一 一致性检查点
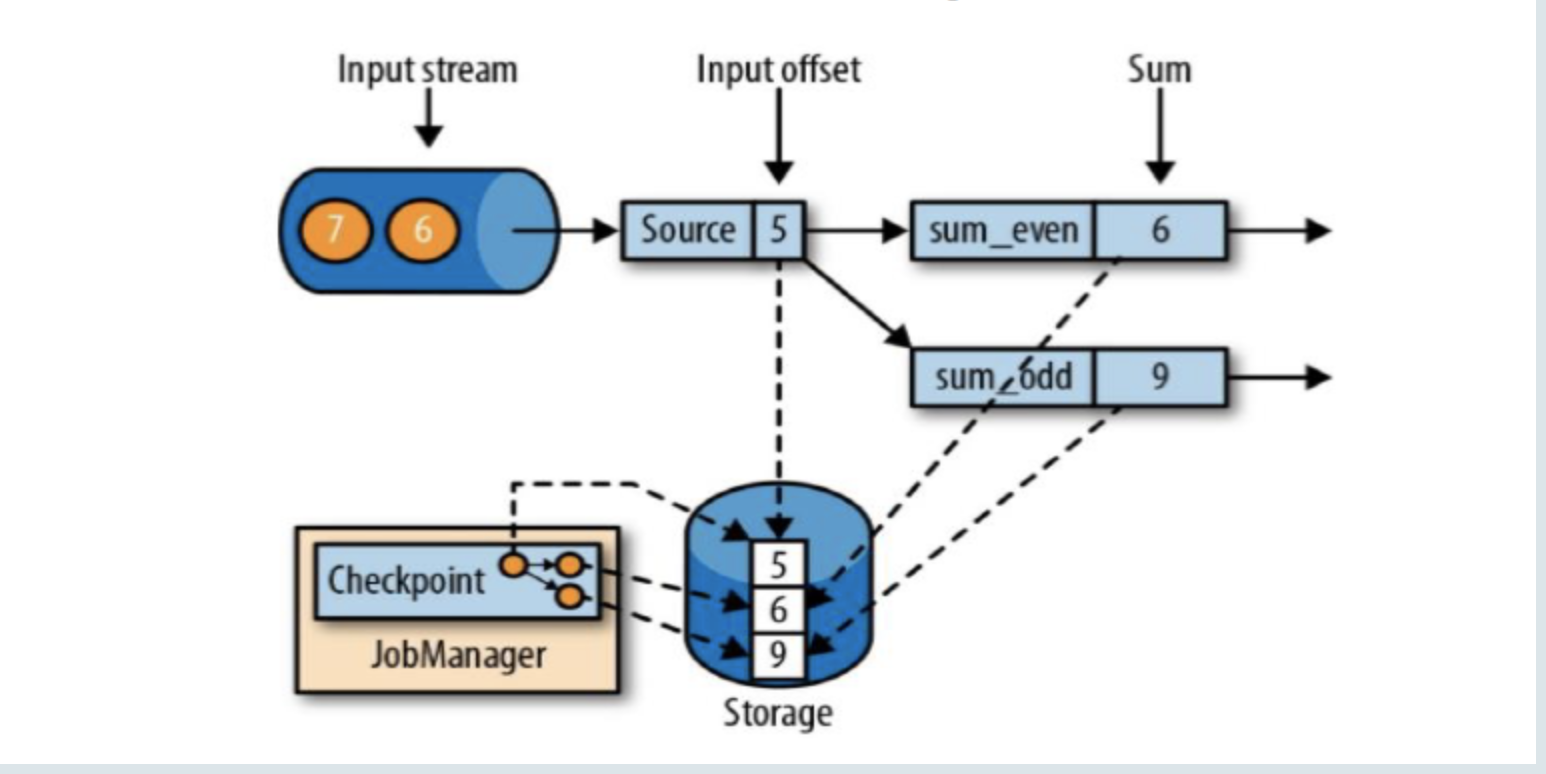
1 | 如上图sum_even (2+4),sum_odd(1 + 3 + 5),5这个数据之前的都处理完了,就出保存一个checkpoint;Source任务保存状态5,sum_event任务保存状态6,sum_odd保存状态是9;这三个保存到状态后端中就构成了CheckPoint; |
1 | 1:Flink故障恢复机制的核心,就是应用状态的一致性检查点; |
