一 udf简介 当 Hive 提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)
二 基于Java的UDF,UDAF和UDTF 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 开发UDF: 开发自定义UDF函数有两种方式,一个是继承org.apache.hadoop.hive.ql.exec.UDF,另一个是继承org.apache.hadoop.hive.ql.udf.generic.GenericUDF; 如果是针对简单的数据类型(比如String、Integer等)可以使用UDF,如果是针对复杂的数据类型(比如Array、Map、Struct等),可以使用GenericUDF,另外,GenericUDF还可以在函数开始之前和结束之后做一些初始化和关闭的处理操作。 并且继承GenericUDF更加有效率,因为UDF class 需要HIve使用反射的方式去实现。 开发UDAF: 就是聚合函数(聚集函数)(如count,sum等) UDAF和UDAFEvaluator: 使用Java反射导致性能损失,而且有些特性不能使用,已经被弃用了(也有例子) 在这篇博文中将关注Hive中自定义聚类函数-GenericUDAF,UDAF开发主要涉及到以下两个抽象类: org.apache.hadoop.hive.ql.udf.generic.AbstractGenericUDAFResolver org.apache.hadoop.hive.ql.udf.generic.GenericUDAFEvaluator 开发UDTF: 用户自定义表生成函数,表生成函数接受0个或多个输入然后产生多列或多行输出。(如explode); 一个 UDTF 必须继承 GenericUDTF 抽象类然后实现抽象类中的 initialize,process,和 close方法。其中,Hive 调用 initialize 方法来确定传入参数的类型并确定 UDTF 生成表的每个字段的数据类型(即输入类型和输出类型)。initialize 方法必须返回一个生成表的字段的相应的 object inspector。一旦调用了 initialize() ,Hive将把 UDTF 参数传给 process() 方法,调用这个方法可以产生行对象并将行对象转发给其他操作器。最后当所有的行对象都传递出 UDTF 调用 close() 方法。 udf与udaf区别: UDF是基于单条记录的列进行的计算操作,而UDAF则是用户自定义的聚类函数,是基于表的所有记录进行的计算操作。 UDF和UDAF都可以重载 UDAF是需要在hive的sql语句和group by联合使用,hive的group by对于每个分组,只能返回一条记录,这点和mysql不一样,切记。
Maven依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 <?xml version="1.0" encoding="UTF-8"?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <groupId > XXX</groupId > <artifactId > XXX</artifactId > <version > XXX</version > <properties > <java-version > 1.8</java-version > <project.build.sourceEncoding > UTF-8</project.build.sourceEncoding > <apache.hadoop.version > 2.6.0</apache.hadoop.version > <apache.hive.version > 2.3.3</apache.hive.version > </properties > <dependencies > <dependency > <groupId > org.apache.hive</groupId > <artifactId > hive-serde</artifactId > <optional > true</optional > <version > ${apache.hive.version}</version > <scope > provided</scope > </dependency > <dependency > <groupId > org.apache.hive</groupId > <artifactId > hive-common</artifactId > <version > ${apache.hive.version}</version > <scope > provided</scope > </dependency > <dependency > <groupId > org.apache.hive</groupId > <artifactId > hive-exec</artifactId > <version > ${apache.hive.version}</version > <scope > provided</scope > </dependency > <dependency > <groupId > org.apache.hadoop</groupId > <artifactId > hadoop-common</artifactId > <version > ${apache.hadoop.version}</version > <scope > provided</scope > </dependency > <dependency > <groupId > javax.jdo</groupId > <artifactId > jdo2-api</artifactId > <version > 2.3-eb</version > <scope > test</scope > </dependency > <dependency > <groupId > org.apache.hive</groupId > <artifactId > hive-cli</artifactId > <version > ${apache.hive.version}</version > <scope > test</scope > </dependency > <dependency > <groupId > junit</groupId > <artifactId > junit</artifactId > <version > 4.10</version > <scope > test</scope > </dependency > <dependency > <groupId > ch.hsr</groupId > <artifactId > geohash</artifactId > <version > 1.0.13</version > </dependency > <dependency > <groupId > org.codehaus.plexus</groupId > <artifactId > plexus-archiver</artifactId > <version > 3.4</version > </dependency > <dependency > <groupId > org.codehaus.plexus</groupId > <artifactId > plexus-utils</artifactId > <version > 3.0.24</version > </dependency > <dependency > <groupId > org.apache.commons</groupId > <artifactId > commons-lang3</artifactId > <version > 3.2</version > </dependency > <dependency > <groupId > com.huaban</groupId > <artifactId > jieba-analysis</artifactId > <version > 1.0.2</version > </dependency > <dependency > <groupId > com.janeluo</groupId > <artifactId > ikanalyzer</artifactId > <version > 2012_u6</version > </dependency > </dependencies > <build > <plugins > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-compiler-plugin</artifactId > <version > 2.3.2</version > <configuration > <source > ${java-version}</source > <target > ${java-version}</target > <encoding > UTF-8</encoding > </configuration > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-jar-plugin</artifactId > <configuration > <archive > <manifest > <addDefaultImplementationEntries > true</addDefaultImplementationEntries > <addDefaultSpecificationEntries > true</addDefaultSpecificationEntries > </manifest > </archive > </configuration > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-shade-plugin</artifactId > <version > 2.4.3</version > <configuration > <keepDependenciesWithProvidedScope > false</keepDependenciesWithProvidedScope > </configuration > <executions > <execution > <phase > package</phase > <goals > <goal > shade</goal > </goals > </execution > </executions > </plugin > </plugins > </build > </project >
2.1 udf 2.1.1 继承UDF 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import org.apache.commons.lang.StringUtils;import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop.io.Text;public class LowerUDF extends UDF public Text evaluate (Text str) if (null == str){ return null ; } if (StringUtils.isBlank(str.toString())){ return null ; } return new Text(str.toString().toLowerCase()) ; } public int evaluate (int a,int b) return a+b; } }
1.打包将jar包上传hdfs
2.创建临时函数与Java class关联
1 2 add jar hdfs: create temporary function udffunc as 'hive.udf.LowerUDF' ;
3 使用
1 2 select udffunc("ABC" ) from dual;//输出abcselect udffunc(2 ,3 ) from dual;//输出5
2.1.2 继承GenericUDF 继承后需要重写以下方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public void configure (MapredContext context) public ObjectInspector initialize (ObjectInspector[] arguments) public Object evaluate (DeferredObject[] args) public String getDisplayString (String[] children) public void close ()
下面的程序将一个以逗号分隔的字符串,切分成List,并返回:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 import java.util.ArrayList;import java.util.Date; import org.apache.hadoop.hive.ql.exec.MapredContext;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;import org.apache.hadoop.hive.ql.metadata.HiveException;import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory; public class Lxw1234GenericUDF extends GenericUDF private static int mapTasks = 0 ;private static String init = "" ;private transient ArrayList ret = new ArrayList();@Override public void configure (MapredContext context) System.out.println(new Date() + "######## configure" ); if (null != context) {mapTasks = context.getJobConf().getNumMapTasks(); } System.out.println(new Date() + "######## mapTasks [" + mapTasks + "] .." ); } @Override public ObjectInspector initialize (ObjectInspector[] arguments) throws UDFArgumentException System.out.println(new Date() + "######## initialize" ); init = "init" ; ObjectInspector returnOI = PrimitiveObjectInspectorFactory .getPrimitiveJavaObjectInspector(PrimitiveObjectInspector.PrimitiveCategory.STRING); return ObjectInspectorFactory.getStandardListObjectInspector(returnOI);} @Override public Object evaluate (DeferredObject[] args) throws HiveException ret.clear(); if (args.length < 1 ) return ret;String str = args[0 ].get().toString(); String[] s = str.split("," ,-1 ); for (String word : s) {ret.add(word); } return ret;} @Override public String getDisplayString (String[] children) return "Usage: Lxw1234GenericUDF(String str)" ;} }
