子是原RDD → 新RDD的过程, 传入函数的参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据
注意点
- Map 是一对一, 如果函数是
String → Array[String]则新的 RDD 中每条数据就是一个数组
2 flatMap(T ⇒ List[U])
1 | sc.parallelize(Seq("Hello lily", "Hello lucy", "Hello tim")) |
作用
- FlatMap 算子和 Map 算子类似, 但是 FlatMap 是一对多
调用
1 | def flatMap[U: ClassTag](f: T ⇒ List[U]): RDD[U] |
参数
f→ 参数是原 RDD 数据, 返回值是经过函数转换的新 RDD 的数据, 需要注意的是返回值是一个集合, 集合中的数据会被展平后再放入新的 RDD
注意点
- flatMap 其实是两个操作, 是
map + flatten, 也就是先转换, 后把转换而来的 List 展开 - Spark 中并没有直接展平 RDD 中数组的算子, 可以使用
flatMap做这件事
3mapPartitions(List[T] ⇒ List[U])
DD[T] ⇒ RDD[U] 和 map 类似, 但是针对整个分区的数据转换
map是针对一条数据,mapPartitions是针对一个分区的数据转换
1 | context.parallelize(Seq(1,2,3,4),2) //2 为分区数 |
注意 mapPartitions()的返回值和传入参数都是集合类型 因为是一个分区的数据
1 | context.parallelize(Seq(1,2,3,4),2) //2 为分区数 |
4 mapPartitionsWithIndex
和 mapPartitions 类似, 只是在函数中增加了分区的 Index
1 | context.parallelize(Seq(1,0,55,555,999),2) |
结果:
1 | index0 |
1 | context.parallelize(Seq(1,2,3,4),2) |
1 | index0 |
map,mapPartitions和mapPartitionsWithIndex区别
| 参数 | 返回值 | 参数个数 | |
|---|---|---|---|
| map | 单条数据 | 单条数据 | 一个 |
| mapPartitions | 集合(一个分区所有数据) | 集合 | 一个 |
| mapPartitionsWithIndex | 集合(一个分区所有数据)和分区数 | 集合 | 两个 |
5 filter
作用
Filter算子的主要作用是过滤掉不需要的内容
接收函数,参数为每一个元素,如果函数返回为true当前元素会被加入新的数据集,如果为false,会过滤掉该元素
1 | context.parallelize(Seq(1,0,55,555,999,88),2) |
6 sample(withReplacement, fraction, seed)
