Flink
目标:
- 批数据处理编程ExecutionEnviroment
- 流数据处理编程StreamExecutionEnviroment
- Flink原理
- checkpoint、watermark
Flink是什么
Flink是什么
Flink是一个分布式计算引擎 MapReduce Tez Spark Storm
- 同时支持流计算和批处理,Spark也能做批和流
- 和Spark不同, Flink是使用流的思想做批, Spark是采用做批的思想做流
Flink的优势
- 和Hadoop相比, Flink使用内存进行计算, 速度明显更优
- 和同样使用内存的Spark相比, Flink对于流的计算是实时的, 延迟更低
- 和同样使用实时流的Storm相比, Flink明显具有更优秀的API, 以及更多的支持, 并且支持批量计算
速度
测试环境:
1.CPU:7000个;2.内存:单机128GB;
3.版本:Hadoop 2.3.0,Spark 1.4,Flink 0.9
4.数据:800MB,8GB,8TB;
5.算法:K-means:以空间中K个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次
更新各聚类中心的值,直至得到最好的聚类结果。6.迭代:K=10,3组数据
纵坐标是秒,横坐标是次数
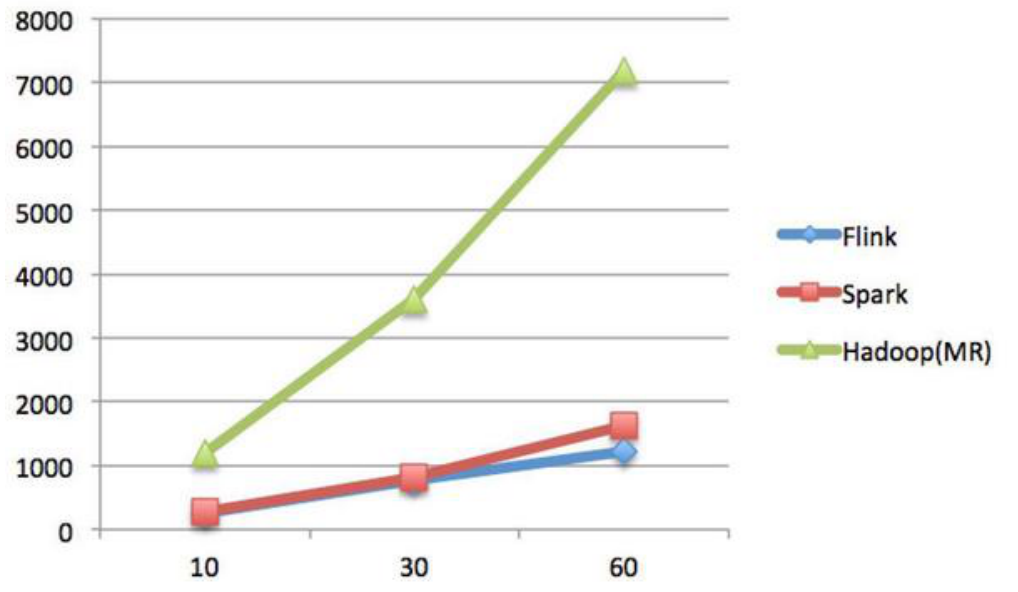
结论:
Spark和Flink全部都运行在Hadoop YARN上,性能为Flink > Spark > Hadoop(MR),迭代次数越多越明显,性能上,Flink优于Spark和Hadoop最主要的原因是Flink支持增量迭代,具有对迭代自动优化的功能
- 在单机上, Storm大概能达到30万条/秒的吞吐量, Flink的吞吐量大概是Storm得3-5倍.在阿里中,Flink集群能达到每秒能处理17亿数据量,一天可处理上万亿条数据
- 在单机上, Flink消息处理的延迟大概在50毫秒左右, 这个数据大概是Spark的3-5倍
Flink的发展现状
08年Flink在德国柏林大学
14年Apache立为顶级项目.阿里15年开始使用
- Flink在很多公司的生产环境中得到了使用, 例如: ebay, 腾讯, 阿里, 亚马逊, 华为等
- Blink
Flink的母公司被阿里全资收购, 阿里一直致力于Flink在国内的推广使用
Flink的适用场景
- 零售业和市场营销(运营)
- 物联网,5G 300M/s 延迟低 50ms 100ms 无人驾驶
华人运通:hiphi1 10万辆 560个 没200ms采集一次数据 2800条
- 电信业
- 银行和金融业
对比Flink、Spark、Storm
Flink、Spark Streaming、Storm都可以进行实时计算,但各有特点
计算框架 处理模型 保证次数 容错机制 延时 吞吐量 Storm native(数据进入立即处理) At-least-once
至少一次ACK机制 低 低 Spark Streaming micro-batching Exactly-once 基于RDD和 checkpoint 中 高 Flink native、micro-batching Exactly-once checkpoint(Flink快照) 低 高