判断array中是否包含某个值:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 package org.apache.hadoop.hive.ql.udf.generic;import org.apache.hadoop.hive.ql.exec.Description;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;import org.apache.hadoop.hive.ql.metadata.HiveException;import org.apache.hadoop.hive.serde2.objectinspector.ListObjectInspector;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector.Category;import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorUtils;import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import org.apache.hadoop.io.BooleanWritable;@Description(name = "array_contains", value = "_FUNC_(array, value) - Returns TRUE if the array contains value.", extended = "Example:\n > SELECT _FUNC_(array(1, 2, 3), 2) FROM src LIMIT 1;\n true") public class GenericUDFArrayContains extends GenericUDF private static final int ARRAY_IDX = 0 ; private static final int VALUE_IDX = 1 ; private static final int ARG_COUNT = 2 ; private static final String FUNC_NAME = "ARRAY_CONTAINS" ; private transient ObjectInspector valueOI; private transient ListObjectInspector arrayOI; private transient ObjectInspector arrayElementOI; private BooleanWritable result; public ObjectInspector initialize (ObjectInspector[] arguments) throws UDFArgumentException if (arguments.length != 2 ) { throw new UDFArgumentException("The function ARRAY_CONTAINS accepts 2 arguments." ); } if (!(arguments[0 ].getCategory().equals(ObjectInspector.Category.LIST))) { throw new UDFArgumentTypeException(0 , "\"array\" expected at function ARRAY_CONTAINS, but \"" + arguments[0 ].getTypeName() + "\" " + "is found" ); } this .arrayOI = ((ListObjectInspector) arguments[0 ]); this .arrayElementOI = this .arrayOI.getListElementObjectInspector(); this .valueOI = arguments[1 ]; if (!(ObjectInspectorUtils.compareTypes(this .arrayElementOI, this .valueOI))) { throw new UDFArgumentTypeException(1 , "\"" + this .arrayElementOI.getTypeName() + "\"" + " expected at function ARRAY_CONTAINS, but " + "\"" + this .valueOI.getTypeName() + "\"" + " is found" ); } if (!(ObjectInspectorUtils.compareSupported(this .valueOI))) { throw new UDFArgumentException("The function ARRAY_CONTAINS does not support comparison for \"" + this .valueOI.getTypeName() + "\"" + " types" ); } this .result = new BooleanWritable(false ); return PrimitiveObjectInspectorFactory.writableBooleanObjectInspector; } public Object evaluate (GenericUDF.DeferredObject[] arguments) throws HiveException this .result.set(false ); Object array = arguments[0 ].get(); Object value = arguments[1 ].get(); int arrayLength = this .arrayOI.getListLength(array); if ((value == null ) || (arrayLength <= 0 )) { return this .result; } for (int i = 0 ; i < arrayLength; ++i) { Object listElement = this .arrayOI.getListElement(array, i); if ((listElement == null ) || (ObjectInspectorUtils.compare(value, this .valueOI, listElement, this .arrayElementOI) != 0 )) continue ; this .result.set(true ); break ; } return this .result; } public String getDisplayString (String[] children) assert (children.length == 2 ); return "array_contains(" + children[0 ] + ", " + children[1 ] + ")" ; } }
1 2 3 4 5 6 7 8 9 其中,在configure方法中,获取了本次任务的Map Task数目; 在initialize方法中,初始化了一个变量init,并定义了返回类型为java的List类型; getDisplayString方法中显示函数的用法; evaluate是核心的逻辑处理; 需要特别注意的是,configure方法,“This is only called in runtime of MapRedTask”,该方法只有在运行map task时候才被执行。它和initialize用法不一样,如果在initialize时候去使用MapredContext,则会报Null,因为此时MapredContext还是Null。
使用与UDF的使用同(同上)
