一 概述
1 数据分析的方式
数据分析的方式大致上可以划分为 SQL 和 命令式两种
命令式
在前面的 RDD 部分, 非常明显可以感觉的到是命令式的, 主要特征是通过一个算子, 可以得到一个结果, 通过结果再进行后续计算.
在前面的 RDD 部分, 非常明显可以感觉的到是命令式的, 主要特征是通过一个算子, 可以得到一个结果, 通过结果再进行后续计算.
1 | sc.textFile("...") |
命令式的优点
操作粒度更细, 能够控制数据的每一个处理环节操作更明确, 步骤更清晰, 容易维护支持非结构化数据的操作
命令式的缺点
需要一定的代码功底写起来比较麻烦
SQL
对于一些数据科学家, 要求他们为了做一个非常简单的查询, 写一大堆代码, 明显是一件非常残忍的事情, 所以 SQL on Hadoop 是一个非常重要的方向.
1 | SELECT |
SQL 的优点
- 表达非常清晰, 比如说这段
SQL明显就是为了查询三个字段, 又比如说这段SQL明显能看到是想查询年龄大于 10 岁的条目
SQL 的缺点
- 想想一下 3 层嵌套的
SQL, 维护起来应该挺力不从心的吧 - 试想一下, 如果使用
SQL来实现机器学习算法, 也挺为难的吧
SQL 擅长数据分析和通过简单的语法表示查询, 命令式操作适合过程式处理和算法性的处理. 在 Spark 出现之前, 对于结构化数据的查询和处理, 一个工具一向只能支持 SQL 或者命令式, 使用者被迫要使用多个工具来适应两种场景, 并且多个工具配合起来比较费劲.
而 Spark 出现了以后, 统一了两种数据处理范式, 是一种革新性的进步.
过程
因为 SQL 是数据分析领域一个非常重要的范式, 所以 Spark 一直想要支持这种范式, 而伴随着一些决策失误, 这个过程其实还是非常曲折的

Hive
解决的问题
Hive实现了SQL on Hadoop, 使用MapReduce执行任务简化了MapReduce任务新的问题
Hive的查询延迟比较高, 原因是使用 MapReduce 做调度
Shark
解决的问题
Shark改写Hive的物理执行计划, 使用 Spark 作业代替 MapReduce 执行物理计划使用列式内存存储以上两点使得Shark的查询效率很高新的问题
Shark重用了Hive的SQL解析, 逻辑计划生成以及优化, 所以其实可以认为Shark只是把Hive的物理执行替换为了Spark作业执行计划的生成严重依赖Hive, 想要增加新的优化非常困难Hive使用MapReduce执行作业, 所以 Hive 是进程级别的并行, 而Spark是线程级别的并行, 所以Hive中很多线程不安全的代码不适用于Spark
由于以上问题, Shark 维护了 Hive 的一个分支, 并且无法合并进主线, 难以为继
SparkSQL
解决的问题
Spark SQL使用Hive解析SQL生成AST语法树, 将其后的逻辑计划生成, 优化, 物理计划都自己完成, 而不依赖Hive执行计划和优化交给优化器Catalyst内建了一套简单的SQL解析器, 可以不使用HQL, 此外, 还引入和DataFrame这样的DSL API, 完全可以不依赖任何Hive的组件Shark只能查询文件,Spark SQL可以直接降查询作用于RDD, 这一点是一个大进步新的问题
对于初期版本的
SparkSQL, 依然有挺多问题, 例如只能支持SQL的使用, 不能很好的兼容命令式, 入口不够统一等
Dataset
SparkSQL 在 2.0 时代, 增加了一个新的 API, 叫做 Dataset, Dataset 统一和结合了 SQL 的访问和命令式 API 的使用, 这是一个划时代的进步
在 Dataset 中可以轻易的做到使用 SQL 查询并且筛选数据, 然后使用命令式 API 进行探索式分析
注意
SparkSQL 不只是一个 SQL 引擎, SparkSQL 也包含了一套对 结构化数据的命令式 API, 事实上, 所有 Spark中常见的工具, 都是依赖和依照于 SparkSQL 的 API 设计的
总结
SparkSQL 是一个为了支持 SQL 而设计的工具, 但同时也支持命令式的 API 底层是rdd
2 sparkSql应用场景
| 定义 | 特点 | 举例 | |
|---|---|---|---|
| 结构化数据 | 有固定的 Schema |
有预定义的 Schema |
关系型数据库的表 |
| 半结构化数据 | 没有固定的 Schema, 但是有结构 |
没有固定的 Schema, 有结构信息, 数据一般是自描述的 |
指一些有结构的文件格式, 例如 JSON |
| 非结构化数据 | 没有固定 Schema, 也没有结构 |
没有固定 Schema, 也没有结构 |
指文档图片之类的格式 |
结构化数据 如关系型数据库
一般指数据有固定的 Schema, 例如在用户表中, name 字段是 String 型, 那么每一条数据的 name 字段值都可以当作 String 来使用
1 | +----+--------------+---------------------------+-------+---------+ |
半结构化数据
一般指的是数据没有固定的 Schema, 但是数据本身是有结构的
1 | { |
没有固定 Schema
指的是半结构化数据是没有固定的 Schema 的, 可以理解为没有显式指定 Schema
比如说一个用户信息的 JSON 文件, 第一条数据的 phone_num 有可能是 String, 第二条数据虽说应该也是 String, 但是如果硬要指定为 BigInt, 也是有可能的
因为没有指定 Schema, 没有显式的强制的约束
有结构
虽说半结构化数据是没有显式指定 Schema 的, 也没有约束, 但是半结构化数据本身是有有隐式的结构的, 也就是数据自身可以描述自身
例如 JSON 文件, 其中的某一条数据是有字段这个概念的, 每个字段也有类型的概念, 所以说 JSON 是可以描述自身的, 也就是数据本身携带有元信息
SparkSQL 处理什么数据的问题?
Spark的RDD主要用于处理 非结构化数据 和 半结构化数据SparkSQL主要用于处理 结构化数据
SparkSQL 相较于 RDD 的优势在哪?
