1 流式处理的提出
1.1 传统的数据处理架构
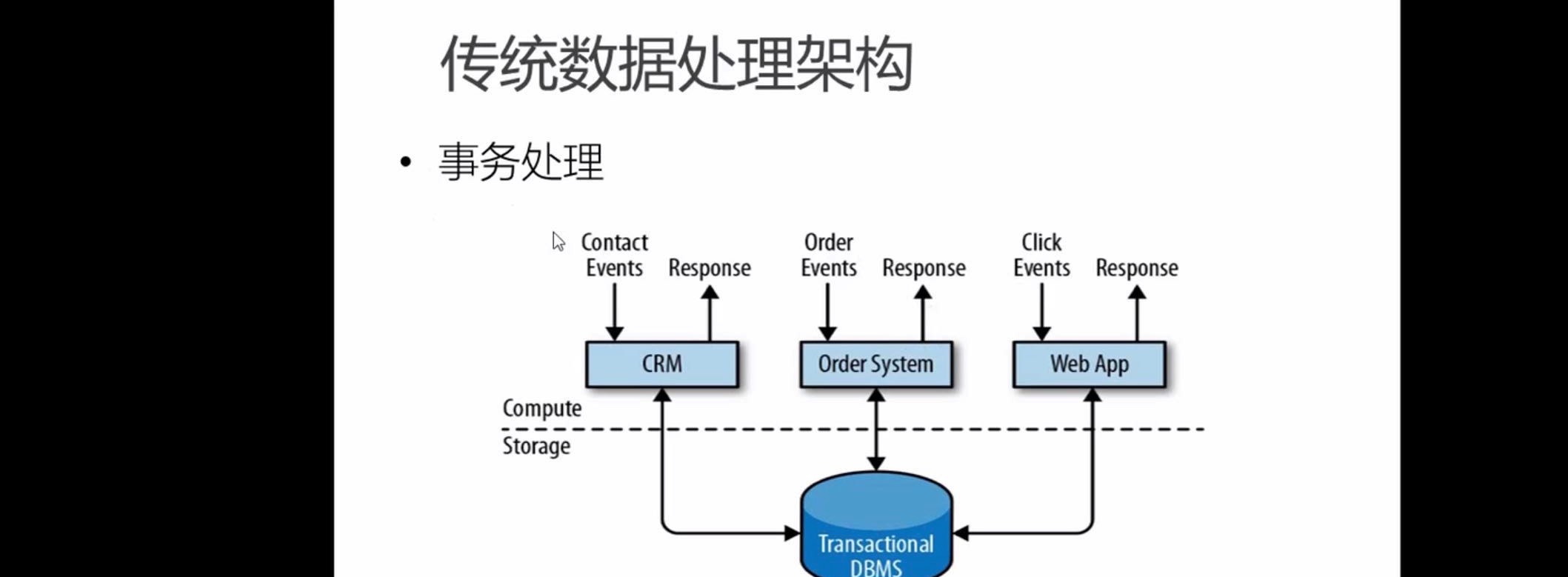
总体分为两层,计算层和存储层,后端接受请求,并响应,期间把数据存到传统的关系型数据库,而当数据量变大的时候或者每次请求的数据和点击的数据不一定非要存储到数据库里,而且也不一定所有的数据都要存储,而是只存储强业务关联的数据.就衍生出分析处理的架构 (吞吐量低)
1.2 分析处理的架构