2.2 UDAF 2.2.1 AbstractGenericUDAFResolver&GenericUDAFEvaluator 1 两个抽象类简介 为了更好理解上述抽象类的API,要记住hive只是mapreduce函数,只不过hive已经帮助我们写好并隐藏mapreduce,向上提供简洁的sql函数,所以我们要结合Mapper、Combiner与Reducer来帮助我们理解这个函数。要记住在hadoop集群中有若干台机器,在不同的机器上Mapper与Reducer任务独立运行。
所以大体上来说,这个UDAF函数读取数据(mapper),聚集一堆mapper输出到部分聚集结果(combiner),并且最终创建一个最终的聚集结果(reducer)。因为我们跨域多个combiner进行聚集,所以我们需要保存部分聚集结果。
AbstractGenericUDAFResolverResolver很简单,要覆盖实现下面方法,该方法会根据sql传人的参数数据格式指定调用哪个Evaluator进行处理。
1 public GenericUDAFEvaluator getEvaluator (TypeInfo[] parameters) throws SemanticException
GenericUDAFEvaluatorUDAF逻辑处理主要发生在Evaluator中,要实现该抽象类的几个方法。
在理解Evaluator之前,必须先理解objectInspector接口与GenericUDAFEvaluator中的内部类Model。
ObjectInspector 作用主要是解耦数据使用与数据格式,使得数据流在输入输出端切换不同的输入输出格式,不同的Operator上使用不同的格式。可以参考这两篇文章: first post on Hive UDFs 、 Hive中ObjectInspector的作用 ,里面有关于objectinspector的介绍。
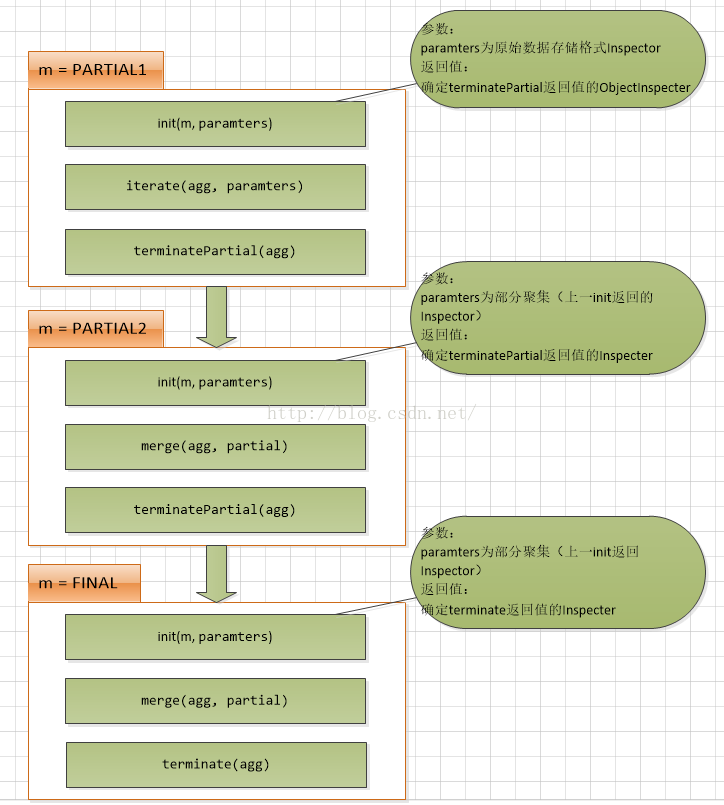
Model Model代表了UDAF在mapreduce的各个阶段。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static enum Mode PARTIAL1, PARTIAL2, FINAL, COMPLETE };
一般情况下,完整的UDAF逻辑是一个mapreduce过程,如果有mapper和reducer,就会经历PARTIAL1(mapper),FINAL(reducer),如果还有combiner,那就会经历PARTIAL1(mapper),PARTIAL2(combiner),FINAL(reducer)。
而有一些情况下的mapreduce,只有mapper,而没有reducer,所以就会只有COMPLETE阶段,这个阶段直接输入原始数据,出结果。
GenericUDAFEvaluator的方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public ObjectInspector init (Mode m, ObjectInspector[] parameters) throws HiveException abstract AggregationBuffer getNewAggregationBuffer () throws HiveException public void reset (AggregationBuffer agg) throws HiveException public void iterate (AggregationBuffer agg, Object[] parameters) throws HiveException public Object terminatePartial (AggregationBuffer agg) throws HiveException public void merge (AggregationBuffer agg, Object partial) throws HiveException public Object terminate (AggregationBuffer agg) throws HiveException
图解Model与Evaluator关系
Model各阶段对应Evaluator方法调用
Evaluator各个阶段下处理mapreduce流程
2 实例 下面将讲述一个聚集函数UDAF的实例,我们将计算表中的name字母的个数。
下面的函数代码是计算指定列中字符的总数(包括空格)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 @Description(name = "letters", value = "_FUNC_(expr) - 返回该列中所有字符串的字符总数") public class TotalNumOfLettersGenericUDAF extends AbstractGenericUDAFResolver @Override public GenericUDAFEvaluator getEvaluator (TypeInfo[] parameters) throws SemanticException { if (parameters.length != 1 ) { throw new UDFArgumentTypeException(parameters.length - 1 , "Exactly one argument is expected." ); } ObjectInspector oi = TypeInfoUtils.getStandardJavaObjectInspectorFromTypeInfo(parameters[0 ]); if (oi.getCategory() != ObjectInspector.Category.PRIMITIVE){ throw new UDFArgumentTypeException(0 , "Argument must be PRIMITIVE, but " + oi.getCategory().name() + " was passed." ); } PrimitiveObjectInspector inputOI = (PrimitiveObjectInspector) oi; if (inputOI.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING){ throw new UDFArgumentTypeException(0 , "Argument must be String, but " + inputOI.getPrimitiveCategory().name() + " was passed." ); } return new TotalNumOfLettersEvaluator(); } public static class TotalNumOfLettersEvaluator extends GenericUDAFEvaluator PrimitiveObjectInspector inputOI; ObjectInspector outputOI; PrimitiveObjectInspector integerOI; int total = 0 ; @Override public ObjectInspector init (Mode m, ObjectInspector[] parameters) throws HiveException { assert (parameters.length == 1 ); super .init(m, parameters); if (m == Mode.PARTIAL1 || m == Mode.COMPLETE) { inputOI = (PrimitiveObjectInspector) parameters[0 ]; } else { integerOI = (PrimitiveObjectInspector) parameters[0 ]; } outputOI = ObjectInspectorFactory.getReflectionObjectInspector(Integer.class, ObjectInspectorOptions.JAVA); return outputOI; } static class