SparkSQL提供了更好的外部数据源读写支持- 因为大部分外部数据源是有结构化的, 需要在
RDD之外有一个新的解决方案, 来整合这些结构化数据源
- 因为大部分外部数据源是有结构化的, 需要在
SparkSQL提供了直接访问列的能力- 因为
SparkSQL主要用做于处理结构化数据, 所以其提供的API具有一些普通数据库的能力
- 因为
总结
虽然Sparksql是基于rdd的但是sparkSql的速度比rdd快很多,sparksql可以针对结构化数据的API进行更好的操作
SparkSQL 适用于处理结构化数据的场景
SparkSQL是一个即支持SQL又支持命令式数据处理的工具SparkSQL的主要适用场景是处理结构化数据
二 SparkSql 处理数据
1 | case class Person(name: String, age: Int) |
SparkSQL 中有一个新的入口点, 叫做 SparkSession
SparkSQL 中有一个新的类型叫做 Dataset
SparkSQL 有能力直接通过字段名访问数据集, 说明 SparkSQL 的 API 中是携带 Schema 信息的
SparkSession
SparkContext作为RDD的创建者和入口, 其主要作用有如下两点创建
RDD, 主要是通过读取文件创建RDD监控和调度任务, 包含了一系列组件, 例如DAGScheduler,TaskSheduler为什么无法使用
SparkContext作为SparkSQL的入口?SparkContext在读取文件的时候, 是不包含Schema信息的, 因为读取出来的是RDD``SparkContext在整合数据源如Cassandra,JSON,Parquet等的时候是不灵活的, 而DataFrame和Dataset一开始的设计目标就是要支持更多的数据源SparkContext的调度方式是直接调度RDD, 但是一般情况下针对结构化数据的访问, 会先通过优化器优化一下
所以 SparkContext 确实已经不适合作为 SparkSQL 的入口, 所以刚开始的时候 Spark 团队为 SparkSQL 设计了两个入口点, 一个是 SQLContext 对应 Spark 标准的 SQL 执行, 另外一个是 HiveContext 对应 HiveSQL 的执行和 Hive 的支持.
在 Spark 2.0 的时候, 为了解决入口点不统一的问题, 创建了一个新的入口点 SparkSession, 作为整个 Spark 生态工具的统一入口点, 包括了 SQLContext, HiveContext, SparkContext 等组件的功能
新的入口应该有什么特性?
能够整合
SQLContext,HiveContext,SparkContext,StreamingContext等不同的入口点为了支持更多的数据源, 应该完善读取和写入体系同时对于原来的入口点也不能放弃, 要向下兼容
2.1 DataSet 和 DataFrame
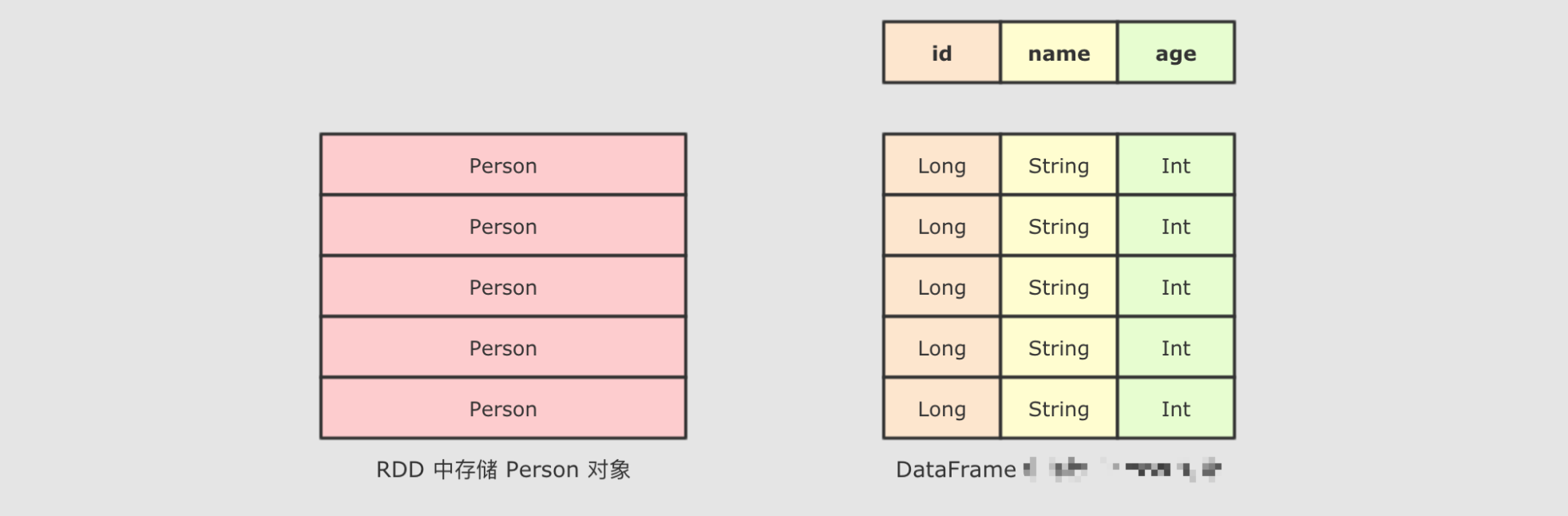
1 | SparkSQL` 最大的特点就是它针对于结构化数据设计, 所以 `SparkSQL` 应该是能支持针对某一个字段的访问的, 而这种访问方式有一个前提, 就是 `SparkSQL` 的数据集中, 要 **包含结构化信息**, 也就是俗称的 `Schema |
而 SparkSQL 对外提供的 API 有两类, 一类是直接执行 SQL, 另外一类就是命令式. SparkSQL 提供的命令式 API 就是 DataFrame 和 Dataset, 暂时也可以认为 DataFrame 就是 Dataset, 只是在不同的 API 中返回的是 Dataset 的不同表现形式
1 | // RDD |
例如:
1 | case class Person(name: String, age: Int) |
以往使用 SQL 肯定是要有一个表的, 在 Spark 中, 并不存在表的概念, 但是有一个近似的概念, 叫做 DataFrame, 所以一般情况下要先通过 DataFrame 或者 Dataset 注册一张临时表, 然后使用 SQL 操作这张临时表
总结
SparkSQL 提供了 SQL 和 命令式 API 两种不同的访问结构化数据的形式, 并且它们之间可以无缝的衔接
命令式 API 由一个叫做 Dataset 的组件提供, 其还有一个变形, 叫做 DataFrame
三 Catalyst 优化器
3.1 rdd与sparksql 的对比
rdd运行流程
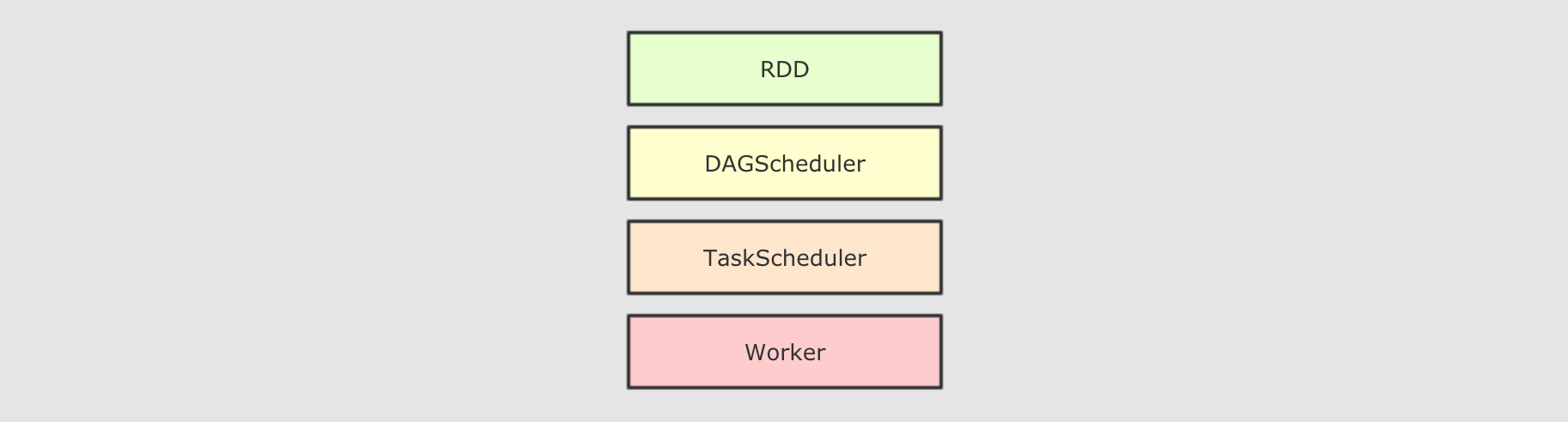
大致运行步骤
先将
RDD解析为由Stage组成的DAG, 后将Stage转为Task直接运行问题
任务会按照代码所示运行, 依赖开发者的优化, 开发者的会在很大程度上影响运行效率
解决办法
创建一个组件, 帮助开发者修改和优化代码, 但是这在
RDD上是无法实现的
为什么 RDD 无法自我优化?