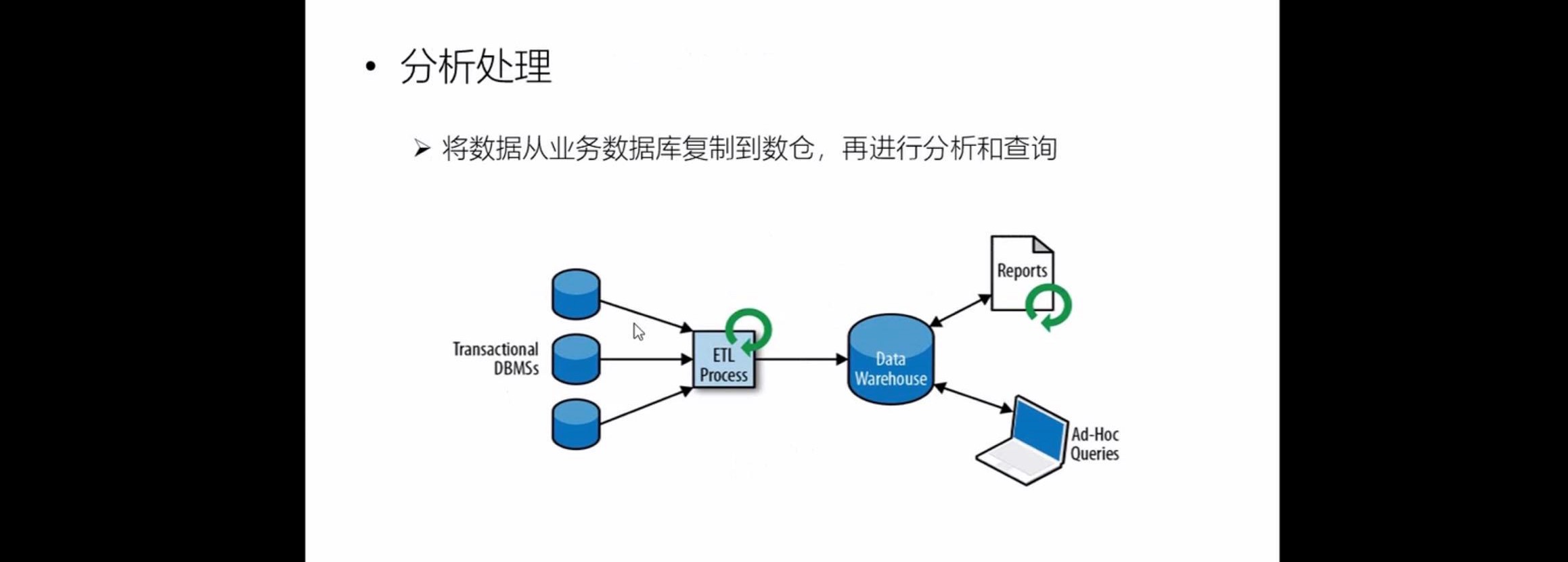
这个就是离线的数据处理,不做过多解释说明
与前面的架构相比优点:吞吐量更高
缺点:实时性变低
若想实时性高,吞吐量高就衍生出了流式处理架构
1.3 流式处理架构
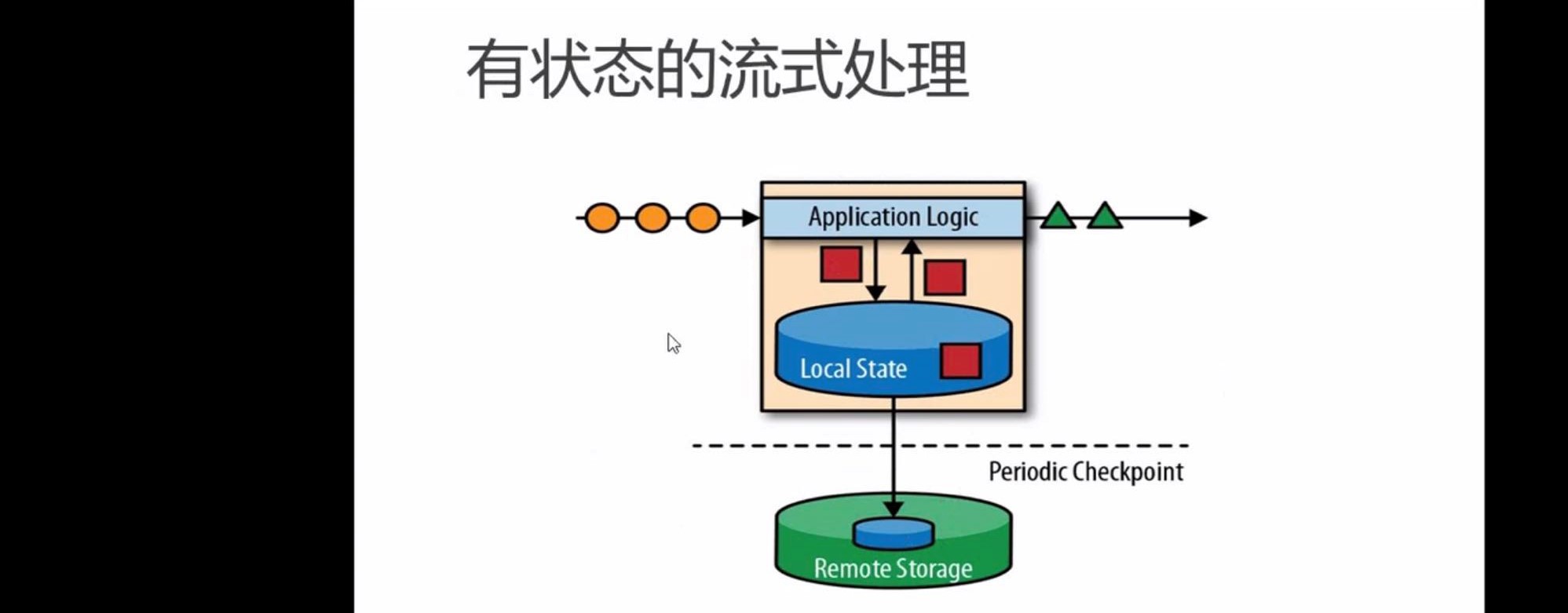
有状态的流式操作:
数据过来一条,使用预先写好的逻辑处理一条,每一条都对应一个输出,在输出之前可能会用到其他的数据,这些数据之前是存到数据