作用
- Sample 算子可以从一个数据集中抽样出来一部分, 常用作于减小数据集以保证运行速度, 并且尽可能少规律的损失
参数
- Sample 接受第一个参数为
withReplacement, 意为是否取样以后是否还放回原数据集供下次使用, 简单的说, 如果这个参数的值为 true, 则抽样出来的数据集中可能会有重复 若为false 则不会有重复的值 - Sample 接受第二个参数为
fraction, 意为抽样的比例 double类型 - Sample 接受第三个参数为
seed, 随机数种子, 用于 Sample 内部随机生成下标, 一般不指定, 使用默认值
1 | val value = context.parallelize(Seq(1,2,3,4,5,6),2) //1,2,3,4,5,6 1,0,55,555,999,88 |
1 | 2 |
7 mapValues
作用
- MapValues 只能作用于 Key-Value 型数据, 和 Map 类似, 也是使用函数按照转换数据, 不同点是 MapValues 只转换 Key-Value 中的 Value
1 | context.parallelize(Seq(("a",1),("b",2),("c",3),("d",4),("e",5)),2) |
8 差集,交集和并集
union(other) 并集 所有元素都会集合,包括重复的元素
intersection(other) 交集
Intersection 算子是一个集合操作, 用于求得 左侧集合 和 右侧集合 的交集, 换句话说, 就是左侧集合和右侧集合都有的元素, 并生成一个新的 RDD
**subtract(other, numPartitions)**差集, 可以设置分区数 a中有 b中没有的
1 | //交集 并集 差集 |
9 distinct(numPartitions)
作用
- Distinct 算子用于去重
注意点
- Distinct 是一个需要 Shuffled 的操作
- 本质上 Distinct 就是一个 reductByKey, 把重复的合并为一个
1 | sc.parallelize(Seq(1, 1, 2, 2, 3)) |
10groupByKey与reduceByKey
reduceByKey:
reduceByKey((V, V) ⇒ V, numPartition)
作用
- 首先按照 Key 分组生成一个 Tuple, 然后针对每个组执行
reduce算子
调用
1 | def reduceByKey(func: (V, V) ⇒ V): RDD[(K, V)] |
参数
- func → 执行数据处理的函数, 传入两个参数, 一个是当前值, 一个是局部汇总, 这个函数需要有一个输出, 输出就是这个 Key 的汇总结果
注意点
- ReduceByKey 只能作用于 Key-Value 型数据, Key-Value 型数据在当前语境中特指 Tuple2
- ReduceByKey 是一个需要 Shuffled 的操作