Flink的体系架构
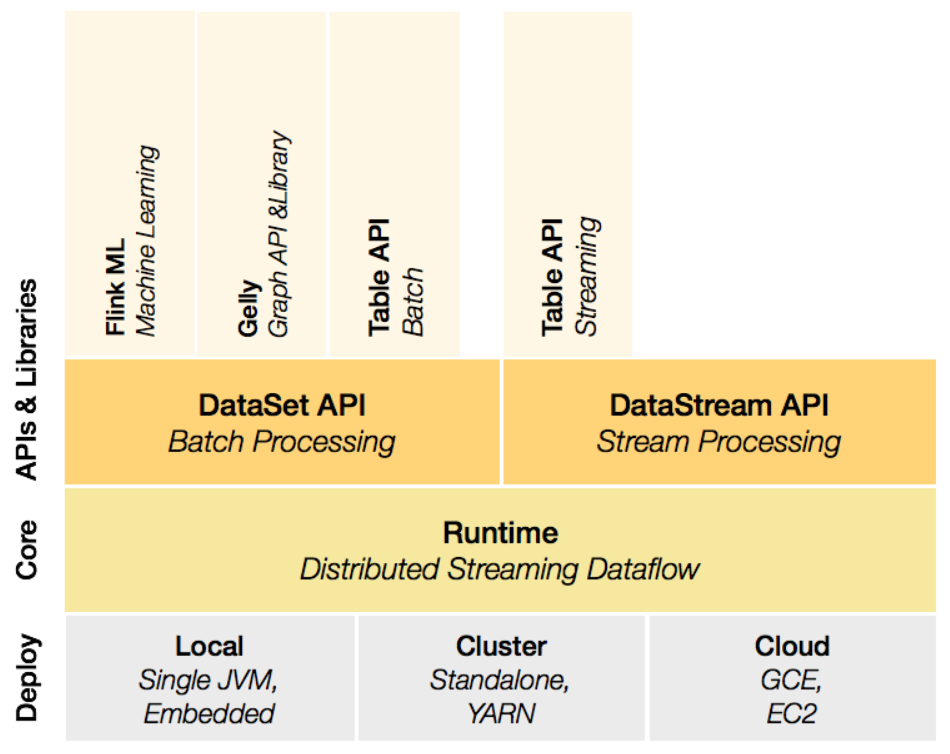
有界流和无界流
无界流:意思很明显,只有开始没有结束。必须连续的处理无界流数据,也即是在事件注入之后立即要对其
进行处理。不能等待数据到达了再去全部处理,因为数据是无界的并且永远不会结束数据注入。处理无界流数
据往往要求事件注入的时候有一定的顺序性,例如可以以事件产生的顺序注入,这样会使得处理结果完整。
有界流:也即是有明确的开始和结束的定义。有界流可以等待数据全部注入完成了再开始处理。注入的顺序
不是必须的了,因为对于一个静态的数据集,我们是可以对其进行排序的。有界流的处理也可以称为批处
理。
Data Streams ,Flink认为有界数据集是无界数据流的一种特例,所以说有界数据集也是一种数据流,事件流
也是一种数据流。Everything is streams ,即Flink可以用来处理任何的数据,可以支持批处理、流处理、
AI、MachineLearning等等。
Stateful Computations,即有状态计算。有状态计算是最近几年来越来越被用户需求的一个功能。比如说一个
网站一天内访问UV数,那么这个UV数便为状态。Flink提供了内置的对状态的一致性的处理,即如果任务发生
了Failover,其状态不会丢失、不会被多算少算,同时提供了非常高的性能。
其它特点:
性能优秀(尤其在流计算领域)
高可扩展性
支持容错
纯内存式的计算引擎,做了内存管理方面的大量优化
支持eventime 的处理
支持超大状态的Job(在阿里巴巴中作业的state大小超过TB的是非常常见的)
支持exactly-once 的处理。
Flink安装及任务提交
三种:
1 local(本地)——单机模式,一般不使用
2 standalone——独立模式,Flink自带集群,开发测试环境使用
3 yarn——计算资源统一由Hadoop YARN管理,生产测试环境使用
- Standalone单机模式
- Standalone集群模式
- Standalone的高可用HA模式
Standalone方式安装
将Flink解压到指定目录,
进入到Flink目录,使用以下命令启动Flink
1
./bin/start-cluster.sh
打开浏览器,使用
http://服务器地址:8081,进入到Flink的Web UI中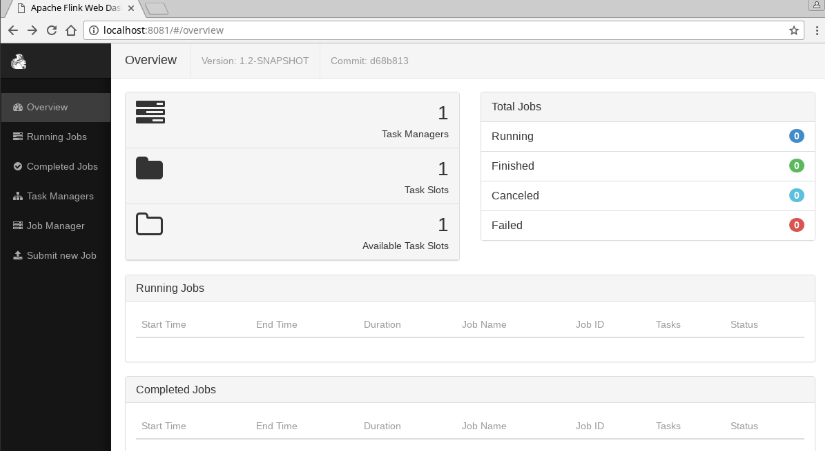
standalone集群方式安装
下载Flink,并解压到指定目录
配置
conf/flink-conf.yaml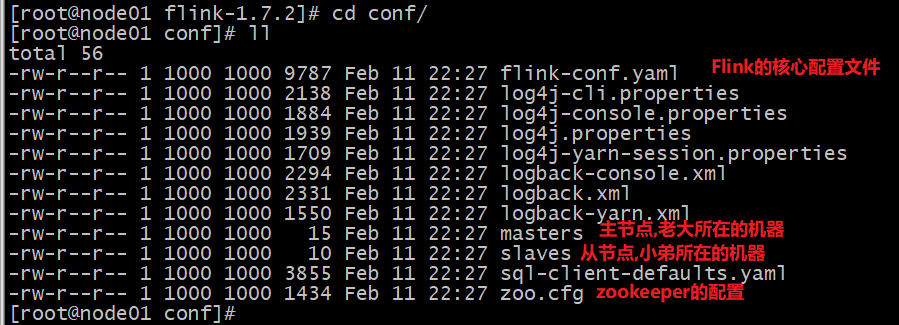
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# 配置Master的机器名(IP地址)
jobmanager.rpc.address: node01
# 配置Master的端口号
jobmanager.rpc.port: 6123
# 配置Master的堆大小(默认MB)
jobmanager.heap.size: 1024m
# 配置每个TaskManager的堆大小(默认MB)
taskmanager.heap.size: 1024m