RDD没有Schema信息RDD可以同时处理结构化和非结构化的数据
SparkSQL
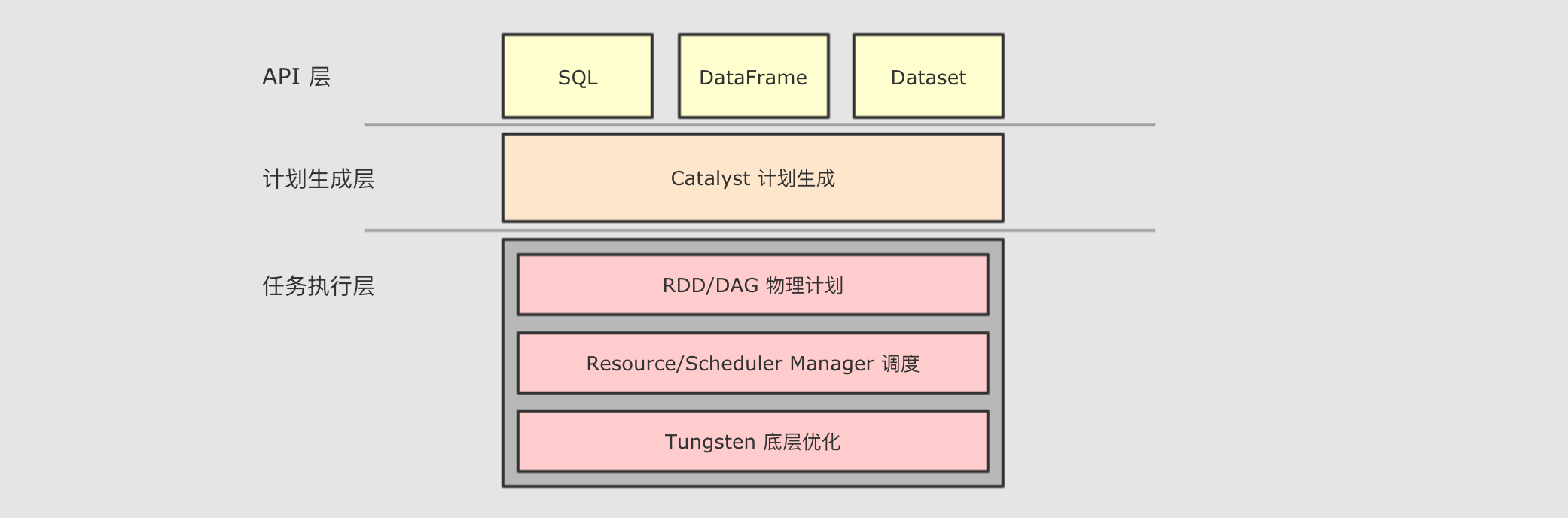
和 RDD 不同, SparkSQL 的 Dataset 和 SQL 并不是直接生成计划交给集群执行, 而是经过了一个叫做 Catalyst 的优化器, 这个优化器能够自动帮助开发者优化代码
也就是说, 在 SparkSQL 中, 开发者的代码即使不够优化, 也会被优化为相对较好的形式去执行
为什么
SparkSQL提供了这种能力?首先,
SparkSQL大部分情况用于处理结构化数据和半结构化数据, 所以SparkSQL可以获知数据的Schema, 从而根据其Schema来进行优化
3.2 Catalyst
为了解决过多依赖 Hive 的问题, SparkSQL 使用了一个新的 SQL 优化器替代 Hive 中的优化器, 这个优化器就是 Catalyst, 整个 SparkSQL 的架构大致如下

API层简单的说就是Spark会通过一些API接受SQL语句- 收到
SQL语句以后, 将其交给Catalyst,Catalyst负责解析SQL, 生成执行计划等 Catalyst的输出应该是RDD的执行计划- 最终交由集群运行

Step 1 : 解析 SQL, 并且生成 AST (抽象语法树)
Step 2 : 在 AST 中加入元数据信息, 做这一步主要是为了一些优化, 例如 col = col 这样的条件,
Step 3 : 对已经加入元数据的 AST, 输入优化器, 进行优化, 从两种常见的优化开始, 简单介绍
列值裁剪
Column Pruning, 在谓词下推后,people表之上的操作只用到了id列, 所以可以把其它列裁剪掉, 这样可以减少处理的数据量, 从而优化处理速度谓词下推
Predicate Pushdown, 将Filter这种可以减小数据集的操作下推, 放在Scan的位置, 这样可以减少操作时候的数据量还有其余很多优化点, 大概一共有一二百种, 随着
SparkSQL的发展, 还会越来越多, 感兴趣的同学可以继续通过源码了解, 源码在org.apache.spark.sql.catalyst.optimizer.Optimizer
Step 4 : 上面的过程生成的 AST 其实最终还没办法直接运行, 这个 AST 叫做 逻辑计划, 结束后, 需要生成 物理计划, 从而生成 RDD 来运行
- 在生成
物理计划的时候, 会经过成本模型对整棵树再次执行优化, 选择一个更好的计划 - 在生成
物理计划以后, 因为考虑到性能, 所以会使用代码生成, 在机器中运行
总结
1 | SparkSQL 和 RDD 不同的主要点是在于其所操作的数据是结构化的, 提供了对数据更强的感知和分析能力, 能够对代码进行更深层的优化, 而这种能力是由一个叫做 Catalyst 的优化器所提供的 |
四 DataSet的特点
1 | class DataSetDemo { |
Dataset 是什么?
1 | 是一个强类型, 并且类型安全的数据容器, 并且提供了结构化查询 `API` 和类似 `RDD` 一样的命令式 `API |
即使使用 Dataset 的命令式 API, 执行计划也依然会被优化
Dataset 具有 RDD 的方便, 同时也具有 DataFrame 的性能优势, 并且 Dataset 还是强类型的, 能做到类型安全.
