一概述
1 流计算与批量计算
批量计算 数据已经存在, 一次性读取所有的数据进行批量处理 hdfs > spark sql > hdfs
流计算 数据源源不断的进来, 经过处理后落地 设备> kafka > SparkStreaming > hbase等
2 流和批 架构
流和批都是有意义的, 有自己的应用场景, 那么如何结合流和批呢? 如何在同一个系统中使用这两种不同的解决方案呢?
混合架构
混合架构的名字叫做 Lambda 架构, 混合架构最大的特点就是将流式计算和批处理结合起来,后在进行查询的时候分别查询流系统和批系统, 最后将结果合并在一起
一般情况下 Lambda 架构分三层
批处理层: 批量写入, 批量读取
服务层: 分为两个部分, 一部分对应批处理层, 一部分对应速度层
速度层: 随机读取, 随即写入, 增量计算
优点
- 兼顾优点, 在批处理层可以全量查询和分析, 在速度层可以查询最新的数据
- 速度很快, 在大数据系统中, 想要快速的获取结果是非常困难的, 因为高吞吐量和快速返回结果往往很难兼得, 例如
Impala和Hive,Hive能进行非常大规模的数据量的处理,Impala能够快速的查询返回结果, 但是很少有一个系统能够兼得两点,Lambda使用多种融合的手段从而实现
缺点
Lambda是一个非常反人类的设计, 因为我们需要在系统中不仅维护多套数据层, 还需要维护批处理和流式处理两套框架, 这非常困难, 一套都很难搞定, 两套带来的运维问题是是指数级提升的
流失架构
流式架构常见的叫做 Kappa 结构, 是 Lambda 架构 的一个变种, 其实本质上就是删掉了批处理
优点
- 非常简单
- 效率很高, 在存储系统的发展下, 很多存储系统已经即能快速查询又能批量查询了, 所以
Kappa 架构在新时代还是非常够用的
问题:
丧失了一些 Lambda 的优秀特点
3 SparkStreaming
| 特点 | 说明 |
|---|---|
Spark Streaming 是 Spark Core API 的扩展 |
Spark Streaming 具有类似 RDD 的 API, 易于使用, 并可和现有系统共用相似代码,,,,一个非常重要的特点是, Spark Streaming 可以在流上使用基于 Spark 的机器学习和流计算, 是一个一站式的平台 |
Spark Streaming 具有很好的整合性 |
Spark Streaming 可以从 Kafka, Flume, TCP 等流和队列中获取数据,,,,Spark Streaming 可以将处理过的数据写入文件系统, 常见数据库中 |
Spark Streaming 是微批次处理模型 |
微批次处理的方式不会有长时间运行的 Operator, 所以更易于容错设计,,,,,,,微批次模型能够避免运行过慢的服务, 实行推测执行 |
TCP三次握手回顾
1
Client 向 Server 发送 SYN(j), 进入 SYN_SEND 状态等待 Server 响应
2
Server 收到 Client 的 SYN(j) 并发送确认包 ACK(j + 1), 同时自己也发送一个请求连接的 SYN(k) 给 Client, 进入 SYN_RECV 状态等待 Client 确认
3
Client 收到 Server 的 ACK + SYN, 向 Server 发送连接确认 ACK(k + 1), 此时, Client 和 Server 都进入 ESTABLISHED 状态, 准备数据发送
netcat
Netcat简写nc, 命令行中使用nc命令调用Netcat是一个非常常见的Socket工具, 可以使用nc建立Socket server也可以建立Socket clientnc -l建立Socket server,l是listen监听的意思nc host port建立Socket client, 并连接到某个Socket server一台虚拟机 nc -lk 1567 另一台复制的虚拟机 nc localhost 1567 两台可以通信
4 小试牛刀
使用 Spark Streaming 程序和 Socket server 进行交互
