一 Flink运行时的组件
1 | 1:JObManger 作业管理器 |
1 任务完整流程
Flink程序需要提交给Job Client。 然后,Job Client将作业提交给Job Manager。 Job Manager负责协调资源分配和作业执行。 它首先要做的是分配所需的资源。 资源分配完成后,任务将提交给相应的Task Manager。 在接收任务时,Task Manager启动一个线程以开始执行。 执行到位时,Task Manager会继续向Job Manager报告状态更改。 可以有各种状态,例如开始执行,正在进行或已完成。 作业执行完成后,结果将发送回客户端(Job Client)。
2 JobManger
1 | 1:控制一个应用程序执行的主进程,每个应用程序都会被一个不同的JM所控制执行 |
master 进程(也称为作业管理器)协调和管理程序的执行。 他们的主要职责包括调度任务,管理检查点,故障恢复等。可以有多个Masters 并行运行并分担职责。 这有助于实现高可用性。 其中一个master需要成为leader。 如果leader 节点发生故障,master 节点(备用节点)将被选为领导者。
作业管理器包含以下重要组件:
Actor system:Flink内部使用Akka actor系统在作业管理器和任务管理器之间进行通信,spark的通信原先使用akka,后改为netty
1
2在Flink中,actor是具有状态和行为的容器。 actor的线程依次继续处理它将在其邮箱中接收的消息。 状态和行为由它收到的消息决定