- 和其它的 Shuffled 相比, ReduceByKey是高效的, 因为类似 MapReduce 的, 在 Map 端有一个 Cominer, 这样 I/O 的数据便会减少
1 |
groupByKey
作用
- GroupByKey 算子的主要作用是按照 Key 分组, 和 ReduceByKey 有点类似, 但是 GroupByKey 并不求聚合, 只是列举 Key 对应的所有 Value
注意点
- GroupByKey 是一个 Shuffled
- GroupByKey 和 ReduceByKey 不同, 因为需要列举 Key 对应的所有数据, 所以无法在 Map 端做 Combine, 所以 GroupByKey 的性能并没有 ReduceByKey 好
1 |
总结
reduceByKey:在map端做Combiner 了可对结果做 聚合
groupByKey: 在map端不做聚合,也不做Combiner 结果格式: (k,(values,value,….))
###11combineByKey()
作用
- 对数据集按照 Key 进行聚合
调用
combineByKey(createCombiner, mergeValue, mergeCombiners, [partitioner], [mapSideCombiner], [serializer])
参数
createCombiner将 Value 进行初步转换mergeValue在每个分区把上一步转换的结果聚合mergeCombiners在所有分区上把每个分区的聚合结果聚合partitioner可选, 分区函数mapSideCombiner可选, 是否在 Map 端 Combineserializer序列化器
注意点
combineByKey的要点就是三个函数的意义要理解groupByKey,reduceByKey的底层都是combineByKey
例子:
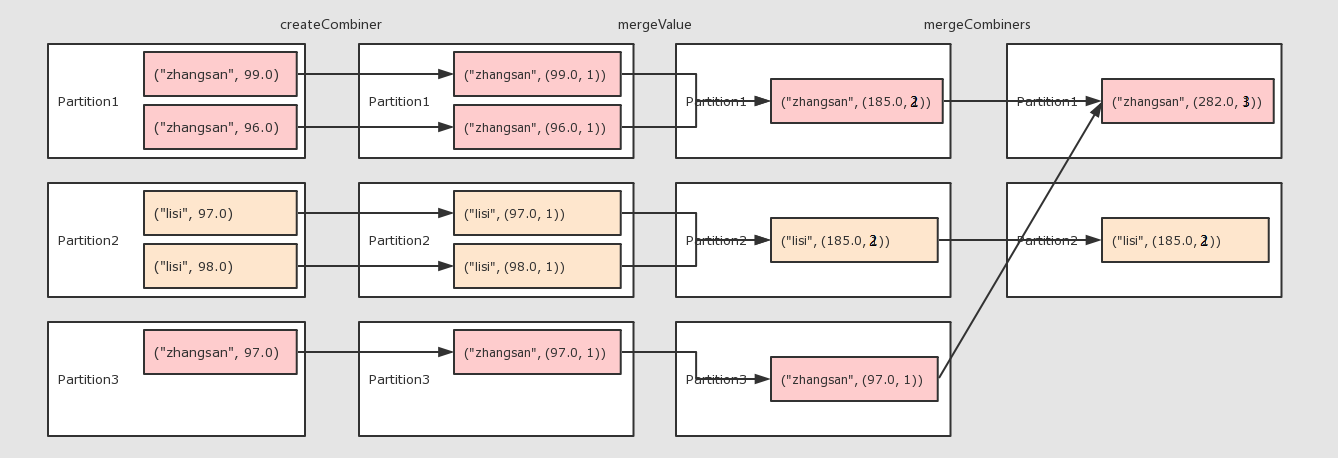
1 |
|
12 foldByKey(zeroValue)((V, V) ⇒ V)
作用
- 和 ReduceByKey 是一样的, 都是按照 Key 做分组去求聚合, 但是 FoldByKey 的不同点在于可以指定初始值
调用
1 | foldByKey(zeroValue)(func) |
参数
zeroValue初始值funcseqOp 和 combOp 相同, 都是这个参数
注意点
- FoldByKey 是 AggregateByKey 的简化版本, seqOp 和 combOp 是同一个函数
- FoldByKey 指定的初始值作用于每一个 Value
- scala 中的foldleft或者foldRight 区别是这个值不会作用于每一个value
1 |
|
结果:
1 | (d,14) |
13 aggregateByKey()
作用
聚合所有 Key 相同的 Value, 换句话说, 按照 Key 聚合 Value
调用
rdd.aggregateByKey(zeroValue)(seqOp, combOp)参数