# 配置每个TaskManager可以运行的槽
taskmanager.numberOfTaskSlots: 4
# 配置每个taskmanager生成的临时文件夹
taskmanager.tmp.dirs: /export/data/flink
# 配置webui启动的机器名(IP地址)
web.address: node01
# 配置webui启动的端口号
rest.port: 8081
# 是否支持通过web ui提交Flink作业
web.submit.enable: true配置
masters
1 | node01:8081 |
配置
slaves文件1
2
3node01
node02
node03分发Flink到集群中的其他节点
1
2scp -r flink-1.7.2 node02:$PWD
scp -r flink-1.7.2 node03:$PWD启动集群
1
./bin/start-cluster.sh

浏览Flink UI界面
1
http://node01:8081
Flink主界面:通过主界面可以查看到当前的TaskManager和多少个Slots
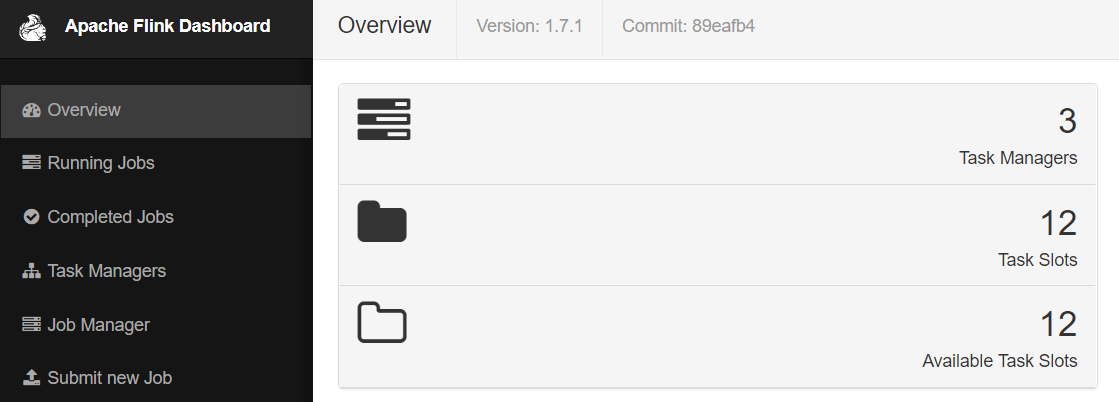
TaskManager界面:可以查看到当前Flink集群中有多少个TaskManager,每个TaskManager的slots、内存、CPU Core是多少。
HA集群搭建
Flink的JobManager存在单点故障,在生产环境中,需要对JobManager进行高可用部署。JobManager高可用基于ZooKeeper实现,同时HA的信息需要存储在HDFS中,故也需要HDFS集群。
- 前提:启动ZooKeeper—>zkServer.sh start
- 前提:启动HDFS —>start-dfs.sh
- 修改node02的
conf/flink-conf.yaml配置文件
web.address: node02
rest.port: 8081
1 | #node01/02/03的每个flink-conf.yaml配置文件开启HA |
修改3台机器的
conf/masters配置文件1
2node01:8081
node02:8081启动Zookeeper集群
启动HDFS集群
启动Flink集群
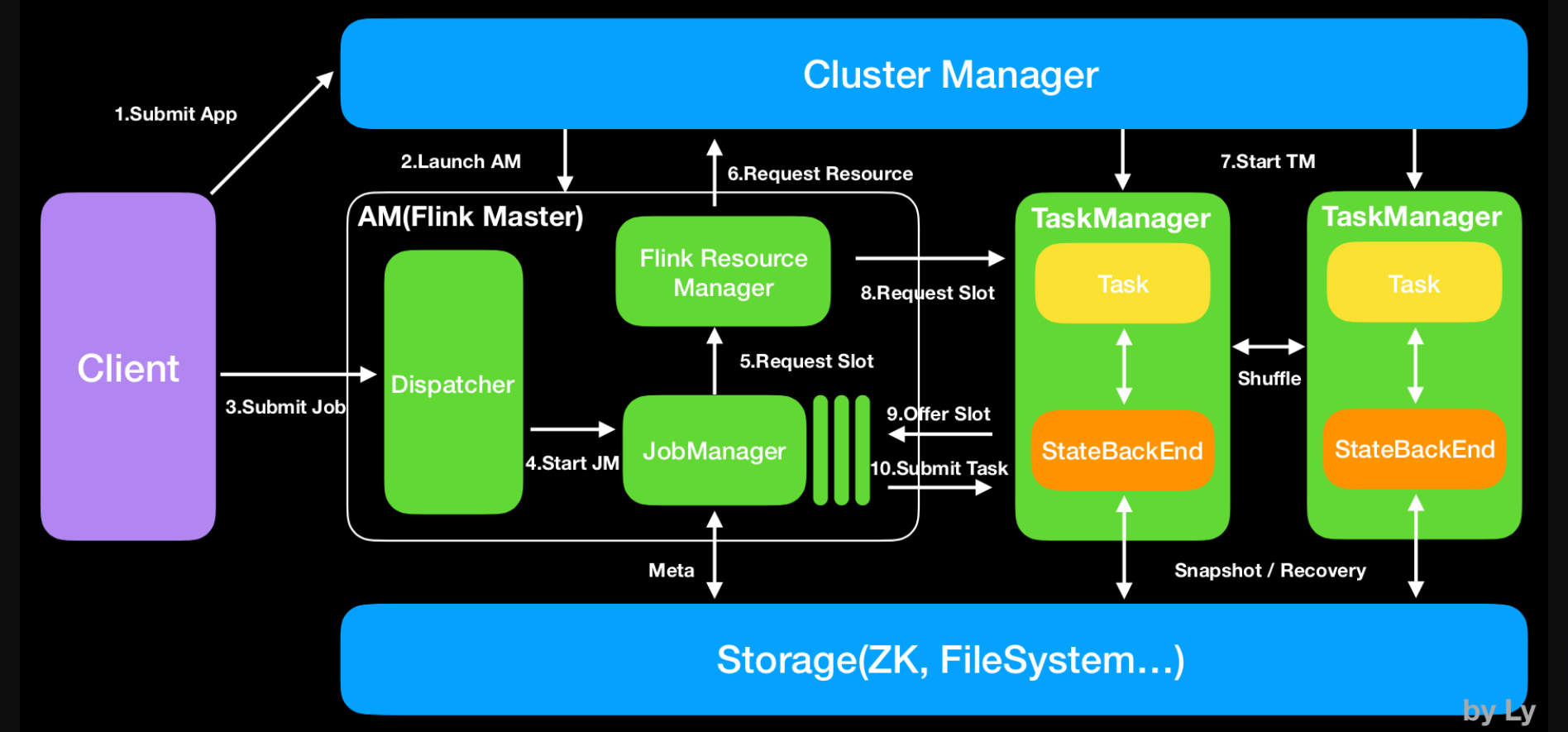
Flink程序提交方式
在企业生产中,为了最大化利用资源,一般都会在一个集群中同时运行多种类型的任务,我们Flink也是支持在Yarn/Mesos等平台运行.Flink的任务提交有两种方式,分别是Session和Job
- 首先需要配置相关Hadoop的环境
- 修改yarn-site.xml
1 | vim $HADOOP_HOME/etc/hadoop/yarn-site.xml |
添加如下配置,并拷贝到node02/node03:
1 | <property> |
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true。在这里面我们需要关闭,因为对于flink使用yarn模式下,很容易内存超标,这个时候yarn会自动杀掉job
- 添加HADOOP_CONF_DIR环境变量