二 从检查点恢复状态
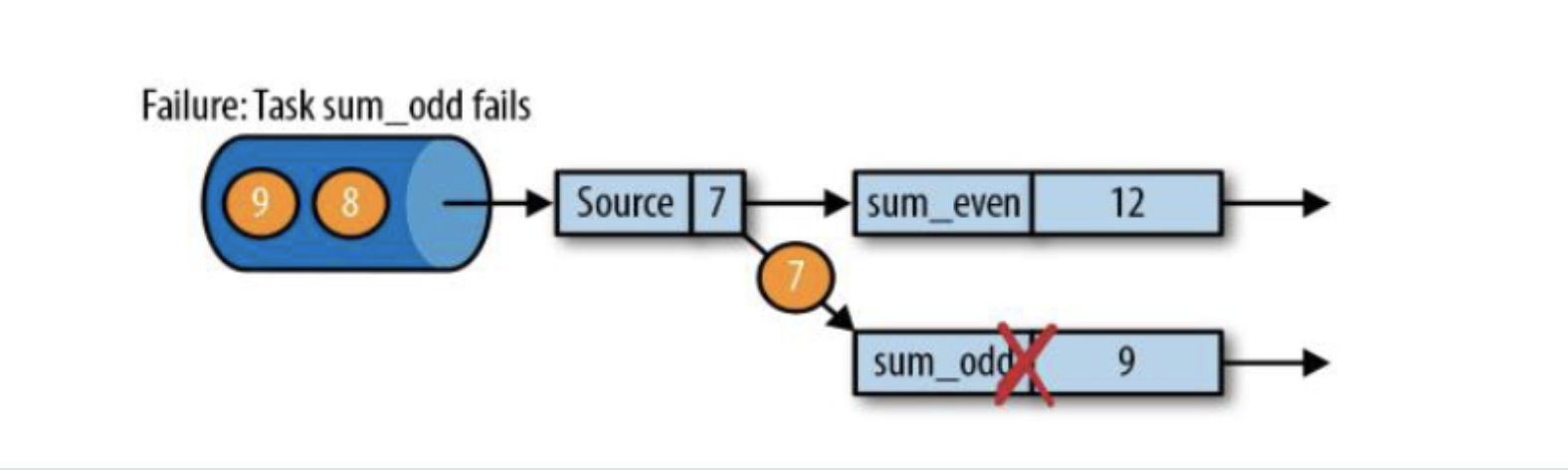
1 | sum_even(2 + 4 + 6);sum_odd(1 + 3 + 5); |
1:在执行应用程序期间,Flink会定期保存状态的一致性检查点;
2:如果发生故障,Flink将会使用最近的检查点来一致恢复应用程序的状态,并重新启动处理流程;
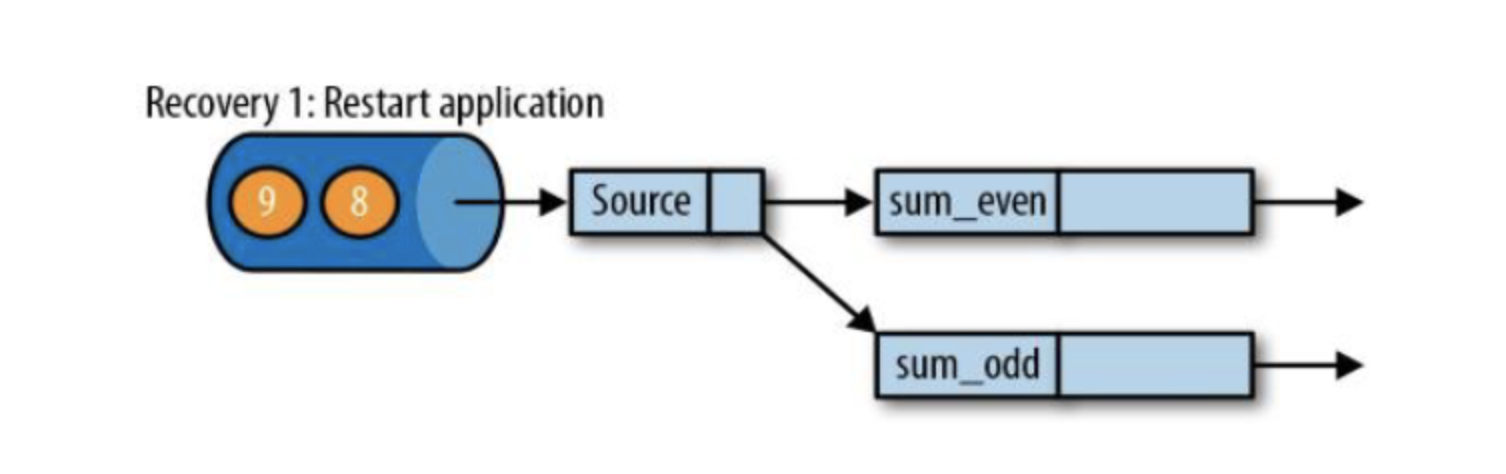