Actor使用消息传递系统相互通信。 每个actor都有自己的邮箱,从中读取所有邮件。 如果actor是本地的,则消息通过共享内存共享,但如果actor是远程的,则通过RPC调用传递消息。Scheduler
Check pointing
3 TaskManger
1 | 1: Flink中的工作进程,通常Flink中会有多个Taskmanger运行,每一个Tm都包含一定数量的插槽(slots),插槽的数量限制了tm能够执行的任务数量(tm的数量*slot的数量=所有的slot的数量 这个数量代表了任务的总并行执行能力(不是并行度)) |
4 ResourceManger
1 | 1: 主要负责管理tm的插槽(slot),tm的插槽是flink中定义的处理资源的单位 |
5 Dispatcher
1 | 1:可以跨作业运行,为应用提供rest的接口 |
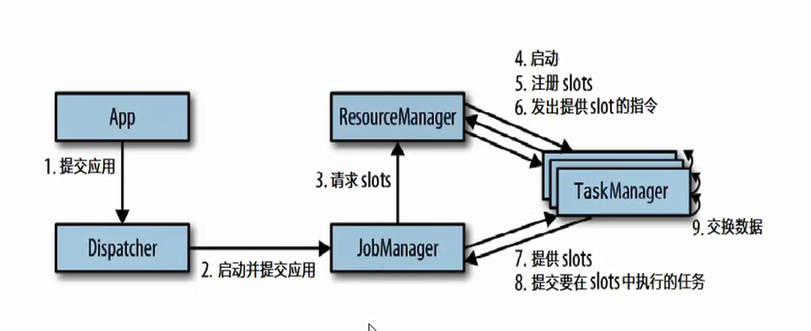
二 任务的提交流程
standalone的模式4和5 在集群启动的时候就已经完成
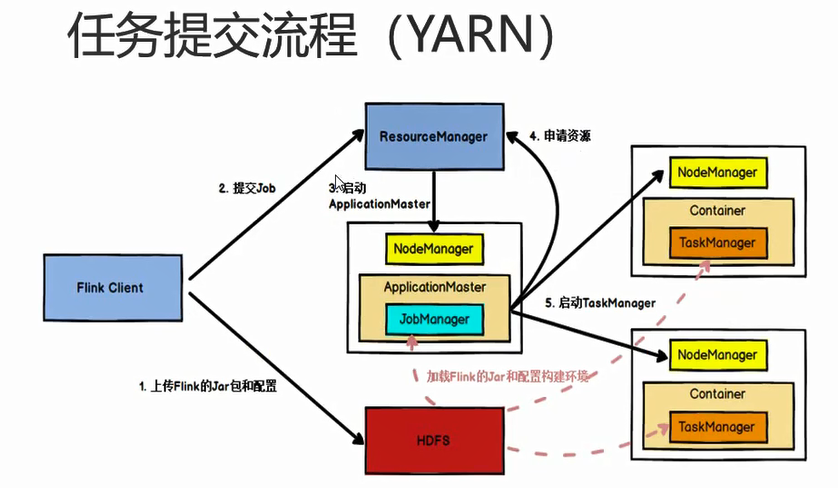
2 yarn模式(YARN-Cluster)(per_job)
图中的resourcemanger是yarn的resourcemanger,flink自己的resourcemanger在applicationMaster中。实际中flink先向自己的rm申请资源,flink的rm在向yarn的rm申请资源
三 任务调度原理
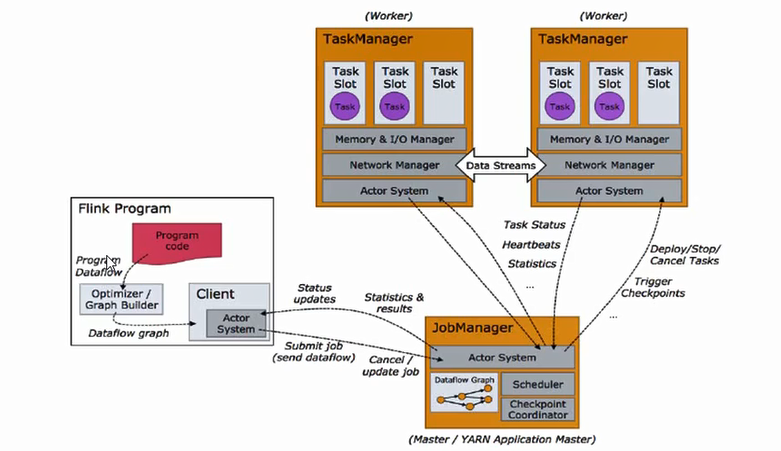