创建maven工程
pom 依赖
1 | <properties> |
1 | //Spark Streaming 是微小的批处理 并不是实时流, 而是按照时间切分小批量, 一个一个的小批量处理 |
可以在本地运行 也可以在集群运行
1 | 集群运行 |
5 总结
注意点:
1Spark Streaming 并不是真正的来一条数据处理一条
Spark Streaming 的处理机制叫做小批量, 英文叫做 mini-batch, 是收集了一定时间的数据后生成 RDD, 后针对 RDD 进行各种转换操作, 这个原理提现在如下两个地方
2Spark Streaming 中至少要有两个线程
在使用 spark-submit 启动程序的时候, 不能指定一个线程
- 主线程被阻塞了, 等待程序运行
- 需要开启后台线程获取数据
创建StreamingContext
StreamingContext是Spark Streaming程序的入口- 在创建
StreamingContext的时候, 必须要指定两个参数, 一个是SparkConf, 一个是流中生成RDD的时间间隔 StreamingContext提供了如下功能- 创建
DStream, 可以通过读取Kafka, 读取Socket消息, 读取本地文件等创建一个流, 并且作为整个DAG中的InputDStream RDD遇到Action才会执行, 但是DStream不是,DStream只有在StreamingContext.start()后才会开始接收数据并处理数据- 使用
StreamingContext.awaitTermination()等待处理被终止 - 使用
StreamingContext.stop()来手动的停止处理
- 创建
- 在使用的时候有如下注意点
- 同一个
Streaming程序中, 只能有一个StreamingContext - 一旦一个
Context已经启动 (start), 则不能添加新的数据源 **
- 同一个
算子
这些算子类似 RDD, 也会生成新的 DStream
这些算子操作最终会落到每一个 DStream 生成的 RDD 中
reduceByKey 这个算子需要特别注意, 这个聚合并不是针对于整个流, 而是针对于某个批次的数据
二原理
1Spark Streaming 的特点
Spark Streaming会源源不断的处理数据, 称之为流计算Spark Streaming并不是实时流, 而是按照时间切分小批量, 一个一个的小批量处理Spark Streaming是流计算, 所以可以理解为数据会源源不断的来, 需要长时间运行
2Spark Streaming 是按照时间切分小批量
1 | Spark Streaming` 中的编程模型叫做 `DStream`, 所有的 `API` 都从 `DStream` 开始, 其作用就类似于 `RDD` 之于 `Spark Core |
可以理解为 DStream 是一个管道, 数据源源不断的从这个管道进去, 被处理, 再出去
但是需要注意的是, DStream 并不是严格意义上的实时流, 事实上, DStream 并不处理数据, 而是处理 RDD
Spark Streaming是小批量处理数据, 并不是实时流Spark Streaming对数据的处理是按照时间切分为一个又一个小的RDD, 然后针对RDD进行处理
RDD 中针对数据的处理是使用算子, 在 DStream 中针对数据的操作也是算子
难道 DStream 会把算子的操作交给 RDD 去处理? 如何交?
3 Spark Streaming 是流计算, 流计算的数据是无限的
无限的数据一般指的是数据不断的产生, 比如说运行中的系统, 无法判定什么时候公司会倒闭, 所以也无法断定数据什么时候会不再产生数据
那就会产生一个问题
如何不简单的读取数据, 如何应对数据量时大时小?
如何数据是无限的, 意味着可能要一直运行下去
那就会又产生一个问题
Spark Streaming不会出错吗? 数据出错了怎么办?
四个问题:
DStream如何对应RDD?- 如何切分
RDD? - 如何读取数据?
- 如何容错?