zeroValue初始值seqOp转换每一个值的函数comboOp将转换过的值聚合的函数
注意点 *** 为什么需要两个函数?** aggregateByKey 运行将一个RDD[(K, V)]聚合为RDD[(K, U)], 如果要做到这件事的话, 就需要先对数据做一次转换, 将每条数据从V转为U, seqOp就是干这件事的 ** 当seqOp的事情结束以后, comboOp把其结果聚合
- 和 reduceByKey 的区别::
- aggregateByKey 最终聚合结果的类型和传入的初始值类型保持一致
- reduceByKey 在集合中选取第一个值作为初始值, 并且聚合过的数据类型不能改变
1 | /* |
适合针对每个数据先处理,后聚合
14 JOIN
作用
- 将两个 RDD 按照相同的 Key 进行连接
调用
1 | join(other, [partitioner or numPartitions]) |
参数
other其它 RDDpartitioner or numPartitions可选, 可以通过传递分区函数或者分区数量来改变分区
注意点
- Join 有点类似于 SQL 中的内连接, 只会再结果中包含能够连接到的 Key
- Join 的结果是一个笛卡尔积形式, 例如
"a", 1), ("a", 2和"a", 10), ("a", 11的 Join 结果集是"a", 1, 10), ("a", 1, 11), ("a", 2, 10), ("a", 2, 11
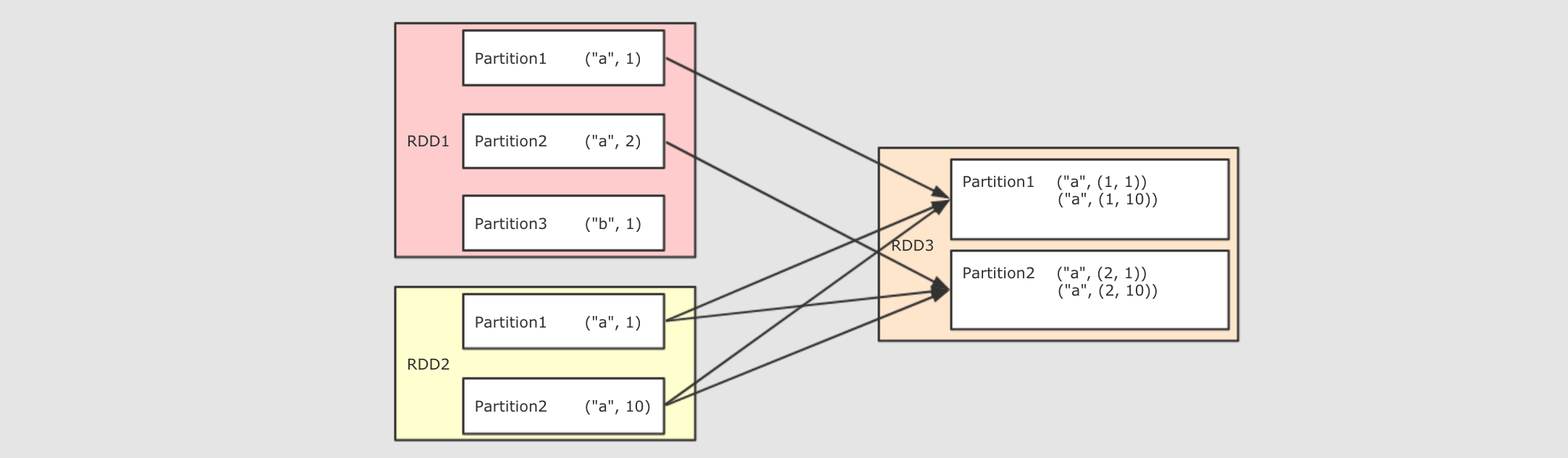
1 | //join |
15 sortBy和sortByKey
作用
- 排序相关相关的算子有两个, 一个是
sortBy, 另外一个是sortByKey
调用
1 | sortBy(func, ascending, numPartitions) |
参数
func通过这个函数返回要排序的字段ascending是否升序numPartitions分区数
注意点
- 普通的 RDD 没有
sortByKey, 只有 Key-Value 的 RDD 才有 sortBy可以指定按照哪个字段来排序,sortByKey直接按照 Key 来排序
1 | //sortBy 和sortByKey |
16 repartitioin 和 coalesce
作用 重分区
- 一般涉及到分区操作的算子常见的有两个,
repartitioin和coalesce, 两个算子都可以调大或者调小分区数量
调用
repartitioin(numPartitions)coalesce(numPartitions, shuffle)- 若coalesce想调大分区 则必须设置shuffle为true
参数
numPartitions新的分区数shuffle是否 shuffle, 如果新的分区数量比原分区数大, 必须 Shuffled, 否则重分区无效
注意点
repartition和coalesce的不同就在于coalesce可以控制是否 Shufflerepartition是一个 Shuffled 操作