库里,现在不是了,直接把他叫做本地状态放在本地内存里,放在内存里快是快但有问题,一旦断电等,内存中的数据都没了为了容错,做定期的恢复,就需要定时对当前的状态做一个存盘,(周期性的检查点checkpoint)
当有多个分区时,多个分区的数据共同处理,就出现了shuffle,切有时还要保证数据先进来,优先被计算(处理延迟数据:如算今日uv有些数据因为网络延迟等原因数据晚来了,所以数据有时是不准的)数据是乱序的,为了保证数据的正确性,就出现了新的架构lambda
lambda架构:
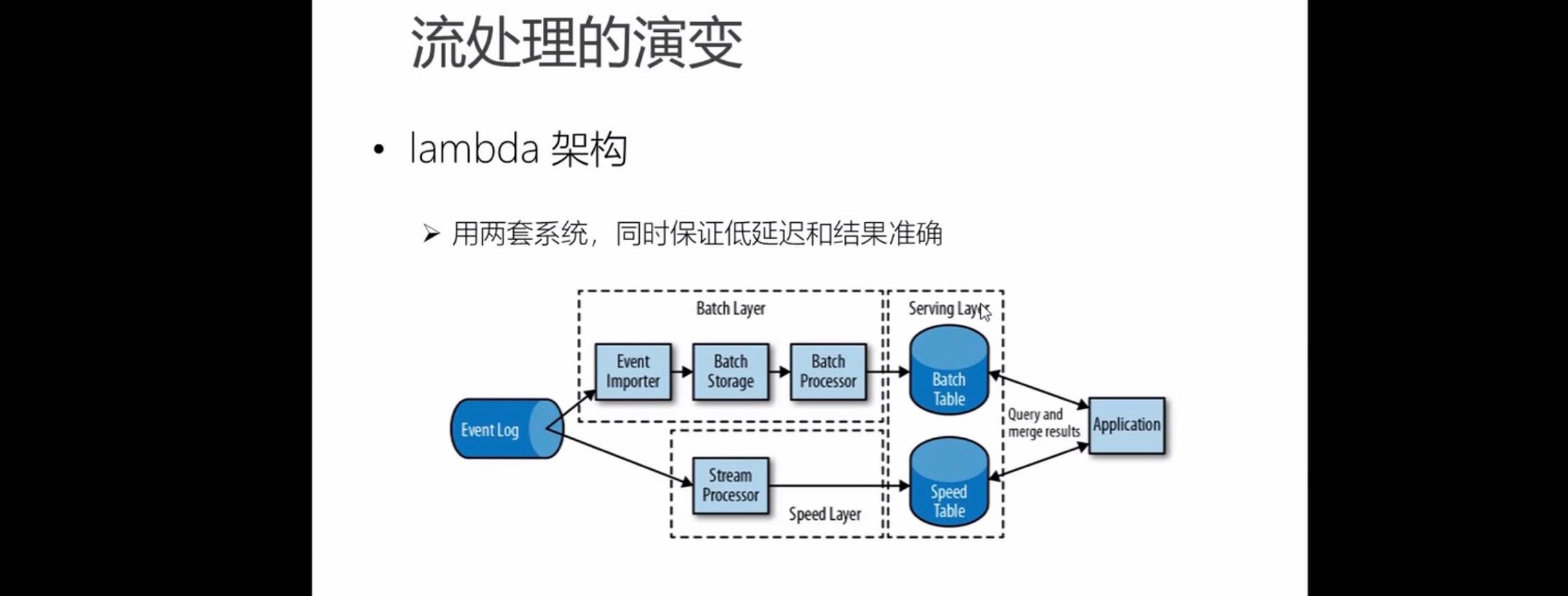
用两套系统同时保证低延迟和数据结果的准确
流处理保证低延迟,批处理保证数据结果的准确性,最后两张表的数据进行合并
实际上sparkstreaming(折中方案)有点类似于这个架构,就是微批流(但实际还是一批一批的处理,谈不上真正的实时,秒级别的延迟)且无法处理乱序数据,不支持更多的时间语义
开发,维护,迭代麻烦