1 | scala> spark.range(1).filter('id === 0).explain(true) |
dataSet底层
Dataset 最底层处理的是对象的序列化形式, 通过查看 Dataset 生成的物理执行计划, 也就是最终所处理的 RDD, 就可以判定 Dataset 底层处理的是什么形式的数据
1 | val dataset: Dataset[People] = spark.createDataset(Seq(People("zhangsan", 9), People("lisi", 15))) |
1 | dataset.queryExecution.toRdd` 这个 `API` 可以看到 `Dataset` 底层执行的 `RDD`, 这个 `RDD` 中的范型是 `InternalRow`, `InternalRow` 又称之为 `Catalyst Row`, 是 `Dataset` 底层的数据结构, 也就是说, 无论 `Dataset` 的范型是什么, 无论是 `Dataset[Person]` 还是其它的, 其最底层进行处理的数据结构都是 `InternalRow |
所以, Dataset 的范型对象在执行之前, 需要通过 Encoder 转换为 InternalRow, 在输入之前, 需要把 InternalRow 通过 Decoder 转换为范型对象
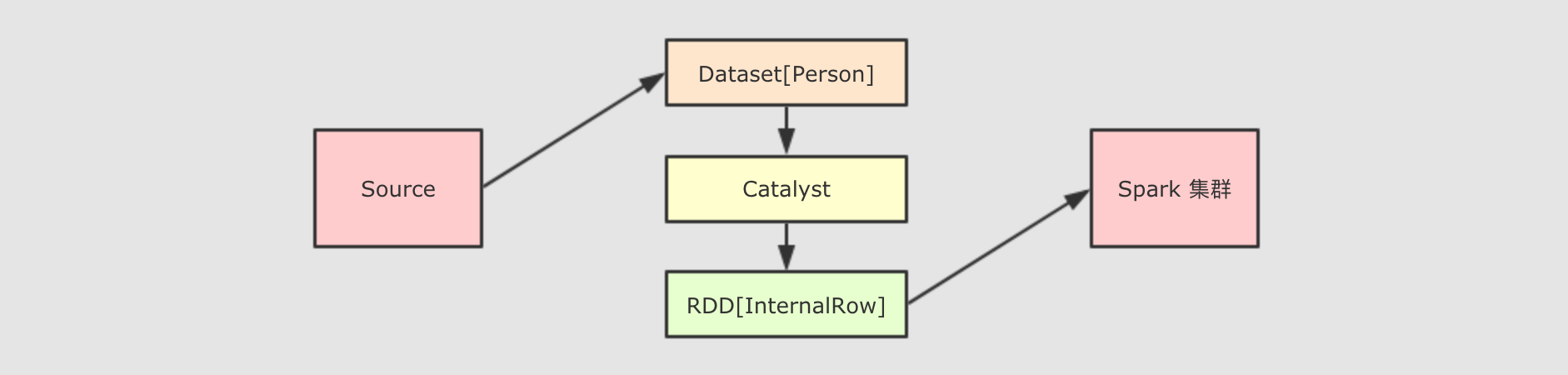
可以获取 Dataset 对应的 RDD 表示
1 | 在 Dataset 中, 可以使用一个属性 rdd 来得到它的 RDD 表示, 例如 Dataset[T] → RDD[T] |
可以看到 (1) 对比 (2) 对了两个步骤, 这两个步骤的本质就是将 Dataset 底层的 InternalRow 转为 RDD 中的对象形式, 这个操作还是会有点重的, 所以慎重使用 rdd 属性来转换 Dataset 为 RDD
总结
Dataset是一个新的Spark组件, 其底层还是RDDDataset提供了访问对象中某个特定字段的能力, 不用像RDD一样每次都要针对整个对象做操作**Dataset和RDD不同, 如果想把Dataset[T]转为RDD[T], 则需要对Dataset底层的InternalRow做转换, 是一个比较重量级的操作** 一般不对dataset转换为rdd
五 DataFrame的特点
DataFrame 是 SparkSQL 中一个表示关系型数据库中 表 的函数式抽象, 其作用是让 Spark 处理大规模结构化数据的时候更加容易. 一般 DataFrame 可以处理结构化的数据, 或者是半结构化的数据, 因为这两类数据中都可以获取到 Schema 信息. 也就是说 DataFrame 中有 Schema 信息, 可以像操作表一样操作 DataFrame.
DataFrame 由两部分构成, 一是 row 的集合, 每个 row 对象表示一个行, 二是描述 DataFrame 结构的 Schema
DataFrame 支持 SQL 中常见的操作, 例如: select, filter, join, group, sort, join 等
1 | val spark: SparkSession = new sql.SparkSession.Builder() |
通过隐式转换创建 DataFrame
这种方式本质上是使用 SparkSession 中的隐式转换来进行的
1 | val spark: SparkSession = new sql.SparkSession.Builder() |

根据源码可以知道, toDF 方法可以在 RDD 和 Seq 中使用
通过集合创建 DataFrame 的时候, 集合中不仅可以包含样例类, 也可以只有普通数据类型, 后通过指定列名来创建
1 | val spark: SparkSession = new sql.SparkSession.Builder() |
通过外部集合创建 DataFrame
1 | val spark: SparkSession = new sql.SparkSession.Builder() |
总结
1 | DataFrame 是一个类似于关系型数据库表的函数式组件 |
dataset与dataframe的异同
1DataFrame 就是 Dataset
Dataset中可以使用列来访问数据,DataFrame也可以Dataset的执行是优化的,DataFrame也是Dataset具有命令式API, 同时也可以使用SQL来访问,DataFrame也可以使用这两种不同的方式访问
1 | DataFrame 是 Dataset 的一种特殊情况, 也就是说 DataFrame 是 Dataset[Row] 的别名 |
2 语义不同
第一点: DataFrame 表达的含义是一个支持函数式操作的 表, 而 Dataset 表达是是一个类似 RDD 的东西, Dataset 可以处理任何对象
第二点: DataFrame 中所存放的是 Row 对象, 而 Dataset 中可以存放任何类型的对象
第三点: DataFrame 的操作方式和 Dataset 是一样的, 但是对于强类型操作而言, 它们处理的类型不同
第三点: DataFrame 只能做到运行时类型检查, Dataset 能做到编译和运行时都有类型检查
row是什么
1 | Row 对象表示的是一个 行 |
3 DataFrame 和 Dataset 之间可以非常简单的相互转换
1 | val spark: SparkSession = new sql.SparkSession.Builder() |
总结
1 | DataFrame 就是 Dataset, 他们的方式是一样的, 也都支持 API 和 SQL 两种操作方式 |
六 读写
1读文件: DataFrameReader
1 |
|
组件:
schema :结构信息, 因为 Dataset 是有结构的, 所以在读取数据的时候, 就需要有 Schema 信息, 有可能是从外部数据源获取的, 也有可能是指定的
option:连接外部数据源的参数, 例如 JDBC 的 URL, 或者读取 CSV 文件是否引入 Header 等
format:外部数据源的格式, 例如 csv, jdbc, json 等
总结
1 | spark.read 可以获取 SparkSQL 中的外部数据源访问框架 DataFrameReader |
2 写文件DataFrameWriter
对于 ETL 来说, 数据保存和数据读取一样重要, 所以 SparkSQL 中增加了一个新的数据写入框架, 叫做 DataFrameWriter
1 | //写文件 |
组件:
source |
写入目标, 文件格式等, 通过 format 方法设定 |
|---|---|
mode |
写入模式, 例如一张表已经存在, 如果通过 DataFrameWriter 向这张表中写入数据, 是覆盖表呢, 还是向表中追加呢? 通过 mode方法设定 |
extraOptions |
外部参数, 例如 JDBC 的 URL, 通过 options, option 设定 |
partitioningColumns |
类似 Hive 的分区, 保存表的时候使用, 这个地方的分区不是 RDD的分区, 而是文件的分区, 或者表的分区, 通过 partitionBy 设定 |
bucketColumnNames |
类似 Hive 的分桶, 保存表的时候使用, 通过 bucketBy 设定 |
sortColumnNames |
用于排序的列, 通过 sortBy 设定 |
mode 指定了写入模式, 例如覆盖原数据集, 或者向原数据集合中尾部添加等