1 | vim /etc/profile |
方式1:session
在
yarn上启动一个Flink Job,执行以下命令1
2
3
4
5
6
7
8启动Yarn集群
start-yarn.sh
通过-h参数可以查看yarn-session的参数功能
bin/yarn-session.sh -h
使用Flink自带yarn-session.sh脚本开启Yarn会话
bin/yarn-session.sh -n 2 -tm 800 -s 2
可以事先关闭 否则会出现程序跑不完
./bin/stop-cluster.sh-n表示分配多少个container,这里指的就是多少个taskmanager-tm表示每个TaskManager的内存大小-s表示每个TaskManager的slots数量
上面的命令的意思是,同时向Yarn申请3个container(即便只申请了两个,因为ApplicationMaster和Job Manager有一个额外的容器。一旦将Flink部署到YARN群集中,它就会显示Job Manager的连接详细信息。),其中 2 个 Container 启动 TaskManager(-n 2),每个 TaskManager 拥有两个 Task Slot(-s 2),并且向每个 TaskManager 的 Container 申请 800M 的内存,以及一个ApplicationMaster(Job Manager)。
如果不想让Flink YARN客户端始终运行,那么也可以启动分离的 YARN会话。该参数被称为-d或–detached。在这种情况下,Flink YARN客户端只会将Flink提交给群集,然后关闭它自己
然后使用flink提交任务:
1
bin/flink run examples/batch/WordCount.jar

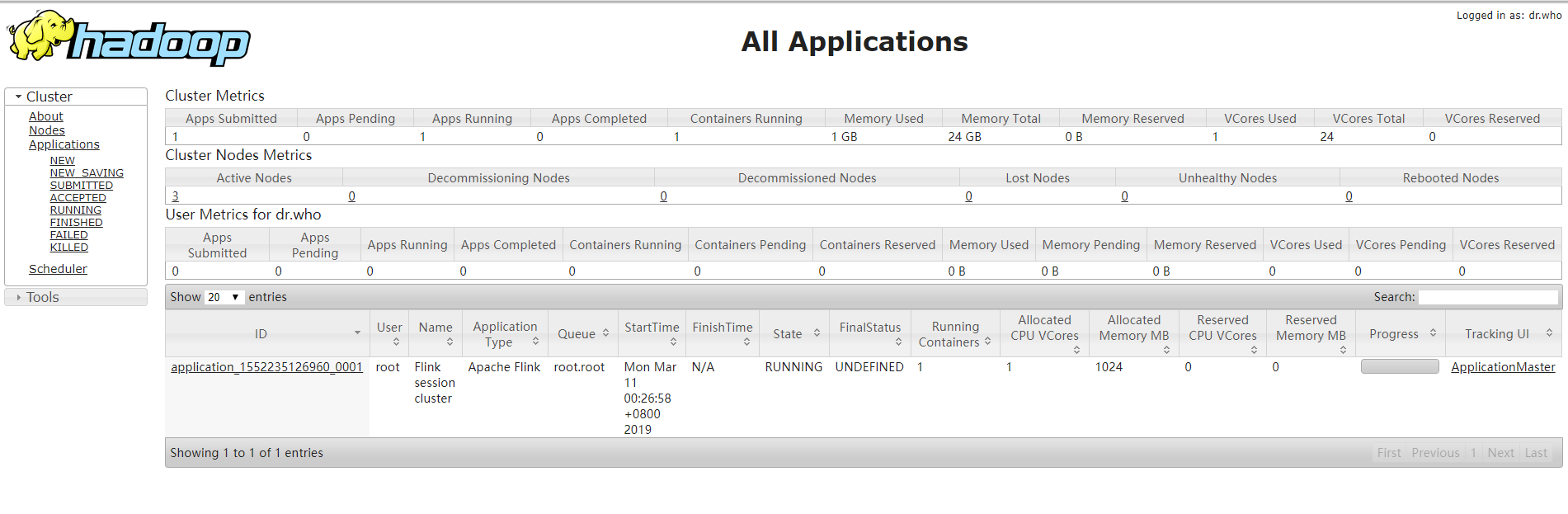
通过上方的ApplicationMaster可以进入Flink的管理界面:
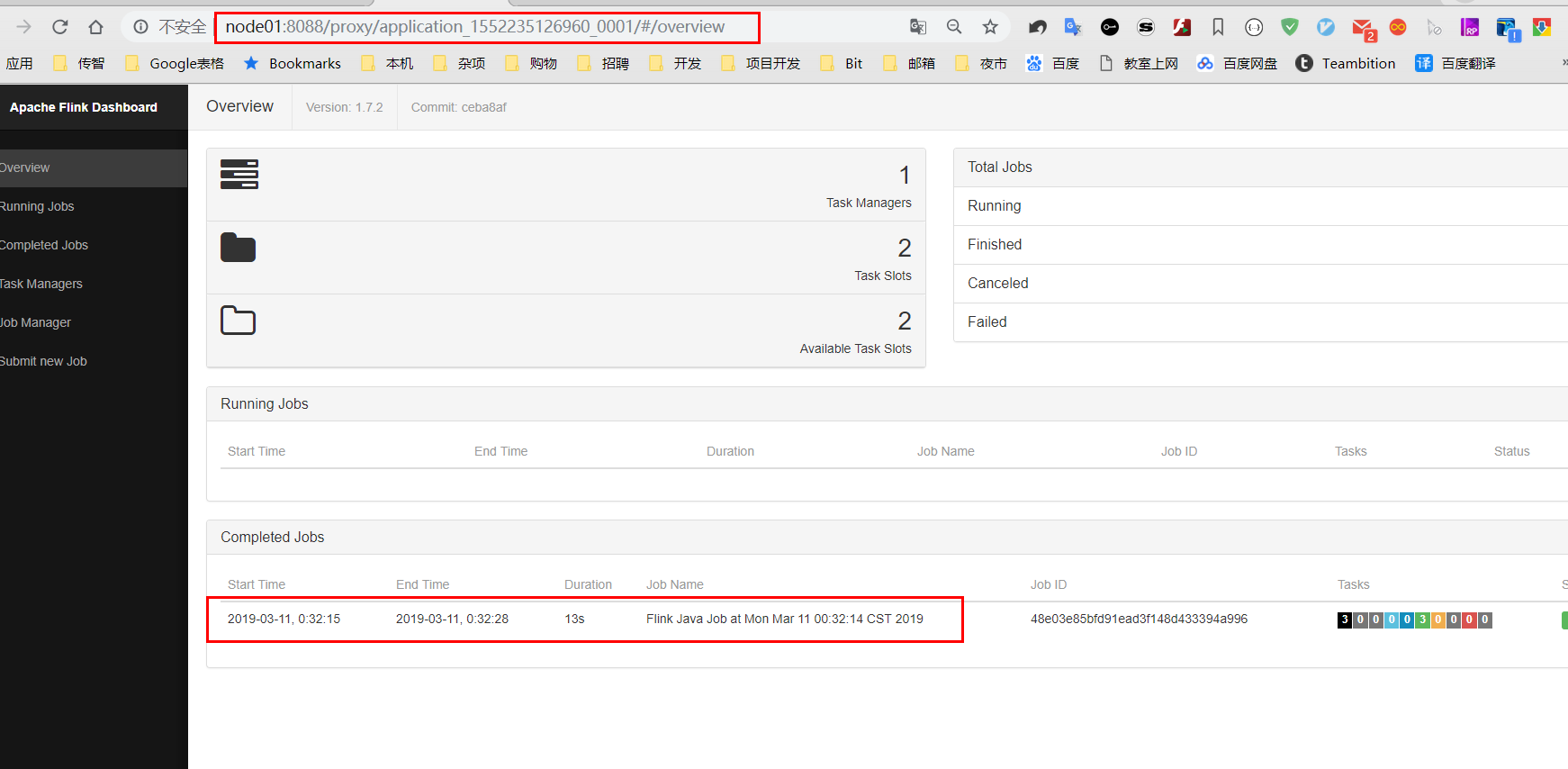
停止当前任务:
yarn application -kill application_1562034096080_0001
方式2:job
上面的YARN session是在Hadoop YARN环境下启动一个Flink cluster集群,里面的资源是可以共享给其他的Flink作业。我们还可以在YARN上启动一个Flink作业,这里我们还是使用./bin/flink,但是不需要事先启动YARN session:
1 | bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar |
以上命令在参数前加上y前缀,-yn表示TaskManager个数
停止yarn-cluster
1
2yarn application -kill application的ID
这种方式一般适用于长时间工作的任务,如果任务比较小,或者工作时间短,建议适用session方式,减少资源创建的时间.实际生产环境中,job方式适用较多.
区别:
Session方式适合提交小任务,因为资源的开辟需要的时间比较长,session方式资源是共享的,
Job适合提交长时间运行的任务,大作业,资源是独有的.