第三代流处理flink
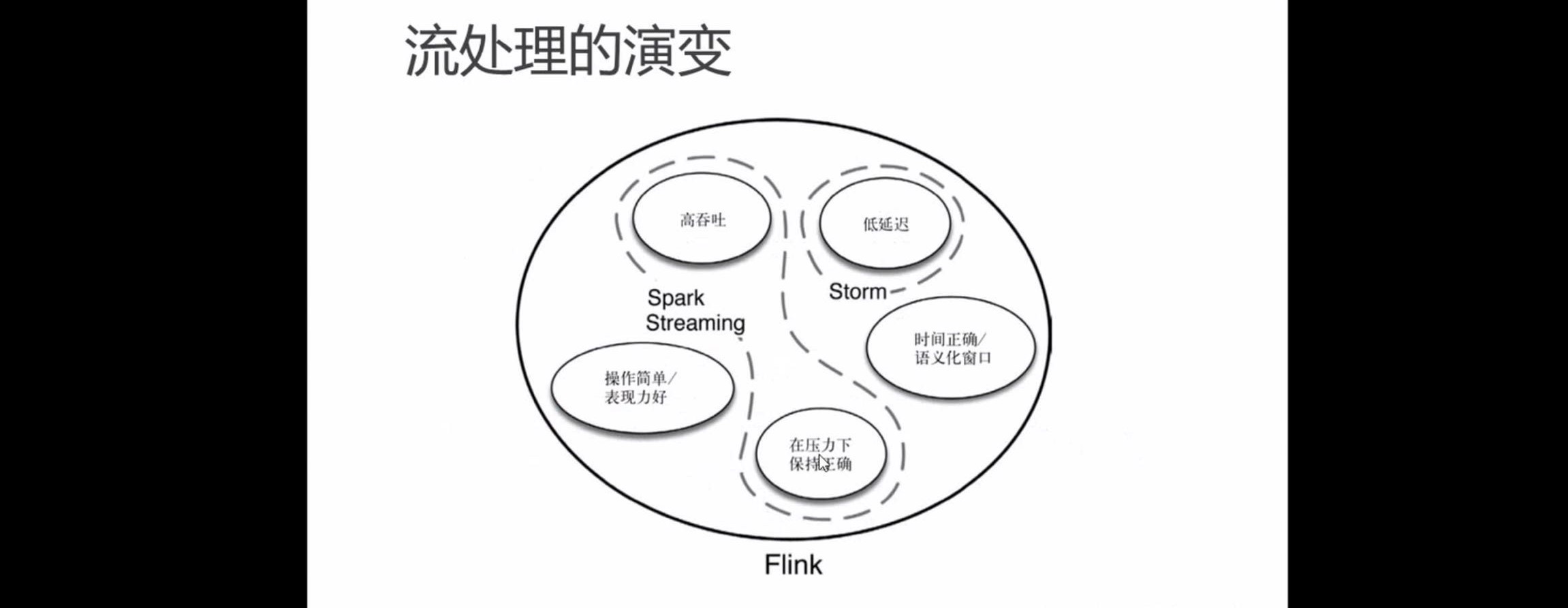
主要特点:
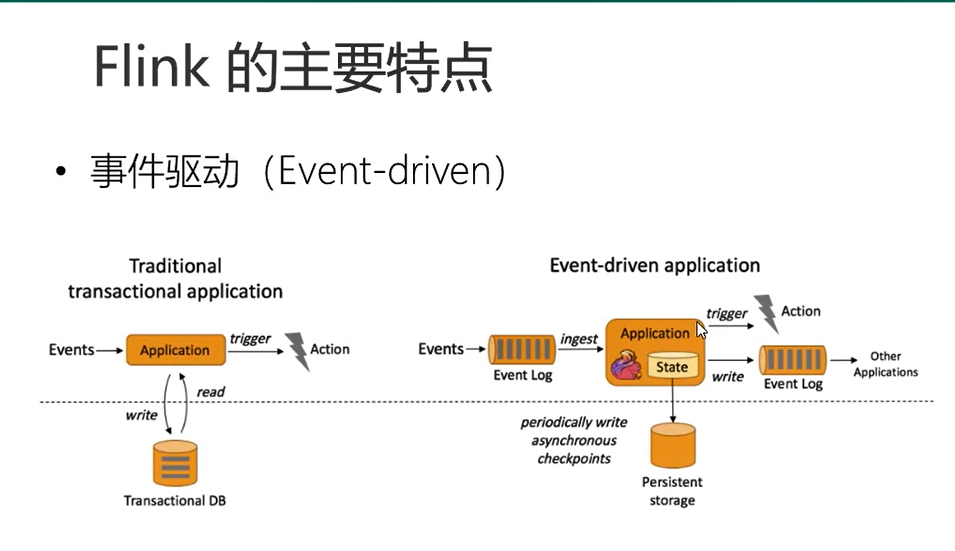
1事件驱动:
如左侧的web应用,web服务器一直启动在这里,等到有事件来的时候(用户发起请求),web服务器根据处理逻辑去处理数据,跟数据库进行读写,最后响应会用户
flink的事件驱动:用户的一条数据就可以理解为一个事件