SaveMode.ErrorIfExists |
"error" |
将 DataFrame 保存到 source 时, 如果目标已经存在, 则报错 |
|---|---|---|
SaveMode.Append |
"append" |
将 DataFrame 保存到 source 时, 如果目标已经存在, 则添加到文件或者 Table中 |
SaveMode.Overwrite |
"overwrite" |
将 DataFrame 保存到 source 时, 如果目标已经存在, 则使用 DataFrame 中的数据完全覆盖目标 |
SaveMode.Ignore |
"ignore" |
将 DataFrame 保存到 source 时, 如果目标已经存在, 则不会保存 DataFrame 数据, 并且也不修改目标数据集, 类似于 CREATE TABLE IF NOT EXISTS |
总结
1 | DataFrameReader, Writer 中也有 format, options, 另外 schema 是包含在 DataFrame 中的 |
3 读写parquet格式文件
parquet简介
在ETL中 spark经常为T 的职务 就是清洗和数据转换
E 加载数据 L 落地数据
为了能够保存比较复杂的数据, 并且保证性能和压缩率, 通常使用 Parquet 是一个比较不错的选择.
所以外部系统收集过来的数据, 有可能会使用 Parquet, 而 Spark 进行读取和转换的时候, 就需要支持对 Parquet 格式的文件的支持.
1 |
|
4 写入parquet的时候可以指定分区
这个地方指的分区是类似 Hive 中表分区的概念, 而不是 RDD 分布式分区的含义
在读取常见文件格式的时候, Spark 会自动的进行分区发现, 分区自动发现的时候, 会将文件名中的分区信息当作一列. 例如 如果按照性别分区, 那么一般会生成两个文件夹 gender=male 和 gender=female, 那么在使用 Spark 读取的时候, 会自动发现这个分区信息, 并且当作列放入创建的 DataFrame 中
使用代码证明这件事可以有两个步骤, 第一步先读取某个分区的单独一个文件并打印其 Schema 信息, 第二步读取整个数据集所有分区并打印 Schema 信息, 和第一步做比较就可以确定
1 |
|
SparkSession 中有关 Parquet 的配置
spark.sql.parquet.binaryAsString |
false |
一些其他 Parquet 生产系统, 不区分字符串类型和二进制类型, 该配置告诉 SparkSQL 将二进制数据解释为字符串以提供与这些系统的兼容性 |
|---|---|---|
spark.sql.parquet.int96AsTimestamp |
true |
一些其他 Parquet 生产系统, 将 Timestamp 存为 INT96, 该配置告诉 SparkSQL 将 INT96 解析为 Timestamp |
spark.sql.parquet.cacheMetadata |
true |
打开 Parquet 元数据的缓存, 可以加快查询静态数据 |
spark.sql.parquet.compression.codec |
snappy |
压缩方式, 可选 uncompressed, snappy, gzip, lzo |
spark.sql.parquet.mergeSchema |
false |
当为 true 时, Parquet 数据源会合并从所有数据文件收集的 Schemas 和数据, 因为这个操作开销比较大, 所以默认关闭 |
spark.sql.optimizer.metadataOnly |
true |
如果为 true, 会通过原信息来生成分区列, 如果为 false 则就是通过扫描整个数据集来确定 |
总结
1 | Spark 不指定 format 的时候默认就是按照 Parquet 的格式解析文件 |
5 读写json格式的文件
在业务系统中, JSON 是一个非常常见的数据格式, 在前后端交互的时候也往往会使用 JSON, 所以从业务系统获取的数据很大可能性是使用 JSON 格式, 所以就需要 Spark 能够支持 JSON 格式文件的读取
就是etl 中的e
dataframe与json的相互转换
1 | //读写json文件 |
读写json
1 | //读写json文件 |
frame.repartition(1)//必须写为第一个
如果不重新分区, 则会为 DataFrame 底层的 RDD 的每个分区生成一个文件, 为了保持只有一个输出文件, 所以重新分区
保存为 JSON 格式的文件有一个细节需要注意, 这个 JSON 格式的文件中, 每一行是一个独立的 JSON, 但是整个文件并不只是一个 JSON 字符串, 所以这种文件格式很多时候被成为 JSON Line 文件, 有时候后缀名也会变为 jsonl
Spark 读取 JSON Line 文件的时候, 会自动的推断类型信息
假设业务系统通过 Kafka 将数据流转进入大数据平台, 这个时候可能需要使用 RDD 或者 Dataset 来读取其中的内容, 这个时候一条数据就是一个 JSON 格式的字符串, 如何将其转为 DataFrame 或者 Dataset[Object] 这样具有 Schema 的数据集呢? 使用如下代码就可以
1 | val spark: SparkSession = ... |
总结
JSON通常用于系统间的交互,Spark经常要读取JSON格式文件, 处理, 放在另外一处- 使用
DataFrameReader和DataFrameWriter可以轻易的读取和写入JSON, 并且会自动处理数据类型信息
6 访问hive
和一个文件格式不同, Hive 是一个外部的数据存储和查询引擎, 所以如果 Spark 要访问 Hive 的话, 就需要先整合 Hive
只需整合MetaStore, 元数据存储 因为SparkSQL 内置了 HiveSQL 的支持, 所以无需整合查询引擎
首先要开启Hive 的MetaStore
Hive 的 MetaStore 是一个 Hive 的组件, 一个 Hive 提供的程序, 用以保存和访问表的元数据, 整个 Hive 的结构大致如下
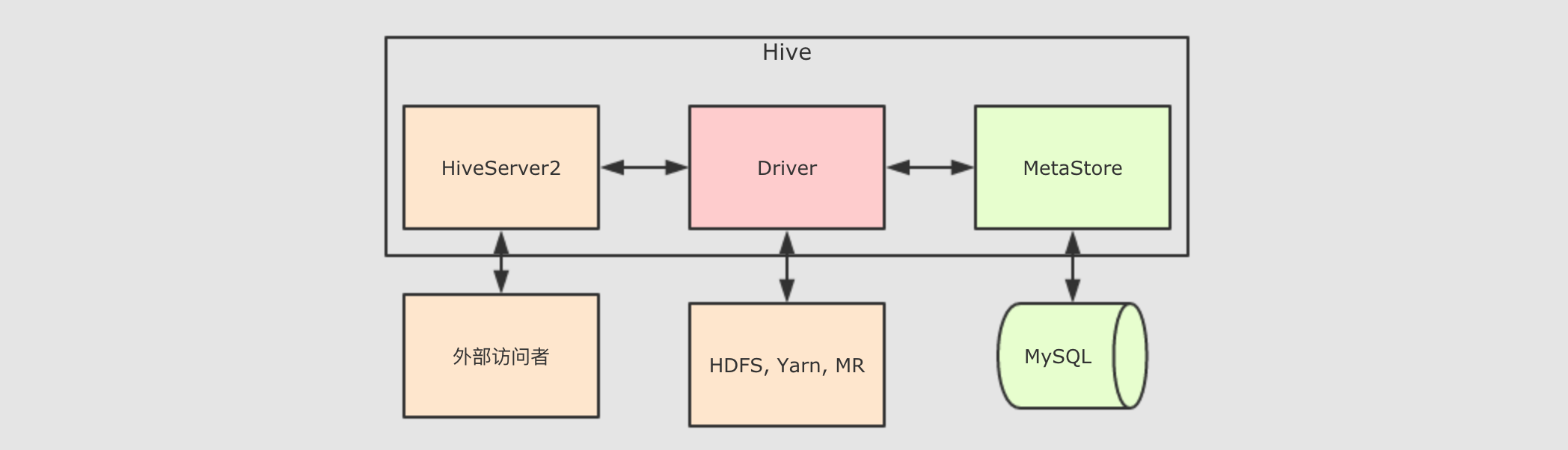
其实 Hive 中主要的组件就三个, HiveServer2 负责接受外部系统的查询请求, 例如 JDBC, HiveServer2 接收到查询请求后, 交给 Driver 处理, Driver 会首先去询问 MetaStore 表在哪存, 后 Driver 程序通过 MR 程序来访问 HDFS从而获取结果返回给查询请求者
而 Hive 的 MetaStore 对 SparkSQL 的意义非常重大, 如果 SparkSQL 可以直接访问 Hive 的 MetaStore, 则理论上可以做到和 Hive 一样的事情, 例如通过 Hive 表查询数据
而 Hive 的 MetaStore 的运行模式有三种
内嵌
Derby数据库模式这种模式不必说了, 自然是在测试的时候使用, 生产环境不太可能使用嵌入式数据库, 一是不稳定, 二是这个
Derby是单连接的, 不支持并发Local模式Local和Remote都是访问MySQL数据库作为存储元数据的地方, 但是Local模式的MetaStore没有独立进程, 依附于HiveServer2的进程Remote模式和
Loca模式一样, 访问MySQL数据库存放元数据, 但是Remote的MetaStore运行在独立的进程中
我们显然要选择 Remote 模式, 因为要让其独立运行, 这样才能让 SparkSQL 一直可以访问