1 | 编写代码,代码经过编译打包,直接会生成一个dataFlow graph(数据流图),经过接口(client)发送期间会把能合并的数据操作进行合并,合并后得到job graph,提交给jobmanger,分析job流图,判断并行度,任务有几个子任务,需要的资源等,然后向resourcemanger申请资源,然后向worker分配任务 |
1 | 问题: |
3.1 并行度
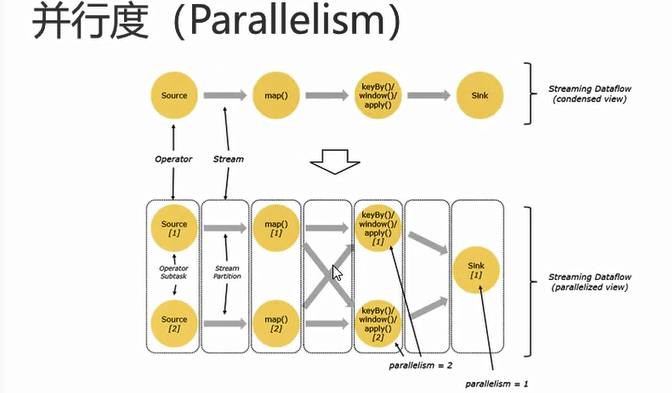
1 | 一个特定算子的子任务(subtask)的个数被称之为并行度(parallelism)(一般一个子任务占用一个slot). |
3.2 Taskmanger和slots
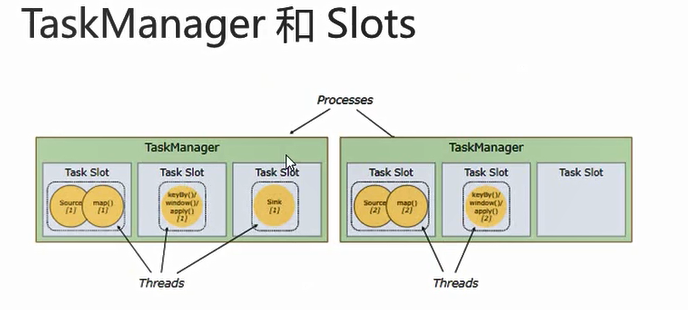
1 | 1: flink中每一个taskmanger都是一个jvm进程,它可能会在独立的线程上执行一个或多个子任务 |
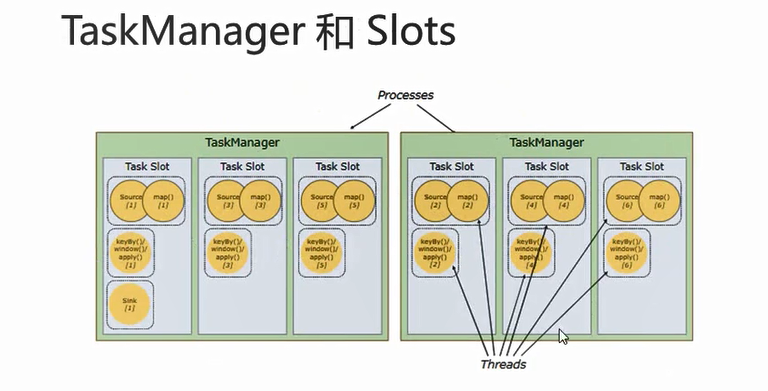
1 | 1:默认情况下,flink允许子任务共享slot,即使他们是不同任务的子任务,这样的结果是,一个slot可以保存作业的整个管道 |
3.3 并行子任务的分配
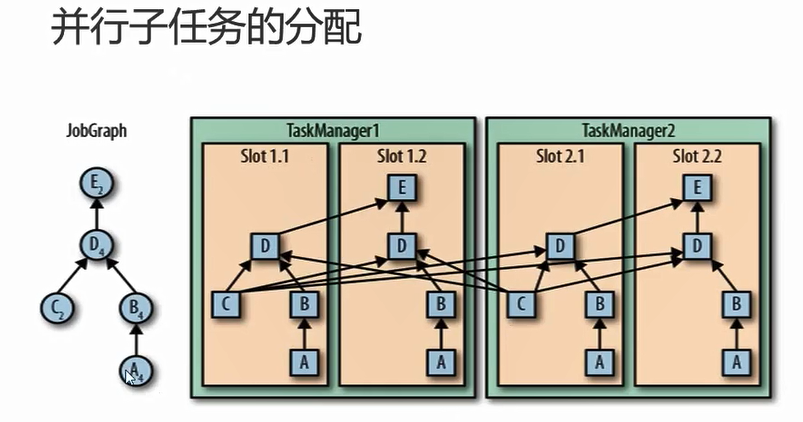
1 | 左侧的jobgraph的最大并行度是4,所以至少需要4个slot,具体分配a的并行度是4,四个slot依次都有,b并行度4,则4个slot都有,c的并行度为2,....(至于c和e具体分配到哪,这个可以配置,可以分配到不同的tm上,flink默认是随机) |
具体的实例
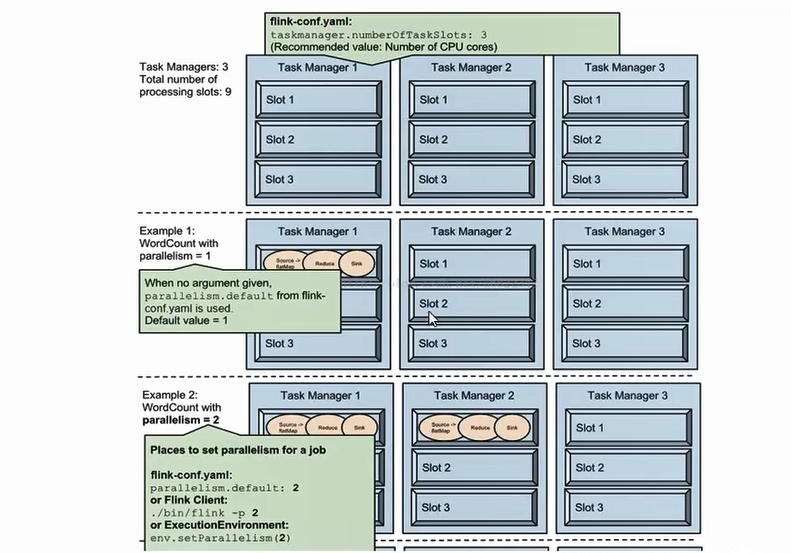