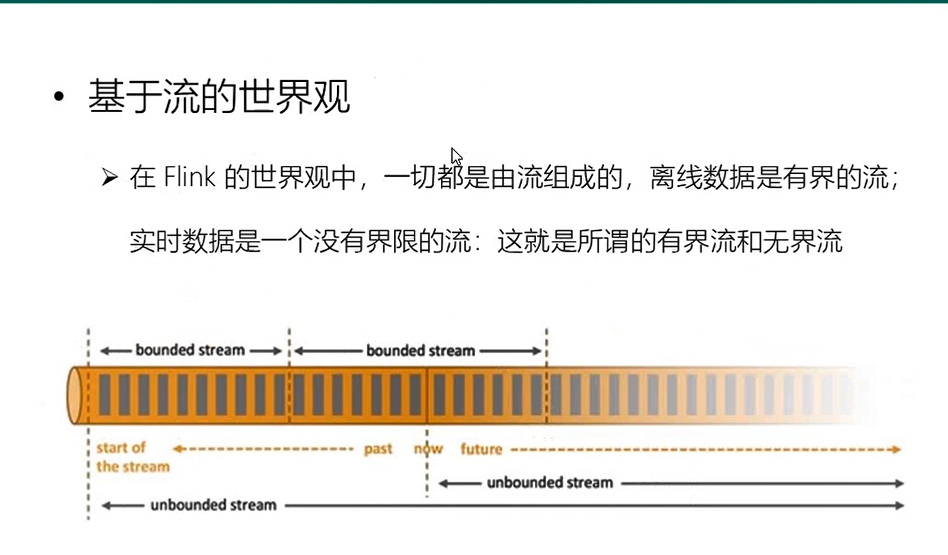
2基于流的世界观:
3分层的api
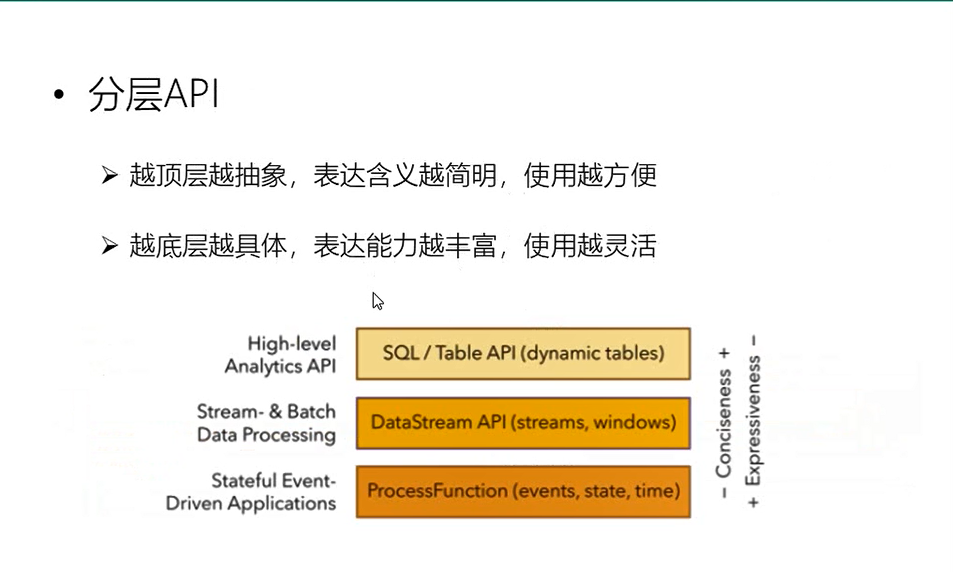
4 flink其他的特点
1 | 1 支持事件时间(event_time)和处理时间(processing-time) |
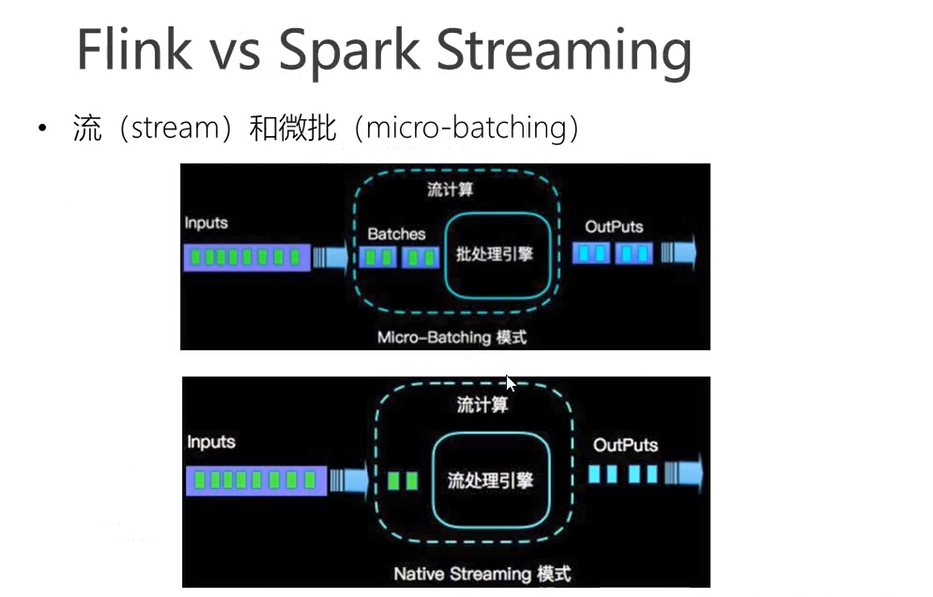
flink与sparkstreaming的区别