LetterSumAgg implements AggregationBuffer int sum = 0 ; void add (int num) sum += num; } } @Override public AggregationBuffer getNewAggregationBuffer () throws HiveException LetterSumAgg result = new LetterSumAgg(); return result; } @Override public void reset (AggregationBuffer agg) throws HiveException LetterSumAgg myagg = new LetterSumAgg(); } private boolean warned = false ; @Override public void iterate (AggregationBuffer agg, Object[] parameters) throws HiveException { assert (parameters.length == 1 ); if (parameters[0 ] != null ) { LetterSumAgg myagg = (LetterSumAgg) agg; Object p1 = ((PrimitiveObjectInspector) inputOI).getPrimitiveJavaObject(parameters[0 ]); myagg.add(String.valueOf(p1).length()); } } @Override public Object terminatePartial (AggregationBuffer agg) throws HiveException LetterSumAgg myagg = (LetterSumAgg) agg; total += myagg.sum; return total; } @Override public void merge (AggregationBuffer agg, Object partial) throws HiveException { if (partial != null ) { LetterSumAgg myagg1 = (LetterSumAgg) agg; Integer partialSum = (Integer) integerOI.getPrimitiveJavaObject(partial); LetterSumAgg myagg2 = new LetterSumAgg(); myagg2.add(partialSum); myagg1.add(myagg2.sum); } } @Override public Object terminate (AggregationBuffer agg) throws HiveException LetterSumAgg myagg = (LetterSumAgg) agg; total = myagg.sum; return myagg.sum; } } }
代码说明:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 static class LetterSumAgg implements AggregationBuffer int sum = 0 ; void add (int num) sum += num; } } if (m == Mode.PARTIAL1 || m == Mode.COMPLETE) { inputOI = (PrimitiveObjectInspector) parameters[0 ]; } else { integerOI = (PrimitiveObjectInspector) parameters[0 ]; } outputOI = ObjectInspectorFactory.getReflectionObjectInspector(Integer.class, ObjectInspectorOptions.JAVA); iterate()函数读取到每行中列的字符串,计算与保存该字符串的长度 public void iterate (AggregationBuffer agg, Object[] parameters) throws HiveException { ... Object p1 = ((PrimitiveObjectInspector) inputOI).getPrimitiveJavaObject(parameters[0 ]); myagg.add(String.valueOf(p1).length()); } } public void merge (AggregationBuffer agg, Object partial) throws HiveException { if (partial != null ) { LetterSumAgg myagg1 = (LetterSumAgg) agg; Integer partialSum = (Integer) integerOI.getPrimitiveJavaObject(partial); LetterSumAgg myagg2 = new LetterSumAgg(); myagg2.add(partialSum); myagg1.add(myagg2.sum); } } public Object terminate (AggregationBuffer agg) throws HiveException LetterSumAgg myagg = (LetterSumAgg) agg; total = myagg.sum; return myagg.sum; }
使用同上;
2.2.2 UDAF&UDAFEvaluator 1、一下两个包是必须的import org.apache.hadoop.hive.ql.exec.UDAF和 org.apache.hadoop.hive.ql.exec.UDAFEvaluator。
2、函数类需要继承UDAF类,内部类Evaluator实UDAFEvaluator接口。
3、Evaluator需要实现 init、iterate、terminatePartial、merge、terminate这几个函数。
a)init函数实现接口UDAFEvaluator的init函数。
b)iterate接收传入的参数,并进行内部的轮转。其返回类型为boolean。
c)terminatePartial无参数,其为iterate函数轮转结束后,返回轮转数据,terminatePartial类似于hadoop的Combiner。
d)merge接收terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean。
e)terminate返回最终的聚集函数结果。
代码示例,用于计算商户星级的平均价格的UDAF
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 import java.util.ArrayList;import java.util.List;import org.apache.hadoop.hive.ql.exec.UDAF;import org.apache.hadoop.hive.ql.exec.UDAFEvaluator; public final class AvgPriceUDAF extends UDAF public static class UDAFAvgPriceState private List<Integer> oldPriceList = new ArrayList<Integer>(); private List<Integer> newPriceList = new ArrayList<Integer>(); } public static class UDAFAvgPriceEvaluator implements UDAFEvaluator UDAFAvgPriceState state; public UDAFAvgPriceEvaluator () super (); state = new