4 DAG的定义
RDD 和 DStream 的 DAG
rdd的wordcount :
1 | val textRDD = sc.textFile(...) |
DStream的wordcount
1 | val lines: DStream[String] = ssc.socketTextStream(...) |
1RDD 和 DStream 的区别
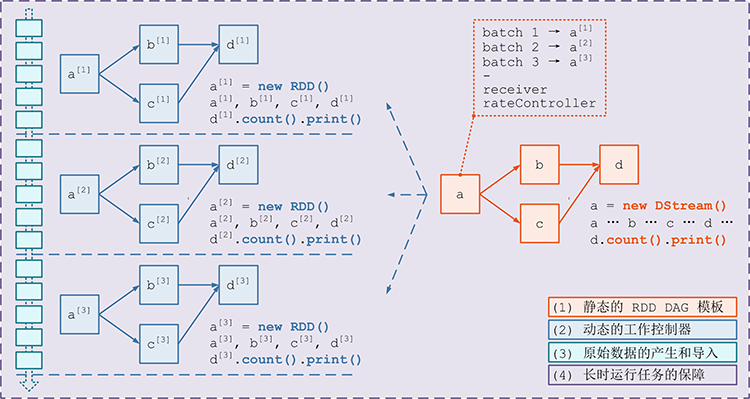
DStream的数据是不断进入的,RDD是针对一个数据的操作- 像
RDD一样,DStream也有不同的子类, 通过不同的算子生成 - 一个
DStream代表一个数据集, 其中包含了针对于上一个数据的操作 DStream根据时间切片, 划分为多个RDD, 针对DStream的计算函数, 会作用于每一个DStream中的RDD
2DStream 如何形式 DAG
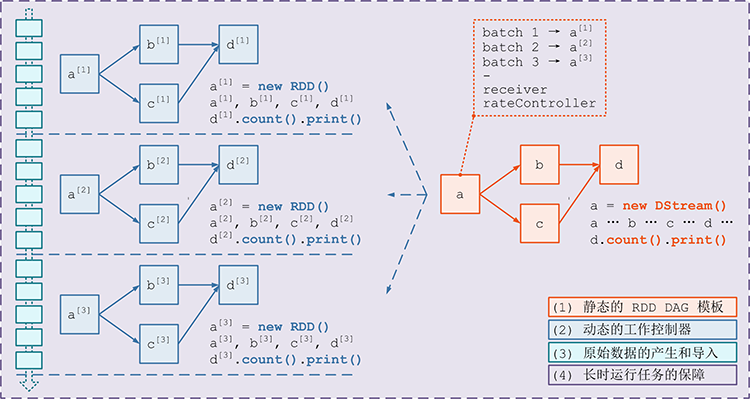
- 每个
DStream都有一个关联的DStreamGraph对象 DStreamGraph负责表示DStream之间的的依赖关系和运行步骤DStreamGraph中会单独记录InputDStream和OutputDStream
3切分流, 生成小批量
静态和动态
DStream对应RDDDStreamGraph表示DStream之间的依赖关系和运行流程, 相当于RDD通过DAGScheduler所生成的RDD DAG
RDD 的运行分为逻辑计划和物理计划
- 逻辑计划就是
RDD之间依赖关系所构成的一张有向无环图 - 后根据这张
DAG生成对应的TaskSet调度到集群中运行,
但是在 DStream 中则不能这么简单的划分, 因为 DStream 中有一个非常重要的逻辑, 需要按照时间片划分小批量
- 在
Streaming中,DStream类似RDD, 生成的是静态的数据处理过程, 例如一个DStream中的数据经过map转为其它模样 - 在
Streaming中,DStreamGraph类似DAG, 保存了这种数据处理的过程
上述两点, 其实描述的是静态的一张 DAG, 数据处理过程, 但是 Streaming 是动态的, 数据是源源不断的来的
所以, 在 DStream 中, 静态和动态是两个概念, 有不同的流程
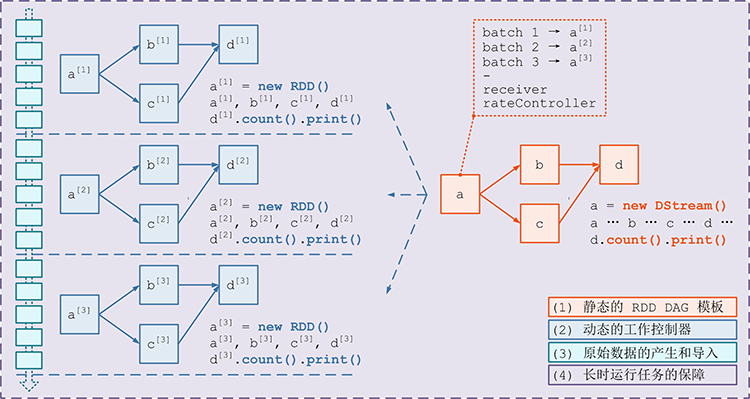
DStreamGraph将DStream联合起来, 生成DStream之间的DAG, 这些DStream之间的关系是相互依赖的关系, 例如一个DStream经过map转为另外一个DStream- 但是把视角移动到
DStream中来看,DStream代表了源源不断的RDD的生成和处理, 按照时间切片, 所以一个DStream DAG又对应了随着时间的推进所产生的无限个RDD DAG