入门案例
创建工程
导入pom文件
1 | <properties> |
编写代码
WordCount
1
2
3
4
5
6
7
8def main(args: Array[String]): Unit = {
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
val dataSet: DataSet[String] = env.fromElements("hello", "world", "java", "hello", "java")
val mapData: DataSet[(String, Int)] = dataSet.map(line => (line, 1))
val groupData: GroupedDataSet[(String, Int)] = mapData.groupBy(0)
val sumData: AggregateDataSet[(String, Int)] = groupData.sum(1)
sumData.print()
}

在Yarn上运行WordCount
1 | def main(args: Array[String]): Unit = { |
- 修改pom.xml中的主类名
1 | <transformers> |
- 打包
提交执行
- 将打出的jar放入服务器
使用session方式提交
1 | 1.先启动yarnsession |
使用job方式提交
1 | bin/flink run -m yarn-cluster -yn 2 /home/elasticsearch/flinkjar/itcast_learn_flink-1.0-SNAPSHOT.jar com.itcast.DEMO.WordCount |
任务调度与执行
Flink的所有操作都称之为Operator,客户端在提交任务的时候会对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain
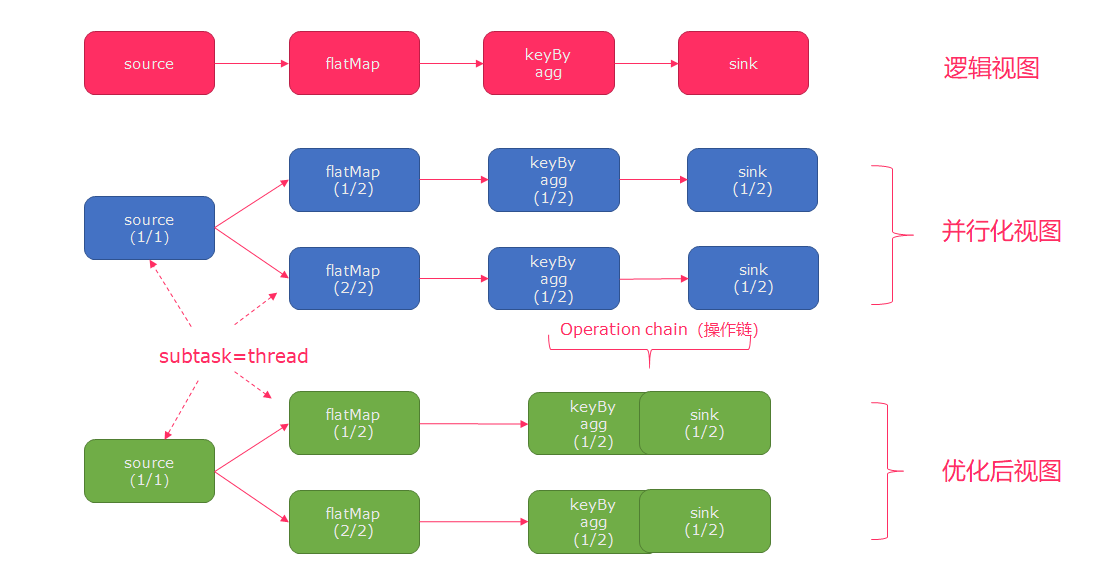

- 客户端
- 主要职责是提交任务, 提交后可以结束进程, 也可以等待结果返回
JobManager- 主要职责是调度工作并协调任务做检查点
JobManager从客户端接收到任务以后, 首先生成优化过的执行计划, 再调度到TaskManager中执行
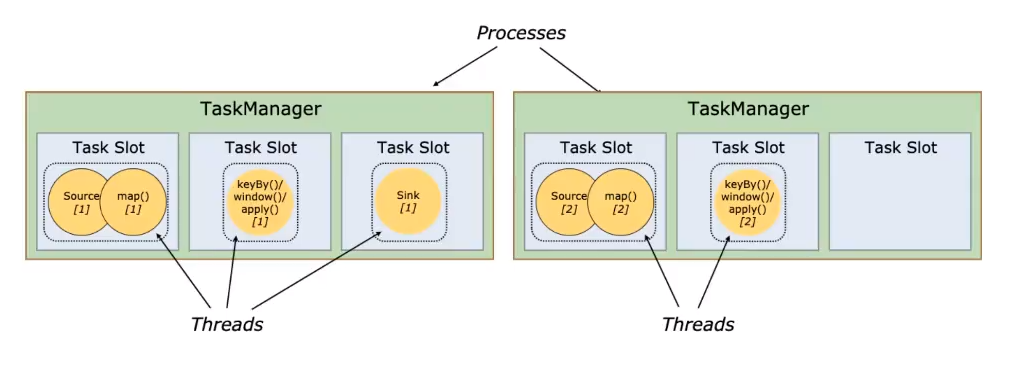
TaskManager- 主要职责是从
JobManager处接收任务, 并部署和启动任务, 接收上游的数据并处理 TaskManager在创建之初就设置好了Slot, 每个Slot可以执行一个任务
- 主要职责是从
Flink的API
DataSet的转换操作
| Transformation | Description |
|---|---|
| Map | 在算子中得到一个元素并生成一个新元素data.map { x => x.toInt } |
| FlatMap | 在算子中获取一个元素, 并生成任意个数的元素data.flatMap { str => str.split(" ") } |
| MapPartition | 类似Map, 但是一次Map一整个并行分区data.mapPartition { in => in map { (_, 1) } } |
| Filter | 如果算子返回true则包含进数据集, 如果不是则被过滤掉data.filter { _ > 100 } |
| Reduce | 通过将两个元素合并为一个元素, 从而将一组元素合并为一个元素data.reduce { _ + _ } |
| ReduceGroup | 将一组元素合并为一个或者多个元素data.reduceGroup { elements => elements.sum } |
| Aggregate | 讲一组值聚合为一个值, 聚合函数可以看作是内置的Reduce函数data.aggregate(SUM, 0).aggregate(MIN, 2)data.sum(0).min(2) |
| Distinct | 去重 |
| Join | 按照相同的Key合并两个数据集input1.join(input2).where(0).equalTo(1)同时也可以选择进行合并的时候的策略, 是分区还是广播, 是基于排序的算法还是基于哈希的算法 input1.join(input2, JoinHint.BROADCAST_HASH_FIRST).where(0).equalTo(1) |
| OuterJoin | 外连接, 包括左外, 右外, 完全外连接等left.leftOuterJoin(right).where(0).equalTo(1) { (left, right) => ... } |
| CoGroup | 二维变量的Reduce运算, 对每个输入数据集中的字段进行分组, 然后join这些组input1.coGroup(input2).where(0).equalTo(1) |
| Cross | 笛卡尔积input1.cross(input2) |
| Union | 并集input1.union(input2) |
| Rebalance | 分区重新平衡, 以消除数据倾斜input.rebalance() |
| Hash-Partition | 按照Hash分区input.partitionByHash(0) |
| Range-Partition | 按照Range分区input.partitionByRange(0) |
| CustomParititioning | 自定义分区input.partitionCustom(partitioner: Partitioner[K], key) |
| First-n | 返回数据集中的前n个元素input.first(3) |
flatmap
map => 1 => 1
flatmap => 1 => 多个数据
1 | def main(args: Array[String]): Unit = { |
filter
1 | //TODO fileter=> |
reduce
1 | //默认并行度为8,全局并行度设为1 |
reduceGroup
reduceGroup是reduce的一种优化方案;
它会先分组reduce,然后在做整体的reduce;这样做的好处就是可以减少网络IO;
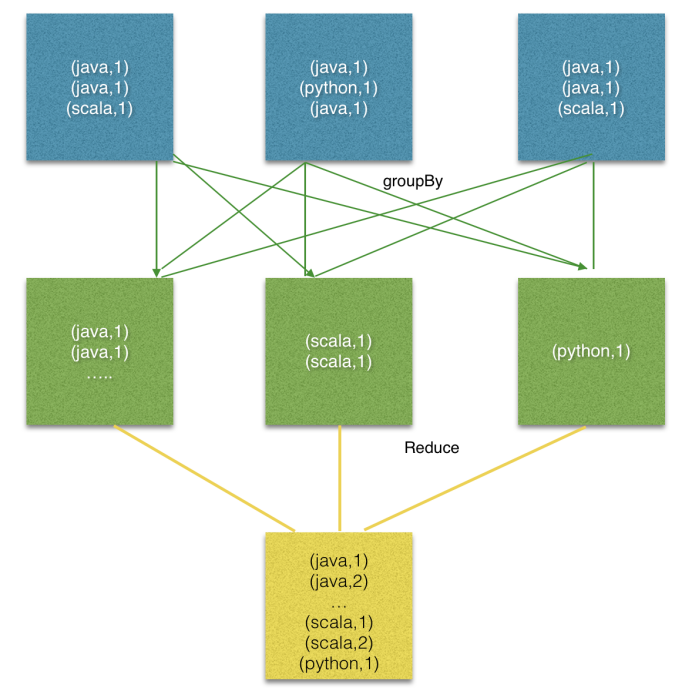