UDAFAvgPriceState(); init(); } public void init () state.oldPriceList = new ArrayList<Integer>(); state.newPriceList = new ArrayList<Integer>(); } public boolean iterate (Integer avgPirce, Integer old) if (avgPirce != null ) { if (old == 1 ) state.oldPriceList.add(avgPirce); else state.newPriceList.add(avgPirce); } return true ; } public UDAFAvgPriceState terminatePartial () return (state.oldPriceList == null && state.newPriceList == null ) ? null : state; } public boolean merge (UDAFAvgPriceState o) if (o != null ) { state.oldPriceList.addAll(o.oldPriceList); state.newPriceList.addAll(o.newPriceList); } return true ; } public Integer terminate () Integer avgPirce = 0 ; if (state.oldPriceList.size() >= 8 && state.newPriceList.size() >= 12 ) { avgPirce = (CalcAvgPriceUtil.calcInterquartileMean(state.oldPriceList) * 2 + CalcAvgPriceUtil.calcInterquartileMean(state.newPriceList) * 8 ) / 10 ; } else { state.newPriceList.addAll(state.oldPriceList); avgPirce = CalcAvgPriceUtil.calcInterquartileMean(state.newPriceList); } return avgPirce == 0 ? null : avgPirce; } } private AvgPriceUDAF () } }
使用同上
2.3 UDTF UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward()调用产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
最后close()方法调用,对需要清理的方法进行清理。
实例: 功能:一个用来切分”key:value;key:value;”这种字符串,返回结果为key, value两个字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import java.util.ArrayList; import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF; import org.apache.hadoop.hive.ql.exec.UDFArgumentException; import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException; import org.apache.hadoop.hive.ql.metadata.HiveException; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory; import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory; public class ExplodeMap extends GenericUDTF @Override public void close () throws HiveException } @Override public StructObjectInspector initialize (ObjectInspector[] args) throws UDFArgumentException { if (args.length != 1 ) { throw new UDFArgumentLengthException("ExplodeMap takes only one argument" ); } if (args[0 ].getCategory() != ObjectInspector.Category.PRIMITIVE) { throw new UDFArgumentException("ExplodeMap takes string as a parameter" ); } ArrayList<String> fieldNames = new ArrayList<String>(); ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>(); fieldNames.add("col1" ); fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector); fieldNames.add("col2" ); fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector); return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOIs); } @Override public void process (Object[] args) throws HiveException String input = args[0 ].toString(); String[] test = input.split(";" ); for (int i=0 ; i<test.length; i++) { try { String[] result = test[i].split(":" ); forward(result); } catch (Exception e) { continue ; } } } }
UDTF的使用: UDTF有两种使用方法,一种直接放到select后面,一种和lateral view一起使用。(参考explode)
1:直接select中使用 1 select explode_map(properties) as (col1,col2) from src;
不可以添加其他字段使用
1 select a, explode_map(properties) as (col1,col2) from src
不可以嵌套调用
1 select explode_map(explode_map(properties)) from src
不可以和group by/cluster by/distribute by/sort by一起使用
1 select explode_map(properties) as (col1,col2) from src group by col1, col2
2 和lateral view 一起使用 1 select src.id, mytable.col1, mytable.col2 from src lateral view explode_map(properties) mytable as col1, col2;
此方法更为方便日常使用。执行过程相当于单独执行了两次抽取,然后union到一个表里。
三 基于Python的UDF 1 实例 需求简介:
我们这里用python自定义函数,去实现一个方法,利用身份证号去判断性别(18位身份证的倒数第二位偶数为女,奇数为男.15位身份证的倒数第一位偶数为女,奇数为男.).其实这个需求可以使用hive自带的function去进行解决.我们接下来使用python编写udf去实现这个需求.