hive 开启metastore
修改hive-site.xml
1 | <property> |
启动 hive的metastore后台
1 | nohup /export/servers/hive/bin/hive --service metastore 2>&1 >> /var/log.log & |
即使不去整合 MetaStore, Spark 也有一个内置的 MateStore, 使用 Derby 嵌入式数据库保存数据, 但是这种方式不适合生产环境, 因为这种模式同一时间只能有一个 SparkSession 使用, 所以生产环境更推荐使用 Hive 的 MetaStore
SparkSQL 整合 Hive 的 MetaStore 主要思路就是要通过配置能够访问它, 并且能够使用 HDFS 保存 WareHouse, 这些配置信息一般存在于 Hadoop 和 HDFS 的配置文件中, 所以可以直接拷贝 Hadoop 和 Hive 的配置文件到 Spark 的配置目录
把一下三个配置文件copy进spark/conf目录下
1 | Spark 需要 hive-site.xml 的原因是, 要读取 Hive 的配置信息, 主要是元数据仓库的位置等信息 |
注意如果不希望通过拷贝文件的方式整合 Hive, 也可以在 SparkSession 启动的时候, 通过指定 Hive 的 MetaStore 的位置来访问, 但是更推荐整合的方式
7 访问hive表
1 | 在 Hive 中创建表 |
在 Hive 中创建表
第一步, 需要先将文件上传到集群中, 使用如下命令上传到 HDFS 中
1 | hdfs dfs -mkdir -p /dataset |
第二步, 使用 Hive 或者 Beeline 执行如下 SQL
1 | CREATE DATABASE IF NOT EXISTS spark_integrition; |
通过 SparkSQL 查询 Hive 的表
查询 Hive 中的表可以直接通过 spark.sql(…) 来进行, 可以直接在其中访问 Hive 的 MetaStore, 前提是一定要将 Hive 的配置文件拷贝到 Spark 的 conf 目录
1 | scala> spark.sql("use spark_integrition") |
通过 SparkSQL 创建 Hive 表
通过 SparkSQL 可以直接创建 Hive 表, 并且使用 LOAD DATA 加载数据
1 | val createTableStr = |
目前 SparkSQL 支持的文件格式有 sequencefile, rcfile, orc, parquet, textfile, avro, 并且也可以指定 serde 的名称
使用 SparkSQL 处理数据并保存进 Hive 表
前面都在使用 SparkShell 的方式来访问 Hive, 编写 SQL, 通过 Spark 独立应用的形式也可以做到同样的事, 但是需要一些前置的步骤, 如下
Step 1: 导入
Maven依赖1
2
3
4
5<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
Step 2: 配置
SparkSession如果希望使用
SparkSQL访问Hive的话, 需要做两件事开启
SparkSession的Hive支持经过这一步配置,
SparkSQL才会把SQL语句当作HiveSQL来进行解析设置
WareHouse的位置虽然
hive-stie.xml中已经配置了WareHouse的位置, 但是在Spark 2.0.0后已经废弃了hive-site.xml中设置的hive.metastore.warehouse.dir, 需要在SparkSession中设置WareHouse的位置设置
MetaStore的位置1
2
3
4
5
6
7val spark = SparkSession
.builder()
.appName("hive example")
.config("spark.sql.warehouse.dir", "hdfs://node01:8020/dataset/hive") //设置 WareHouse 的位置
.config("hive.metastore.uris", "thrift://node01:9083") //设置 MetaStore 的位置
.enableHiveSupport() //开启hive支持
.getOrCreate()
配置好了以后, 就可以通过 DataFrame 处理数据, 后将数据结果推入 Hive 表中了, 在将结果保存到 Hive 表的时候, 可以指定保存模式
1 | val schema = StructType( |
8 访问MySQL jdbc
1 | 通过 SQL 操作 MySQL 的表 |
准备MySQL环境
Step 1: 连接
MySQL数据库在
MySQL所在的主机上执行如下命令1
mysql -u root -p
Step 2: 创建
Spark使用的用户登进
MySQL后, 需要先创建用户1
CREATE USER 'spark'@'%' IDENTIFIED BY 'Spark123!';
Step 3: 创建库和表
1
2
3
4
5
6
7
8
9
10
11
12
13CREATE DATABASE spark_test;
USE spark_test;
CREATE TABLE IF NOT EXISTS `student`(
`id` INT AUTO_INCREMENT,
`name` VARCHAR(100) NOT NULL,
`age` INT NOT NULL,
`gpa` FLOAT,
PRIMARY KEY ( `id` )
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
赋予权限
1 | GRANT ALL ON spark_test.* TO 'spark'@'%'; |
1 写数据
其实在使用 SparkSQL 访问 MySQL 是通过 JDBC, 那么其实所有支持 JDBC 的数据库理论上都可以通过这种方式进行访问
在使用 JDBC 访问关系型数据的时候, 其实也是使用 DataFrameReader, 对 DataFrameReader 提供一些配置, 就可以使用 Spark 访问 JDBC, 有如下几个配置可用
| 属性 | 含义 |
|---|---|
url |
要连接的 JDBC URL |
dbtable |
要访问的表, 可以使用任何 SQL 语句中 from 子句支持的语法 |
fetchsize |
数据抓取的大小(单位行), 适用于读的情况 |
batchsize |
数据传输的大小(单位行), 适用于写的情况 |
isolationLevel |
事务隔离级别, 是一个枚举, 取值 NONE, READ_COMMITTED, READ_UNCOMMITTED, REPEATABLE_READ, SERIALIZABLE, 默认为 READ_UNCOMMITTED |
1 | val spark = SparkSession |
运行
本地运行导入依赖
1 | <dependency> |
如果使用 Spark submit 或者 Spark shell 来运行任务, 需要通过 --jars 参数提交 MySQL 的 Jar 包, 或者指定 --packages 从 Maven 库中读取
1 | bin/spark-shell --packages mysql:mysql-connector-java:5.1.47 --repositories http://maven.aliyun.com/nexus/content/groups/public/ |