动态生成 RDD DAG 的过程
RDD DAG 的生成是按照时间来切片的, Streaming 会维护一个 Timer, 固定的时间到达后通过如下五个步骤生成一个 RDD DAG 后调度执行
- 通知
Receiver将收到的数据暂存, 并汇报存储的元信息, 例如存在哪, 存了什么 - 通过
DStreamGraph复制出一套新的RDD DAG - 将数据暂存的元信息和
RDD DAG一同交由JobScheduler去调度执行 - 提交结束后, 对系统当前的状态
Checkpoint
4数据的产生和导入
1Receiver
在 Spark Streaming 中一个非常大的挑战是, 很多外部的队列和存储系统都是分块的, RDD 是分区的, 在读取外部数据源的时候, 会用不同的分区对照外部系统的分片, 例如
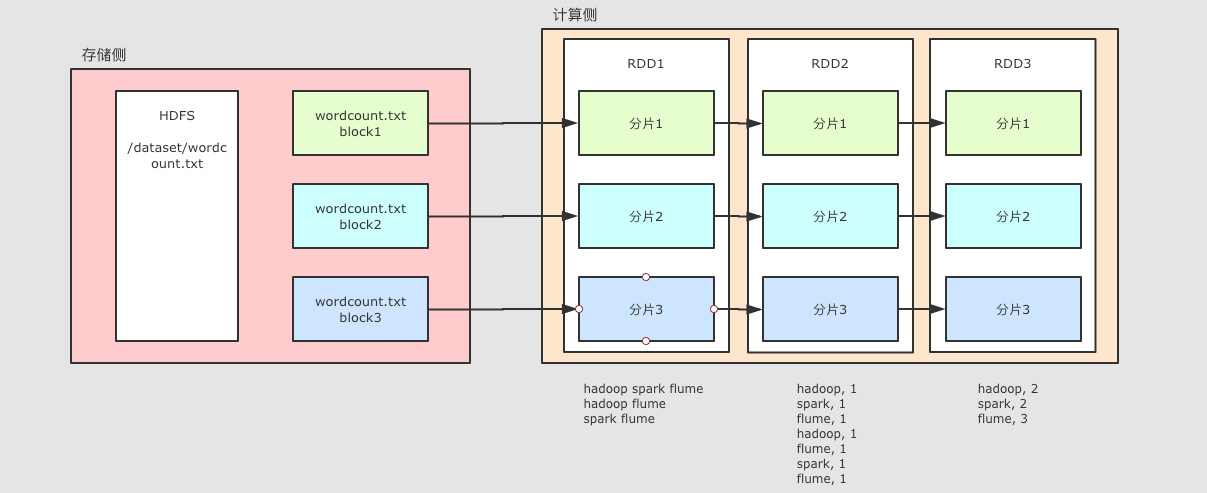
不仅 RDD, DStream 中也面临这种挑战
DStream 中是 RDD 流, 只是 RDD 的分区对应了 Kafka 的分区就可以了吗?
答案是不行, 因为需要一套单独的机制来保证并行的读取外部数据源, 这套机制叫做 Receiver
Receiver 的结构
为了保证并行获取数据, 对应每一个外部数据源的分区, 所以 Receiver 也要是分布式的, 主要分为三个部分
Receiver是一个对象, 是可以有用户自定义的获取逻辑对象, 表示了如何获取数据Receiver Tracker是Receiver的协调和调度者, 其运行在Driver上Receiver Supervisor被Receiver Tracker调度到不同的几点上分布式运行, 其会拿到用户自定义的Receiver对象, 使用这个对象来获取外部数据
Receiver 的执行过程
- 在
Spark Streaming程序开启时候,Receiver Tracker使用JobScheduler分发Job到不同的节点, 每个Job包含一个Task, 这个Task就是Receiver Supervisor, 这个部分的源码还挺精彩的, 其实是复用了通用的调度逻辑 ReceiverSupervisor启动后运行Receiver实例Receiver启动后, 就将持续不断地接收外界数据, 并持续交给ReceiverSupervisor进行数据存储ReceiverSupervisor持续不断地接收到Receiver转来的数据, 并通过BlockManager来存储数据- 获取的数据存储完成后发送元数据给
Driver端的ReceiverTracker, 包含数据块的id, 位置, 数量, 大小 等信息
2 Direct
direct
使用Kafka低层次API实现的.