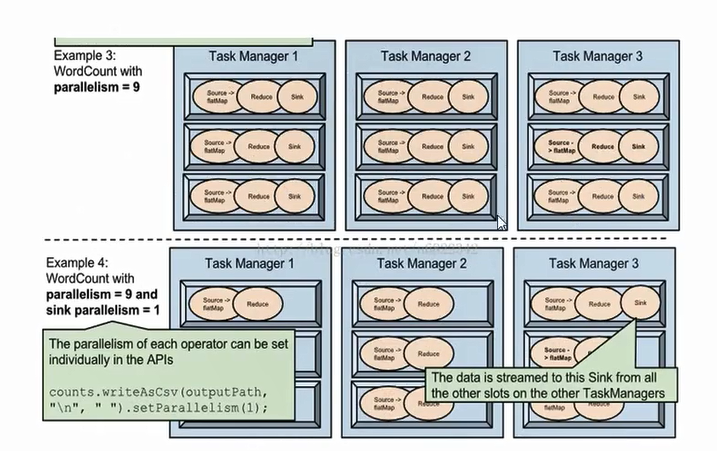
1 | 配置文件中的tm的slot的个数是3,例子1:类似于词频统计...不细说看图 |
3.4 程序与数据流
任务划分为几个子任务,有些情况会把任务合并成一个任务,有时不合,现在讨论这个问题
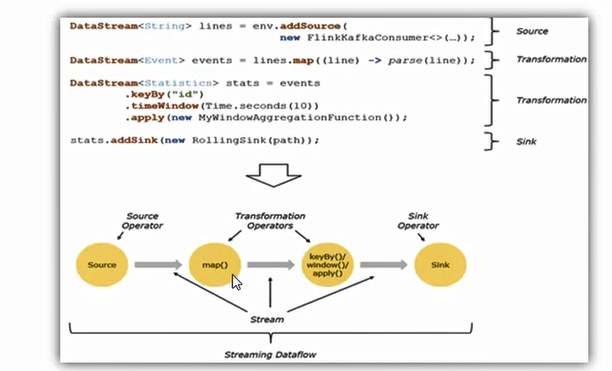
1 | 1:所有的flink程序是由三部分组成:Source,Transformation,sink |
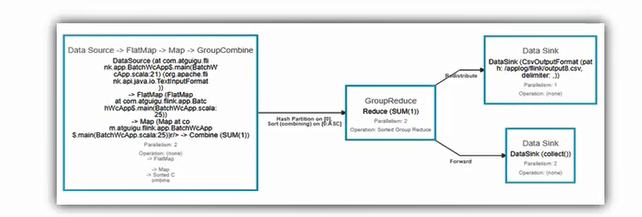
1 | 1:在运行时,fkink上运行的程序会被映射成逻辑数据流,包含三部分(source,transformation,sink) |
3.4.1 执行图
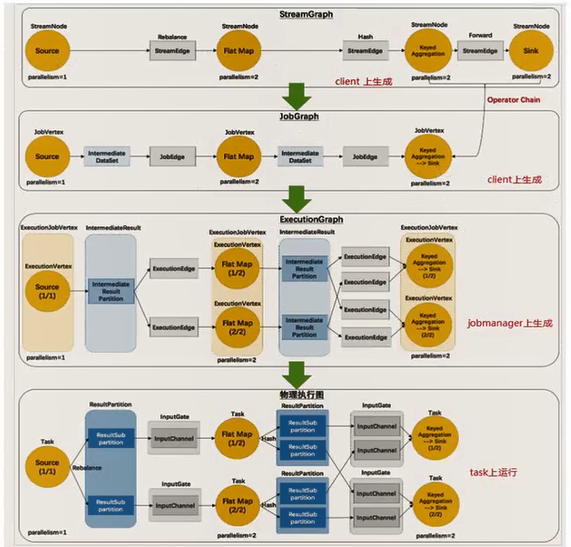
1 | 1:flink中的执行图可以划分为四层:StreamGraph->jobgraph->executionGraph->物理执行图 |
3.4.2 数据传输格式
1 | 1:一个程序中,不同的算子可能具有不同的并行度 |
3.4.3 任务链
1 | 1: flink采用了一种称为任务链的优化技术,可以在特定条件下减少本地通信的开销。为了满足任务链的要求,必须将两个或多个算子设为相同的并行度,并通过 本地转发(local forward)的方式进行 链接 |
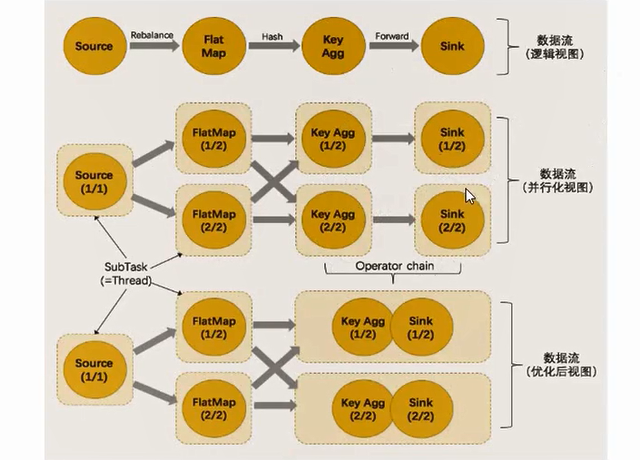
1 | 1:flink的算子有个方法disableChaining(),则这个算子不参与任务链合并,前后都断开: |