2 读数据
读取 MySQL 的方式也非常的简单, 只是使用 SparkSQL 的 DataFrameReader 加上参数配置即可访问
1 | spark.read.format("jdbc") |
默认情况下读取 MySQL 表时, 从 MySQL 表中读取的数据放入了一个分区, 拉取后可以使用 DataFrame 重分区来保证并行计算和内存占用不会太高, 但是如果感觉 MySQL 中数据过多的时候, 读取时可能就会产生 OOM, 所以在数据量比较大的场景, 就需要在读取的时候就将其分发到不同的 RDD 分区
| 属性 | 含义 |
|---|---|
partitionColumn |
指定按照哪一列进行分区, 只能设置类型为数字的列, 一般指定为 ID |
lowerBound, upperBound |
确定步长的参数, lowerBound - upperBound 之间的数据均分给每一个分区, 小于 lowerBound 的数据分给第一个分区, 大于 upperBound 的数据分给最后一个分区 |
numPartitions |
分区数量 |
1 | spark.read.format("jdbc") |
有时候可能要使用非数字列来作为分区依据, Spark 也提供了针对任意类型的列作为分区依据的方法
1 | val predicates = Array( |
SparkSQL 中并没有直接提供按照 SQL 进行筛选读取数据的 API 和参数, 但是可以通过 dbtable 来曲线救国, dbtable 指定目标表的名称, 但是因为 dbtable 中可以编写 SQL, 所以使用子查询即可做到
1 | spark.read.format("jdbc") |
七 dataset的基础操作
1 有类型操作
转换
map t=> r
flatMap t=> list
mapPartitions list => list 数据必须可以放在内存才可以使用 数据不可以大到每个分区都存不下 不然会内存溢出 00m 堆溢出
transfrom 针对数据集 直接针对dataset进行操作 返回和参数都是dataset
as 最常见操作 dataframe转为dataset 如读取数据的时候是dataframereader 大部分都是dataframe的数据类型 可以使用as 完成操作
1 | import spark.implicits._ |
过滤:
filter 用来按照条件过滤数据集 返回值为boolean
聚合
groupByKey
grouByKey 算子的返回结果是 KeyValueGroupedDataset, 而不是一个 Dataset, 所以必须要先经过 KeyValueGroupedDataset 中的方法进行聚合, 再转回 Dataset, 才能使用 Action 得出结果
其实这也印证了分组后必须聚合的道理
切分
randomSplit
1 | /*randomSplit 会按照传入的权重随机将一个 Dataset 分为多个 Dataset, 传入 randomSplit 的数组有多少个权重, 最终就会生成多少个 Dataset, 这些权重的加倍和应该为 1, 否则将被标准化*/ |
sample 随机抽样
1 | val ds = spark.range(15) |
排序
orderBy orderBy 配合 Column 的 API, 可以实现正反序排列
1 | import spark.implicits._ |
sort 其实 orderBy 是 sort 的别名, 所以它们所实现的功能是一样的
1 | Person("lisi", 15)).toDS() |
分区
coalesce
1 | /*减少分区, 此算子和 RDD 中的 coalesce 不同, Dataset 中的 coalesce 只能减少分区数, coalesce 会直接创建一个逻辑操作, 并且设置 Shuffle 为 false*/ |
repartitions
1 | /*repartitions 有两个作用, 一个是重分区到特定的分区数, 另一个是按照某一列来分区, 类似于 SQL 中的 DISTRIBUTE BY*/ |
去重
dropDuplicates 使用 dropDuplicates 可以去掉某一些列中重复的行
1 | import spark.implicits._ |
distinct 当 dropDuplicates 中没有传入列名的时候, 其含义是根据所有列去重, dropDuplicates() 方法还有一个别名, 叫做 distinct 所以, 使用 distinct 也可以去重, 并且只能根据所有的列来去重
1 | import spark.implicits._ |
集合操作:
except 差集
intersect 交集
union 并集
limit 限制结果集数量
1 | val ds = spark.range(1, 10) |
2无类型转换
选择
select select 用来选择某些列出现在结果集中
1 | import spark.implicits._ |
selectExpr 在 SQL 语句中, 经常可以在 select 子句中使用 count(age), rand() 等函数, 在 selectExpr 中就可以使用这样的 SQL 表达式, 同时使用 select 配合 expr函数也可以做到类似的效果
1 | import spark.implicits._ |
withColumn
通过 Column 对象在 Dataset 中创建一个新的列或者修改原来的列
1 | import spark.implicits._ |
withColumnRenamed 修改列名
1 | import spark.implicits._ |
剪除
drop
剪除某个列
1 | import spark.implicits._ |
聚合
groupBy
按照给定的行进行分组
1 | import spark.implicits._ |
3 Column 对象
Column 表示了 Dataset 中的一个列, 并且可以持有一个表达式, 这个表达式作用于每一条数据, 对每条数据都生成一个值, 列的操作属于细节, 但是又比较常见, 会在很多算子中配合出现
无绑定创建
1 单引号 ' 在 Scala 中是一个特殊的符号, 通过 ' 会生成一个 Symbol 对象, Symbol 对象可以理解为是一个字符串的变种, 但是比字符串的效率高很多, 在 Spark 中, 对 Scala 中的 Symbol 对象做了隐式转换, 转换为一个 ColumnName 对象, ColumnName 是 Column 的子类, 所以在 Spark 中可以如下去选中一个列
1 | val spark = SparkSession.builder().appName("column").master("local[6]").getOrCreate() |
2 $ 符号也是一个隐式转换, 同样通过 spark.implicits 导入, 通过 $ 可以生成一个 Column 对象
1 | val spark = SparkSession.builder().appName("column").master("local[6]").getOrCreate() |
3 col SparkSQL 提供了一系列的函数, 可以通过函数实现很多功能, 在后面课程中会进行详细介绍, 这些函数中有两个可以帮助我们创建 Column 对象, 一个是 col, 另外一个是 column
1 | val spark = SparkSession.builder().appName("column").master("local[6]").getOrCreate() |
4 column