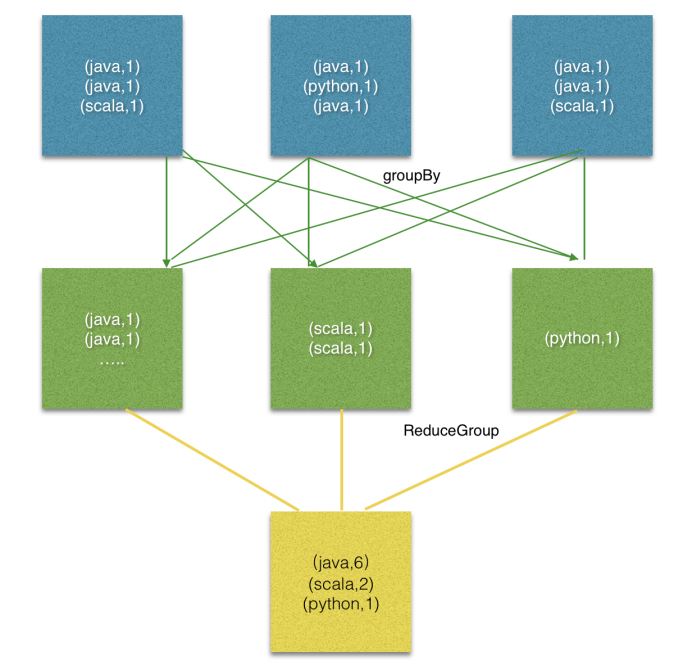
join
- 求每个班级最高分
1 | def main(args: Array[String]): Unit = { |
distinct去重
1 | val data = new mutable.MutableList[(Int, String, Double)] |
DataStream的转换操作
Flink中的DataStream程序是实现数据流转换(例如,过滤,更新状态,定义窗口,聚合)的常规程序。数据流最初由各种来源(例如,消息队列,套接字流,文件)创建。结果通过接收器返回,例如可以将数据写入文件,或者写入标准输出(例如命令行终端)。Flink程序可以在各种情况下运行,可以独立运行,也可以嵌入其他程序中。执行可以发生在本地JVM或许多机器的集群中。
| Transformation | Description |
|---|---|
| Map DataStream → DataStream |
dataStream.map { x => x * 2 } |
| FlatMap DataStream → DataStream |
dataStream.flatMap { x => x.split(",") } |
| Filter DataStream → DataStream |
dataStream.filter { _ != 0 } |
| KeyBy DataStream → KeyedStream |
将一个流分为不相交的区, 可以按照名称指定Key, 也可以按照角标来指定 `dataStream.keyBy(“key” |
| Reduce KeyedStream → DataStream |
滚动Reduce, 合并当前值和历史结果, 并发出新的结果值keyedStream.reduce { _ + _ } |
| Fold KeyedStream → DataStream |
按照初始值进行滚动折叠keyedStream.fold("start")((str, i) => { str + "-" + i }) |
| Aggregations KeyedStream → DataStream |
滚动聚合, sum, min, max等keyedStream.sum(0) |
| Window KeyedStream → DataStream |
窗口函数, 根据一些特点对数据进行分组, 注意: 有可能是非并行的, 所有记录可能在一个任务中收集.window(TumblingEventTimeWindows.of(Time.seconds(5))) |
| WindowAll DataStream → AllWindowedStream |
窗口函数, 根据一些特点对数据进行分组, 和window函数的主要区别在于可以不按照Key分组dataStream.windowAll (TumblingEventTimeWindows.of(Time.seconds(5))) |
| WindowApply WindowedStream → DataStream |
将一个函数作用于整个窗口windowedStream.apply { WindowFunction } |
| WindowReduce WindowedStream → DataStream |
在整个窗口上做一次reducewindowedStream.reduce { _ + _ } |
| WindowFold WindowedStream → DataStream |
在整个窗口上做一次foldwindowedStream.fold("start", (str, i) => { str + "-" + i }) |
| Aggregations on windows WindowedStream → DataStream |
在窗口上统计, sub, max, minwindowedStream.sum(10) |
| Union DataStream* → DataStream |
合并多个流dataStream.union(dataStream1, dataStream2, ...) |
| Window Join DataStream → DataStream |
dataStream.join(otherStream).where(...).equalTo(...) .window(TumblingEventTimeWindows.of(Time.seconds(3))).apply{..} |
| Window CoGroup DataStream, DataStream → DataStream |
dataStream.coGroup(otherStream).where(0).equalTo(1).window(...).apply{...} |
| Connect DataStream, DataStream → DataStream |
连接两个流, 并且保留各自的数据类型, 在这个连接中可以共享状态someStream.connect(otherStream) |
| Split DataStream → SplitStream |
将一个流切割为多个流someDataStream.split((x: Int) => x match ...) |
入门案例
编写代码:
1 | def main(args: Array[String]): Unit = { |
在Linux窗口中发送消息:
1 | nc -lk 9999 |
keyby
1 | def main(args: Array[String]): Unit = { |
Flink SQL
Flink SQL可以让我们通过基于Table API和SQL来进行数据处理。Flink的批处理和流处理都支持Table API。Flink SQL完全遵循ANSI SQL标准。
批数据SQL
用法
- 构建Table运行环境
- 将DataSet注册为一张表
- 使用Table运行环境的
sqlQuery方法来执行SQL语句
示例
使用Flink SQL统计用户消费订单的总金额、最大金额、最小金额、订单总数。
| 订单id | 用户名 | 订单日期 | 消费基恩 |
|---|---|---|---|
| 1 | zhangsan | 2018-10-20 15:30 | 358.5 |
测试数据(订单ID、用户名、订单日期、订单金额)
1 | (1,"zhangsan","2018-10-20 15:30",358.5), |
步骤
- 获取一个批处理运行环境
- 获取一个Table运行环境