1 |
|
repartitionAndSortWithinPartitions
重新分区的同时升序排序, 在partitioner中排序, 比先重分区再排序要效率高, 建议使用在需要分区后再排序的场景使用
cartesian(other)
(RDD[T], RDD[U]) ⇒ RDD[(T, U)] 生成两个 RDD 的笛卡尔积
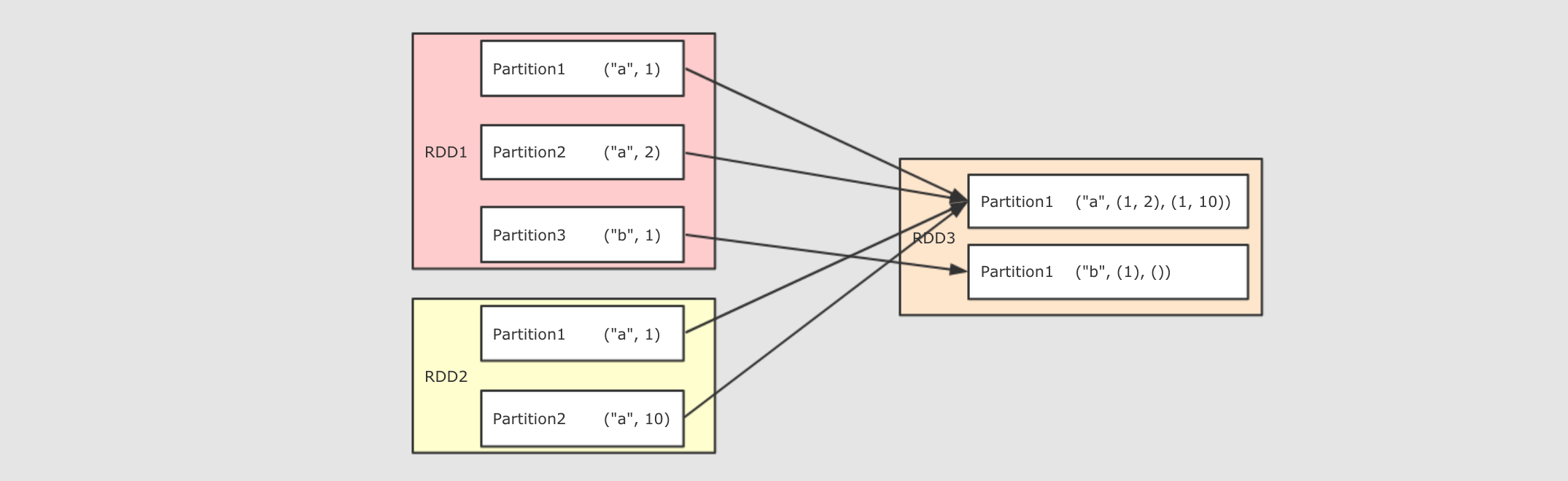
cogroup(other, numPartitions)
作用
- 多个 RDD 协同分组, 将多个 RDD 中 Key 相同的 Value 分组
调用
cogroup(rdd1, rdd2, rdd3, [partitioner or numPartitions])
参数
rdd…最多可以传三个 RDD 进去, 加上调用者, 可以为四个 RDD 协同分组partitioner or numPartitions可选, 可以通过传递分区函数或者分区数来改变分区
注意点
对 RDD1, RDD2, RDD3 进行 cogroup, 结果中就一定会有三个 List, 如果没有 Value 则是空 List, 这一点类似于 SQL 的全连接, 返回所有结果, 即使没有关联上
CoGroup 是一个需要 Shuffled 的操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26val rdd1 = sc.parallelize(Seq(("a", 1), ("a", 2), ("a", 5), ("b", 2), ("b", 6), ("c", 3), ("d", 2)))
val rdd2 = sc.parallelize(Seq(("a", 10), ("b", 1), ("d", 3)))
val rdd3 = sc.parallelize(Seq(("b", 10), ("a", 1)))
val result1 = rdd1.cogroup(rdd2).collect()
val result2 = rdd1.cogroup(rdd2, rdd3).collect()
/*
执行结果:
Array(
(d,(CompactBuffer(2),CompactBuffer(3))),
(a,(CompactBuffer(1, 2, 5),CompactBuffer(10))),
(b,(CompactBuffer(2, 6),CompactBuffer(1))),
(c,(CompactBuffer(3),CompactBuffer()))
)
*/
println(result1)
/*
执行结果:
Array(
(d,(CompactBuffer(2),CompactBuffer(3),CompactBuffer())),
(a,(CompactBuffer(1, 2, 5),CompactBuffer(10),CompactBuffer(1))),
(b,(CompactBuffer(2, 6),CompactBuffer(1),Co...