1 |
|
有绑定创建
1 Dataset.col
前面的 Column 对象创建方式所创建的 Column 对象都是 Free 的, 也就是没有绑定任何 Dataset, 所以可以作用于任何 Dataset, 同时, 也可以通过 Dataset 的 col 方法选择一个列, 但是这个 Column 是绑定了这个 Dataset 的, 所以只能用于创建其的 Dataset 上
1 | val spark = SparkSession.builder().appName("column").master("local[6]").getOrCreate() |
2 Dataset.apply
1 | val spark = SparkSession.builder().appName("column").master("local[6]").getOrCreate() |
别名和转换
as[type]通过 as[Type] 的形式可以将一个列中数据的类型转为 Type 类型
1 | personDF.select(col("age").as[Long]).show() |
as(name)
1 | 通过 as(name) 的形式使用 as 方法可以为列创建别名 |
添加列
withColumn
1 | 通过 Column 在添加一个新的列时候修改 Column 所代表的列的数据 |
操作
like
1 | //通过 Column 的 API, 可以轻松实现 SQL 语句中 LIKE 的功能 |
isin
1 | //通过 Column 的 API, 可以轻松实现 SQL 语句中 ISIN 的功能 |
sort
1 | //在排序的时候, 可以通过 Column 的 API 实现正反序 |
4 缺失值处理
缺失值 null NaN 空字符串 等
产生原因
Spark 大多时候处理的数据来自于业务系统中, 业务系统中可能会因为各种原因, 产生一些异常的数据
例如说因为前后端的判断失误, 提交了一些非法参数. 再例如说因为业务系统修改 MySQL 表结构产生的一些空值数据等. 总之在业务系统中出现缺失值其实是非常常见的一件事, 所以大数据系统就一定要考虑这件事.
常见缺失值有两种
null,NaN等特殊类型的值, 某些语言中null可以理解是一个对象, 但是代表没有对象,NaN是一个数字, 可以代表不是数字针对这一类的缺失值,
Spark提供了一个名为DataFrameNaFunctions特殊类型来操作和处理"Null","NA"," "等解析为字符串的类型, 但是其实并不是常规字符串数据针对这类字符串, 需要对数据集进行采样, 观察异常数据, 总结经验, 各个击破
DataFrameNaFunctions
1
2
3
4
5
6
7
8
9
10
11//DataFrameNaFunctions 使用 Dataset 的 na 函数来获取
val df = ...
val naFunc: DataFrameNaFunctions = df.na
//当数据集中出现缺失值的时候, 大致有两种处理方式, 一个是丢弃, 一个是替换为某值, DataFrameNaFunctions 中包含一系列针对空值数据的方案
DataFrameNaFunctions.drop //可以在当某行中包含 null 或 NaN 的时候丢弃此行
DataFrameNaFunctions.fill //可以在将 null 和 NaN 充为其它值
DataFrameNaFunctions.replace //可以把 null 或 NaN 替换为其它值, 但是和 fill 略有一些不同, 这个方法针对值来进行替换处理null和NaN
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34首先要将数据读取出来, 此次使用的数据集直接存在 NaN, 在指定 Schema 后, 可直接被转为 Double.NaN
val schema = StructType(
List(
StructField("id", IntegerType),
StructField("year", IntegerType),
StructField("month", IntegerType),
StructField("day", IntegerType),
StructField("hour", IntegerType),
StructField("season", IntegerType),
StructField("pm", DoubleType)
)
)
val df = spark.read
.option("header", value = true)
.schema(schema)
.csv("dataset/beijingpm_with_nan.csv")
//对于缺失值的处理一般就是丢弃和填充
//丢弃包含 null 和 NaN 的行
//当某行数据所有值都是 null 或者 NaN 的时候丢弃此行
df.na.drop("all").show()
当某行中特定列所有值都是 null 或者 NaN 的时候丢弃此行
df.na.drop("all", List("pm", "id")).show()
当某行数据任意一个字段为 null 或者 NaN 的时候丢弃此行
df.na.drop().show()
df.na.drop("any").show()
当某行中特定列任意一个字段为 null 或者 NaN 的时候丢弃此行
df.na.drop(List("pm", "id")).show()
df.na.drop("any", List("pm", "id")).show()填充包含
null和NaN的列1
2
3
4
5
6
7
8
9
10
11填充所有包含 null 和 NaN 的列
df.na.fill(0).show()
填充特定包含 null 和 NaN 的列
df.na.fill(0, List("pm")).show()
根据包含 null 和 NaN 的列的不同来填充
import scala.collection.JavaConverters._
df.na.fill(Map[String, Any]("pm" -> 0).asJava).show使用是parkSQl处理异常字符串
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22//读取数据集, 这次读取的是最原始的那个 PM 数据集
val df = spark.read
.option("header", value = true)
.csv("dataset/BeijingPM20100101_20151231.csv")
//使用函数直接转换非法的字符串
df.select('No as "id", 'year, 'month, 'day, 'hour, 'season,
when('PM_Dongsi === "NA", 0)
.otherwise('PM_Dongsi cast DoubleType)
.as("pm"))
.show()
//使用 where 直接过滤
df.select('No as "id", 'year, 'month, 'day, 'hour, 'season, 'PM_Dongsi)
.where('PM_Dongsi =!= "NA")
.show()
//使用 DataFrameNaFunctions 替换, 但是这种方式被替换的值和新值必须是同类型
df.select('No as "id", 'year, 'month, 'day, 'hour, 'season, 'PM_Dongsi)
.na.replace("PM_Dongsi", Map("NA" -> "NaN"))
.show()