- 创建一个样例类
Order用来映射数据(订单名、用户名、订单日期、订单金额) - 基于本地
Order集合创建一个DataSet source - 使用Table运行环境将DataSet注册为一张表
- 使用SQL语句来操作数据(统计用户消费订单的总金额、最大金额、最小金额、订单总数)
- 使用TableEnv.toDataSet将Table转换为DataSet
- 打印测试
参考代码
1 | val env = ExecutionEnvironment.getExecutionEnvironment |
流数据SQL
流处理中也可以支持SQL。但是需要注意以下几点:
- 要使用流处理的SQL,必须要添加水印时间
- 使用
registerDataStream注册表的时候,使用'来指定字段 - 注册表的时候,必须要指定一个rowtime,否则无法在SQL中使用窗口
- 必须要导入
import org.apache.flink.table.api.scala._隐式参数 - SQL中使用
tumble(时间列名, interval '时间' sencond)来进行定义窗口- TUMBLE(time_attr, interval)固定时间窗口
- HOP(time_attr, interval, interval)滑动窗口,
- SESSION(time_attr, interval)会话窗口
示例
使用Flink SQL来统计5秒内用户的订单总数、订单的最大金额、订单的最小金额。
步骤
- 获取流处理运行环境
- 获取Table运行环境
- 设置处理时间为
EventTime - 创建一个订单样例类
Order,包含四个字段(订单ID、用户ID、订单金额、时间戳) - 创建一个自定义数据源
- 使用for循环生成1000个订单
- 随机生成订单ID(UUID)
- 随机生成用户ID(0-2)
- 随机生成订单金额(0-100)
- 时间戳为当前系统时间
- 每隔1秒生成一个订单
- 添加水印,允许延迟2秒
- 导入
import org.apache.flink.table.api.scala._隐式参数 - 使用
registerDataStream注册表,并分别指定字段,还要指定rowtime字段 - 编写SQL语句统计用户订单总数、最大金额、最小金额
- 分组时要使用
tumble(时间列, interval '窗口时间' second)来创建窗口
- 分组时要使用
- 使用
tableEnv.sqlQuery执行sql语句 - 将SQL的执行结果转换成DataStream再打印出来
- 启动流处理程序
参考代码
1 | // 3. 创建一个订单样例类`Order`,包含四个字段(订单ID、用户ID、订单金额、时间戳) |
在SQL语句中,不要将名字取成SQL中的关键字,例如:timestamp。
Table转换为DataStream或DataSet
转换为DataSet
- 直接使用
tableEnv.toDataSet方法就可以将Table转换为DataSet - 转换的时候,需要指定泛型,可以是一个样例类,也可以是指定为
Row类型
转换为DataStream
- 使用
tableEnv.toAppendStream,将表直接附加在流上 - 使用
tableEnv.toRetractStream,返回一个元组(Boolean, DataStream),Boolean表示数据是否被成功获取 - 转换的时候,需要指定泛型,可以是一个样例类,也可以是指定为
Row类型
窗口/水印
- 源源不断地数据是无法进行统计工作的,因为数据流
没有边界,无法统计到底有多少数据经过了这个流 - window操作就是在数据流上,截取固定大小的一部分,这个部分是可以统计的
- 截取方式有两种
- 按照
时间截取,例如:10秒钟、10分钟统计一次 - 按照
消息数量截取,例如:每5个数据、或者50个数据统计一次
- 按照
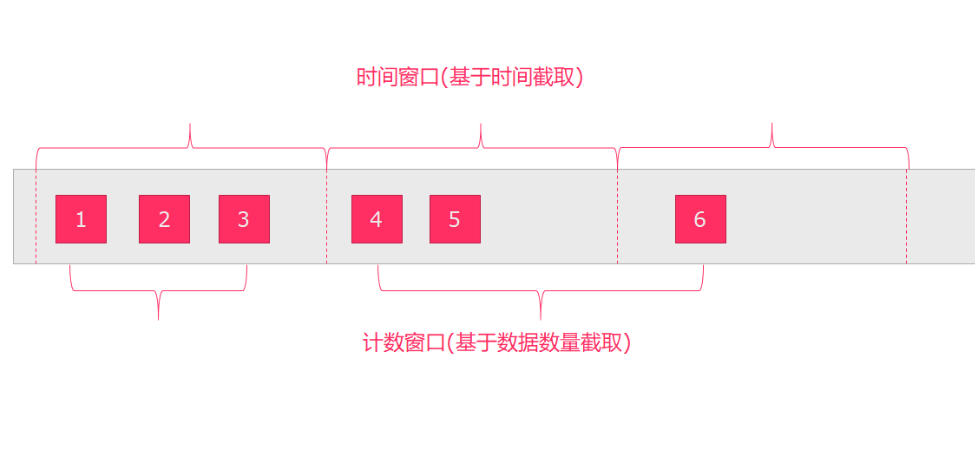
窗口
Flink的窗口划分方式分为2种:time/count,即按时间划分和数量划分
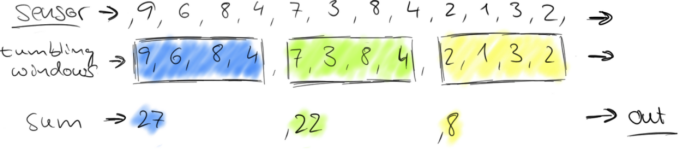
tumbling-time-window (无重叠数据)
1.红绿灯路口会有汽车通过,一共会有多少汽车通过,无法计算。因为车流源源不断,计算没有边界。
2.统计每15秒钟通过红路灯的汽车数量,第一个15秒为2辆,第二个15秒为3辆,第三个15秒为1辆。。。
1 | 发送内容 |
编码:
1 | def main(args: Array[String]): Unit = { |
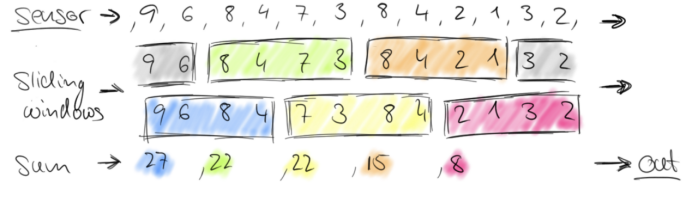
sliding-time-window (有重叠数据)
编码:
1 | val env = StreamExecutionEnvironment.getExecutionEnvironment |
tumbling-count-window (无重叠数据)
按照个数进行统计,比如:
每个路口分别统计,收到关于它的5条消息时统计在最近5条消息中,各自路口通过的汽车数量
代码:
1 | val env = StreamExecutionEnvironment.getExecutionEnvironment |
sliding-count-window (有重叠数据)
同样也是窗口长度和滑动窗口的操作:窗口长度是5,滑动长度是3
编码:
1 | val env = StreamExecutionEnvironment.getExecutionEnvironment |
问题:
Flink中的窗口分为两类,一类是按时间来分,一类是按照事件的种类来分。对吗?
- 如果窗口滑动时间 > 窗口时间,会出现数据丢失
- 如果窗口滑动时间 < 窗口时间,会出现数据重复计算,比较适合实时排行榜
- 如果窗口滑动时间 = 窗口时间,数据不会被重复计算
水印
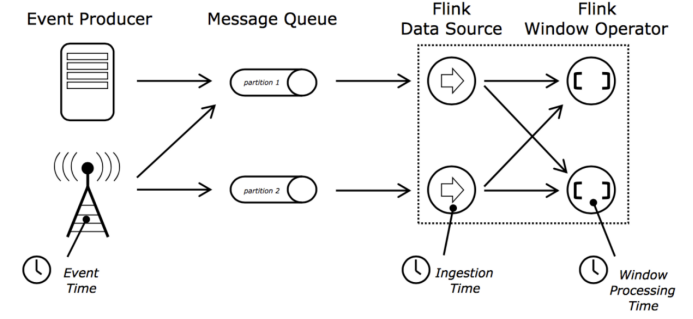
Flink的时间划分方式
- 事件时间:事件时间是每条事件在它产生的时候记录的时间,该时间记录在事件中,在处理的时候可以被提取出来。小时的时间窗处理将会包含事件时间在该小时内的所有事件,而忽略事件到达的时间和到达的顺序
- 摄入时间:摄入时间是事件进入flink的时间,在source operator中,每个事件拿到当前时间作为时间戳,后续的时间窗口基于该时间。
- 处理时间:当前机器处理该条事件的时间
问题:
ProcessingTime是指的进入到Flink数据流处理系统的时间,对吗?