*/
println(result2)
总结
所有的转换操作的算子都是惰性的,在执行的时候并不会真的去调度运行,求得结果,而是只是生成了对应的RDD,只有在Action时,才会真的运行求得结果

2 Action 算子
1 reduce( (T, T) ⇒ U ) 不是一个shuffle操作
作用
- 对整个结果集规约, 最终生成一条数据, 是整个数据集的汇总
调用
reduce( (currValue[T], agg[T]) ⇒ T )
注意点
- reduce 和 reduceByKey 是完全不同的, reduce 是一个 action, 并不是 Shuffled 操作
- 本质上 reduce 就是现在每个 partition 上求值, 最终把每个 partition 的结果再汇总
- 例如 一个RDD里面有一万条数据,大部分key相同,有十个key 不同,则reduceByKey会生成10条数据,但reduce只会生成1个结果
- reduceByKey 是根据k分组,再把每组聚合 是针对kv数据进行计算
- reduce 是针对一整个数据集来进行聚合 是针对任意类型进行计算
shuffle操作: 分为mapper和reduce,mapper将数据放入partition的函数计算求得分往哪个reduce,后分到对应的reduce中
reduce操作: 并没有mapper和reduce,因为reduce算子会作用于rdd中的每一个分区,然后在分区上求得局部结果,最终汇总求得最终结果
rdd中的五大属性: Partitioner 在shuffle过程中使用,partition只有KV型数据的RDD才有
1 | class ActionDemo { |
2 collect()
以数组的形式返回数据集中所有元素
3 foreach( T ⇒ … )
遍历每一个元素
4 count() 和countByKey()
count()返回元素个数
countByKey()
作用
- 求得整个数据集中 Key 以及对应 Key 出现的次数
注意点
- 返回结果为
Map(key → count) - 常在解决数据倾斜问题时使用, 查看倾斜的 Key
1 | /* |
5 take first 和takeSample
take 返回前 N 个元素
first 返回第一个元素
takeSample(withReplacement, fract) 类似于 sample, 区别在这是一个Action, 直接返回结果
1 | take 和takeSample 一个直接获取 一个采样获取 |
1 |
|
总结
RDD 的算子大部分都会生成一些专用的 RDD
map,flatMap,filter等算子会生成MapPartitionsRDDcoalesce,repartition等算子会生成CoalescedRDD
常见的 RDD 有两种类型
- 转换型的 RDD, Transformation
- 动作型的 RDD, Action
常见的 Transformation 类型的 RDD
- map
- flatMap
- filter
- groupBy
- reduceByKey
常见的 Action 类型的 RDD
- collect
- countByKey
- reduce
3 rdd对不同类型数据的支持
RDD 对 Key-Value 类型的数据是有专门支持的,,对数字类型也有专门支持
一般要处理的类型有三种
- 字符串
- 键值对
- 数字型
RDD 的算子设计对这三类不同的数据分别都有支持
- 对于以字符串为代表的基本数据类型是比较基础的一些的操作, 诸如 map, flatMap, filter 等基础的算子
- 对于键值对类型的数据, 有额外的支持, 诸如 reduceByKey, groupByKey 等 byKey 的算子
- 同样对于数字型的数据也有额外的支持, 诸如 max, min 等
RDD 对键值对数据的额外支持
键值型数据本质上就是一个二元元组, 键值对类型的 RDD 表示为 RDD[(K, V)]
RDD 对键值对的额外支持是通过隐式支持来完成的, 一个 RDD[(K, V)], 可以被隐式转换为一个 PairRDDFunctions 对象, 从而调用其中的方法.
源码:
既然对键值对的支持是通过 PairRDDFunctions 提供的, 那么从 PairRDDFunctions 中就可以看到这些支持有什么
| 类别 | 算子 |
|---|---|
| 聚合操作 | reduceByKey foldByKey combineByKey |
| 分组操作 | cogroup groupByKey |
| 连接操作 | join leftOuterJoin rightOuterJoin |
| 排序操作 | sortBy sortByKey |
| Action | countByKey take collect |
RDD 对数字型数据的额外支持
对于数字型数据的额外支持基本上都是 Action 操作, 而不是转换操作
| 算子 | 含义 |
|---|---|
count |
个数 |
mean |
均值 |
sum |
求和 |
max |
最大值 |
min |
最小值 |
variance |
方差 |
sampleVariance |
从采样中计算方差 |
stdev |
标准差 |
sampleStdev |
采样的标准差 |
###4 使用算子 来个小demo
需求;
以年月为基础,统计北京东四地区的PM值
1 | package com.nicai.demo |