特点:
- 会创建和Kafka分区数一样的RDD分区.提升性能
- 使用checkpoint将分区/偏移量信息进行保存
0:2342344 - 因为直接根据分区id+偏移量获取消息,也解决了偏移量不一致问题.
总结:
reciver
使用Kafka高层次API实现,
特点:
- 启动一个Reciver进行消费,启动和Kafka分区数一样的线程数进行消费,所以性能提升不大
- 为了确保数据安全,需要启用WAL预写日志功能,数据会在HDFS备份一份,Kafka里面默认也有一份,所以数据会被重复保存
- 偏移量是在zookeeper上面存储的,因为信息不同步,有可能引起数据的重复消费问题.
5 容错
因为要非常长时间的运行, 对于任何一个流计算系统来说, 容错都是非常致命也非常重要的一环, 在 Spark Streaming 中, 大致提供了如下的容错手段
1 热备
这行代码中的 StorageLevel.MEMORY_AND_DISK_SER 的作用是什么? 其实就是热备份
- 当 Receiver 获取到数据要存储的时候, 是交给 BlockManager 存储的
- 如果设置了
StorageLevel.MEMORY_AND_DISK_SER, 则意味着BlockManager不仅会在本机存储, 也会发往其它的主机进行存储, 本质就是冗余备份 - 如果某一个计算失败了, 通过冗余的备份, 再次进行计算即可
这是默认的容错手段
2 冷备
冷备在 Spark Streaming 中的手段叫做 WAL (预写日志)
- 当
Receiver获取到数据后, 会交给BlockManager存储 - 在存储之前先写到
WAL中,WAL中保存了Redo Log, 其实就是记录了数据怎么产生的, 以便于恢复的时候通过Log恢复 - 当出错的时候, 通过
Redo Log去重放数据
3 重放
- 有一些上游的外部系统是支持重放的, 比如说
Kafka Kafka可以根据Offset来获取数据- 当
SparkStreaming处理过程中出错了, 只需要通过Kafka再次读取即可
三操作
1 中间状态
需求: 统计整个流中, 所有出现的单词数量, 而不是一个批中的数量
在小试牛刀中 只能统计某个时间段内的单词数量, 因为 reduceByKey 只能作用于某一个 RDD, 不能作用于整个流
如果想要求单词总数该怎么办?
以使用状态来记录中间结果, 从而每次来一批数据, 计算后和中间状态求和, 于是就完成了总数的统计
- 使用
updateStateByKey可以做到这件事 updateStateByKey会将中间状态存入CheckPoint中
1 | //使用中间状态(updateStateByKey)记录结果 可以统计整个流中出现的单词数量 等操作 |
2 window操作
需求: 计算过 30s 的单词总数, 每 10s 更新一次
1 | //使用窗口Window操作 需求 计算过 30s 的单词总数, 每 10s 更新一次 |
窗口时间
在
window函数中, 接收两个参数windowDuration窗口长度,window函数会将多个DStream中的RDD按照时间合并为一个, 那么窗口长度配置的就是将多长时间内的RDD合并为一个slideDuration滑动间隔, 比较好理解的情况是直接按照某个时间来均匀的划分为多个window, 但是往往需求可能是统计最近xx分内的所有数据, 一秒刷新一次, 那么就需要设置滑动窗口的时间间隔了, 每隔多久生成一个window
滑动时间的问题
- 如果
windowDuration > slideDuration, 则在每一个不同的窗口中, 可能计算了重复的数据 - 如果
windowDuration < slideDuration, 则在每一个不同的窗口之间, 有一些数据为能计算进去
但是其实无论谁比谁大, 都不能算错, 例如, 我的需求有可能就是统计一小时内的数据, 一天刷新两次
- 如果