如何处理水印
需求:
以EventTime划分窗口,计算3秒钟内出价最高的产品
1 | 1527911155000,boos1,pc1,100.0 |
代码:
1 | def main(args: Array[String]) { |
当前代码理论上看没有任何问题,在实际使用的时候就会出现很多问题,甚至接收不到数据或者接收到的数据是不准确的;这是因为对于flink最初设计的时候,就考虑到了网络延迟,网络乱序等问题,所以提出了一个抽象概念水印(WaterMark)

水印分成两种形式:
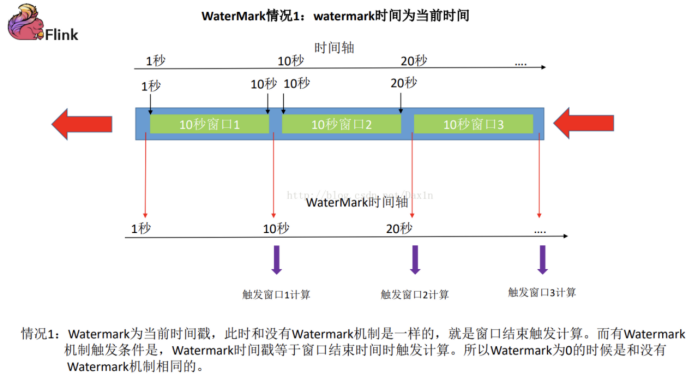
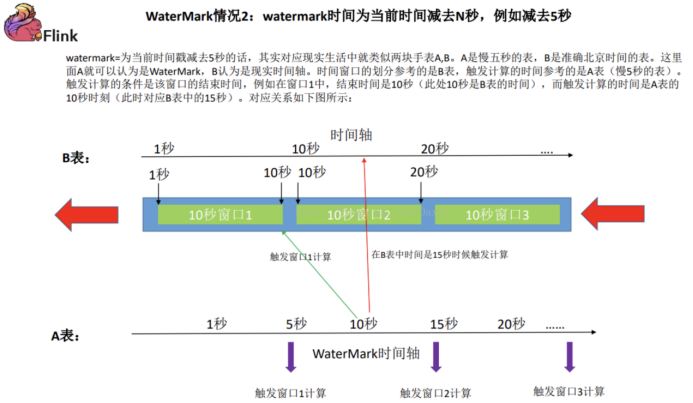
代码中就需要添加水印操作:
1 | def main(args: Array[String]): Unit = { |
容错
批处理系统比较容易实现容错机制,由于文件可以重复访问,当某个任务失败后,重启该任务即可。但是在流处理系统中,由于数据源是无限的数据流,一个流处理任务甚至可能会执行几个月,将所有数据缓存或是持久化,留待以后重复访问基本上是不可行的。
Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator的状态来生成Snapshot,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些Snapshot进行恢复,从而修正因为故障带来的程序数据状态中断。
Checkpoint
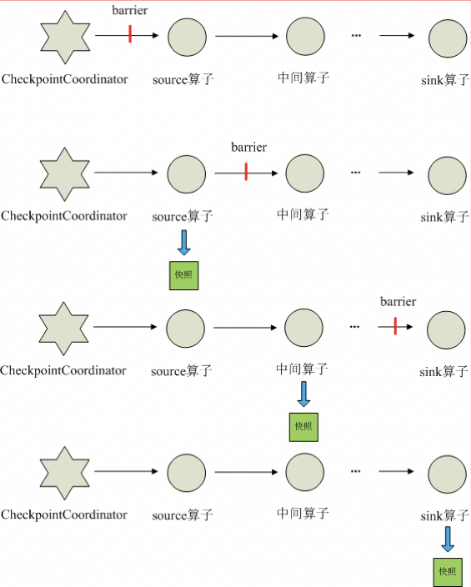
Checkpoint流程
- CheckpointCoordinator周期性的向该流应用的所有source算子发送barrier。
- 当某个source算子收到一个barrier时,会向自身所有下游算子广播该barrier,同时将自己的当前状态制作成快照(异步),并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自己快照制作情况
- 下游算子收到barrier之后,会向自身所有下游算子广播该barrier,同时将自身的相关状态制作成快照(异步),并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身快照情况
- 每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
- 当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败
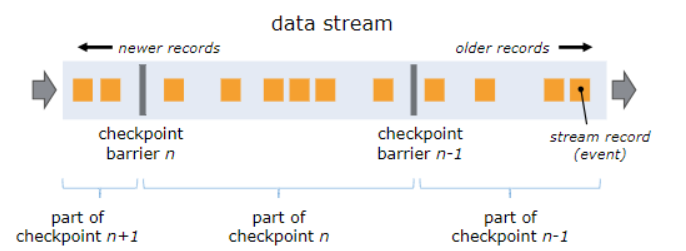
单流的barrier
- 屏障作为数据流的一部分随着记录被注入到数据流中。屏障永远不会赶超通常的流记录,它会严格遵循顺序。
- 屏障将数据流中的记录隔离成一系列的记录集合,并将一些集合中的数据加入到当前的快照中,而另一些数据加入到下一个快照中。
- 每一个屏障携带着快照的ID,快照记录着ID并且将其放在快照数据的前面。
- 屏障不会中断流处理,因此非常轻量级。
并行barrier
- 不止一个输入流的时的operator,需要在快照屏障上对齐(align)输入流,才会发射出去。
- 可以看到1,2,3会一直放在Input buffer,直到另一个输入流的快照到达Operator。

问题:
Flink中Barrier的对齐指的是Flink处理数据流的时候,会加入barrier,某一个operator接收到一个barriern,会等到接收到所有数据流的barrier,才继续往下处理。这样可以实现数据Exatly Once语义。对吗?
一个Operator处理完数据流后,会将数据流中的barrier删除,这样可以减少处理的数据量,提高运行效率。对吗?
持久化存储
MemoryStateBackend
state数据保存在java堆内存中,执行checkpoint的时候,会把state的快照数据保存到jobmanager的内存中 基于内存的state backend在生产环境下不建议使用。
FsStateBackend
state数据保存在taskmanager的内存中,执行checkpoint的时候,会把state的快照数据保存到配置的文件系统中,可以使用hdfs等分布式文件系统。
RocksDBStateBackend
基于RocksDB + FS
RocksDB跟上面的都略有不同,它会在本地文件系统中维护状态,state会直接写入本地rocksdb中。同时RocksDB需要配置一个远端的filesystem。
代码:
1 | val env = StreamExecutionEnvironment.getExecutionEnvironment |