1 2 3 4 5 6 7 8 9 10 11 12 select idcard,case when length (idcard) = 18 then case when substring (idcard,-2 ,1 ) % 2 = 1 then '男' when substring (idcard,-2 ,1 ) % 2 = 0 then '女' else 'unknown' end when length (idcard) = 15 then case when substring (idcard,-1 ,1 ) % 2 = 1 then '男' when substring (idcard,-1 ,1 ) % 2 = 0 then '女' else 'unknown' end else '不合法' end from person;
UDF: person.py 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import sysfor line in sys.stdin: detail = line.strip().split("\t" ) if len(detail) != 2 : continue else : name = detail[0 ] idcard = detail[1 ] if len(idcard) == 15 : if int(idcard[-1 ]) % 2 == 0 : print("\t" .join([name,idcard,"女" ])) else : print("\t" .join([name,idcard,"男" ])) elif len(idcard) == 18 : if int(idcard[-2 ]) % 2 == 0 : print("\t" .join([name,idcard,"女" ])) else : print("\t" .join([name,idcard,"男" ])) else : print("\t" .join([name,idcard,"身份信息不合法!" ]))
这里我们使用python的重定向,将hive控制台的输出进行split,split默认使用的为\t .然后根据split后的idcard的倒数第二位进行判断这个人的性别.
2 使用 我们在hive中使用python定义的UDF函数要借助transform函数去执行.
Hive 的 TRANSFORM 关键字提供了在 SQL 中调用自写脚本的功能。适合实现 Hive 中没有的 功能又不想写 UDF 的情况,脚本一般都是python写的。
transform函数的语法如下:
1 2 3 4 SELECT TRANSFORM (<columns >)USING 'python <python_script>' AS (<columns >)FROM <table >;
transfrom和as的columns的个数不必一致.
我们在hive中去执行如下代码:
1 2 3 add file /xxx/person.py 在hue上面执行有个bug: 使用 add file hdfs://path/xxxx.py; 时 重新运行且内容改变这个Python的名字也得改变 否则一直报错
然后执行:
1 select transform(name ,idcard) USING 'python person.py' AS (name ,idcard,gender) from person;
存在的问题: (摘自https://www.jianshu.com/p/6a5d9f910f1a 我没有去测试(所以存疑))
在数据清洗过程中,如果使用的是TransForm而不是UDF的话,因为Python是直接向系统申请资源的,而不是像ResourceManager申请资源,故会导致启动的Python脚本对内存和CPU的使用不可控,尤其是当启动多个Map时,因为一个map将启动一个Python因此,当同时运行的map有几十个时(测试集群较小),同时将尝试启动相同个数的python(资源够用的话仍然会启动几十个),且此时Map占用的内存是不会释放掉的他在一直等待Python的结果,这将导致python可用的资源仅仅是原本分配给系统的很少的资源(注:在安装Hadoop时,对于单个节点,一般仅仅给系统留出很少的内存,其他的内存全部分给了集群。例如32G物理内存的节点给系统和dataNode+nodeManager的内存就4-8个G,同时CPU核数也不足节点的一半,剩余的内存和cpu核数全部划分给集群使用。需要注意的是,这里虽然说是划分给集群使用,仅仅是逻辑上的划分,即规定集群可以使用的最大的物理内存,超过该内存时MR可以认为是不会抢占分配给系统+DataNode+nodeManager的内存的,但是当集群中没有MR在执行,即没有map或者reduce在执行时,划分给集群的这部分资源是可以被系统使用的。而若有map和Reduce在执行时,运行map和reduce的JVM的资源不会因为系统进程需要使用而被释放掉)所以,所有正在执行的Map一直在等待python的运行结果而没有释放掉其自身占用的资源,故python无法使用分配给集群的资源而只能使用预留给系统+nodeManager+DataNode的4-8G的内存和很少的cpu核数。因此会导致集群的资源无法被高效利用。
综上,使用Transform(Python)执行效率低的根本原因在于Python是直接向操作系统申请资源,而不是向YARN的ResourceManager申请资源,故而导致节点的资源无法高效组织和被利用。此外,建议不要轻易使用transform!