遇到故障之后,第一步就是重启应用;
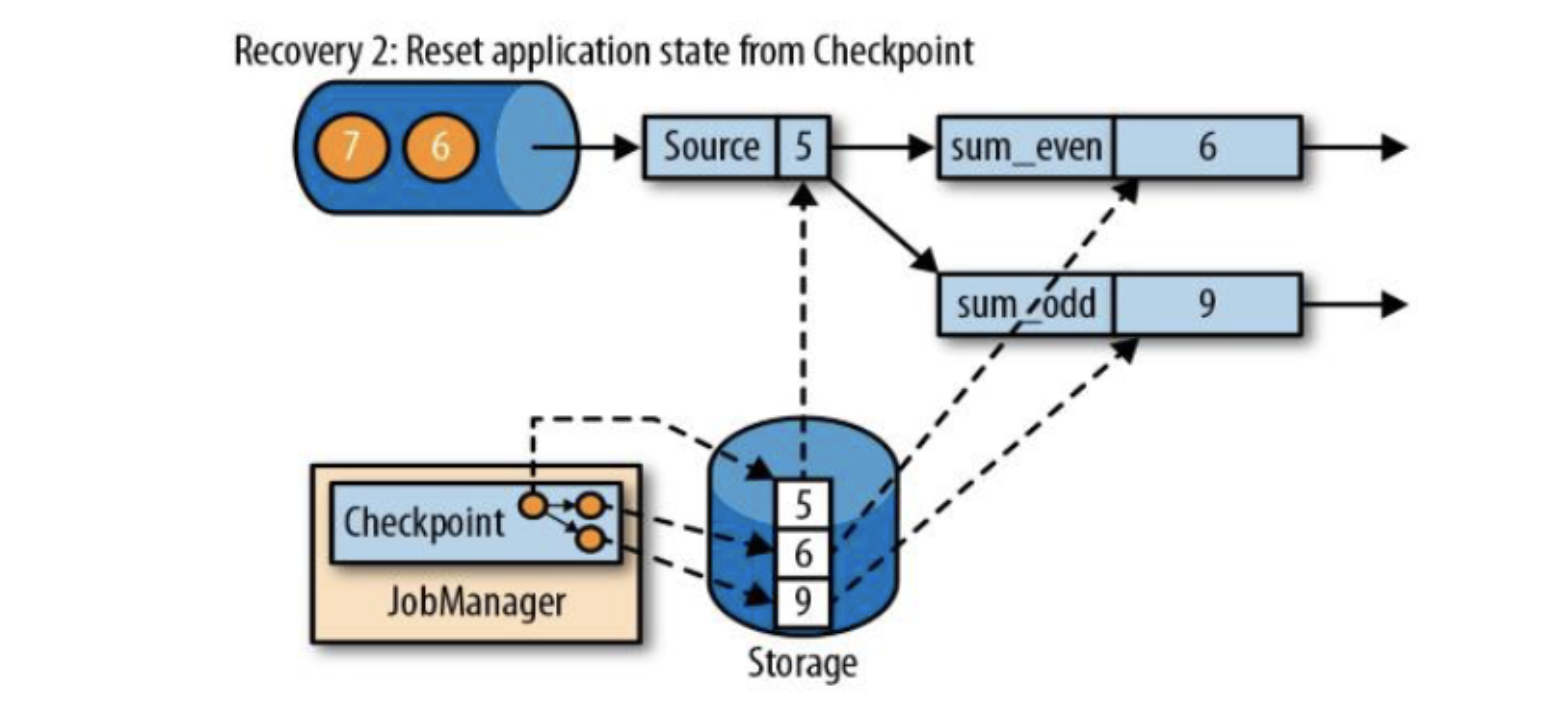
第二步是从checkpoint中读取状态,将状态重置;
从检查点重新启动应用程序后,其内部状态与检查点完成时的状态完全相同;
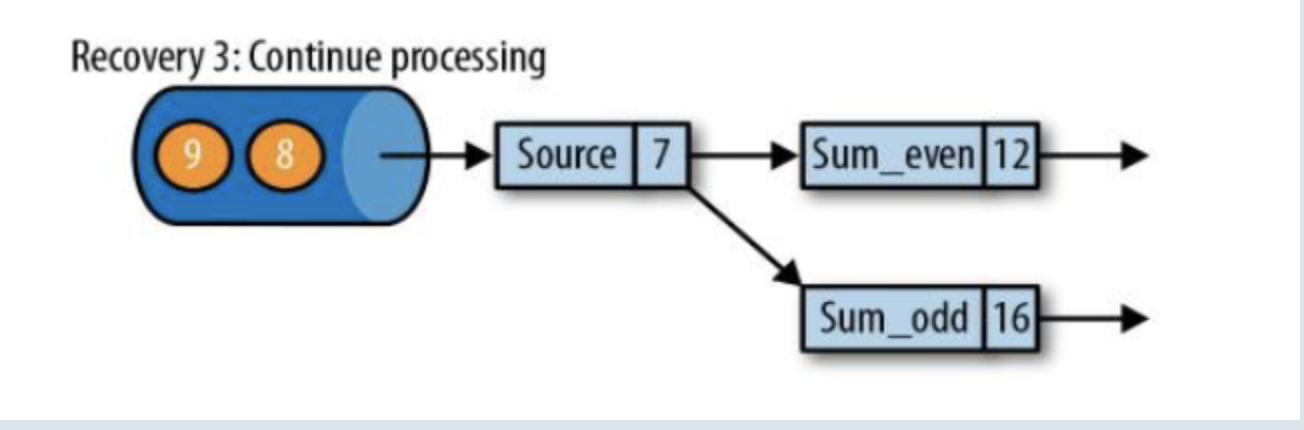
第三步 :开始消费并处理检查点到发生故障之间的所有数据;
这种检查点的保存和恢复机制可以为应用程序状态提供“精确一次”(exactly-once)的一致性,因为所有算子都会保存检查点并恢复其所有状态,这样一来所有的输入流就都会被重置到检查点完成时的位置。
三 Flink的检查点算法
1 | 1:简单:暂停应用,保存状态到检查点,再重新恢复应用; |
3.1检查点分界线(CheckPoint Barrier)
1 | 1:Flink的检查点算法用到了一种称为分界线(barrier)的特殊数据形式,用来把一条流上数据按照不同的检查点分开; |
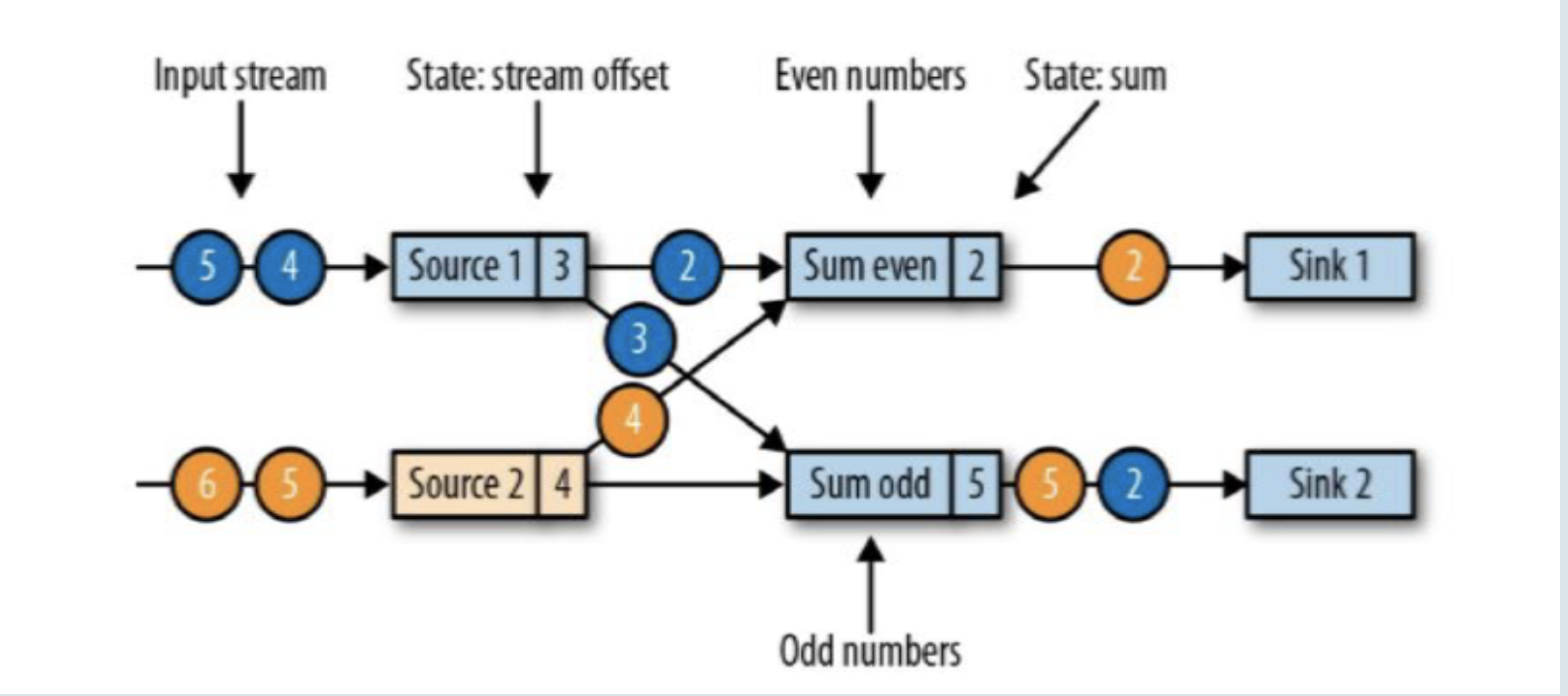
现在是一个有两个输入流的应用程序,用并行的两个Source任务来读取:
两个并行输入源按奇偶数来做sum,类似keyBy重分区map为二元组再做奇偶keyBy,Sum odd(1 + 1 + 3),Sum even(2)
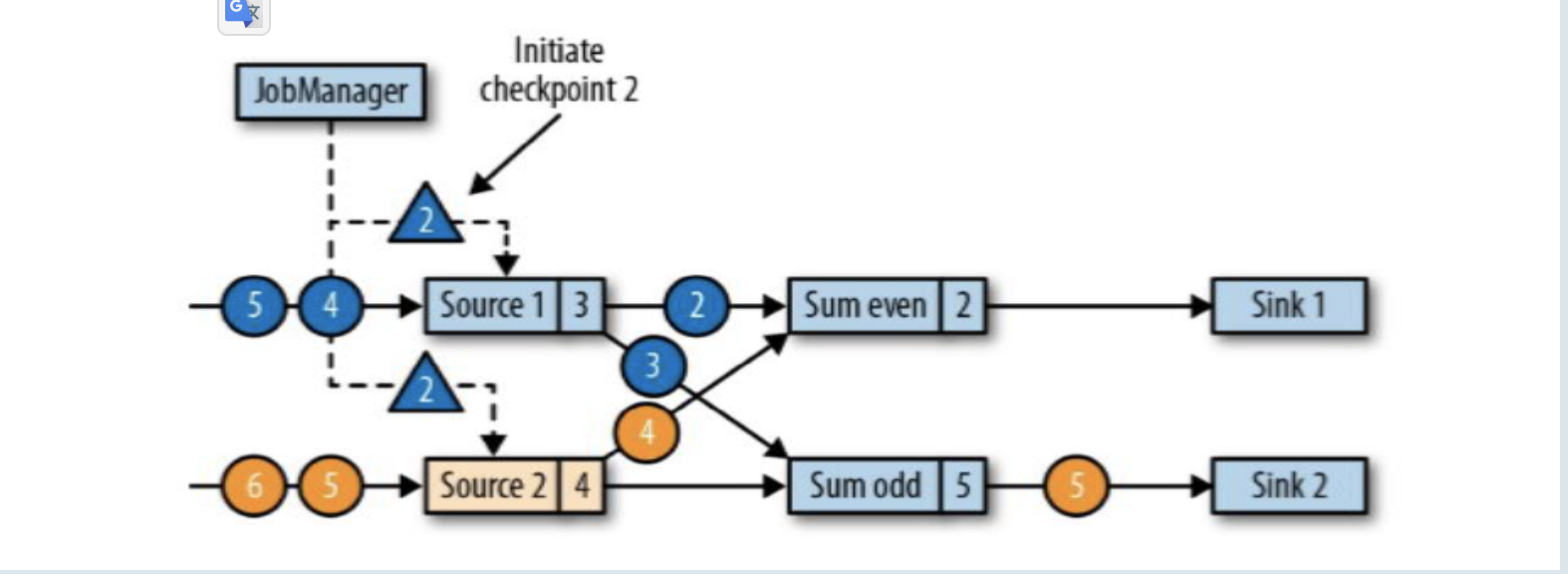
JobManager会向每个source任务发送一条带有新检查点ID的消息,通过这种方式来启动检查点;
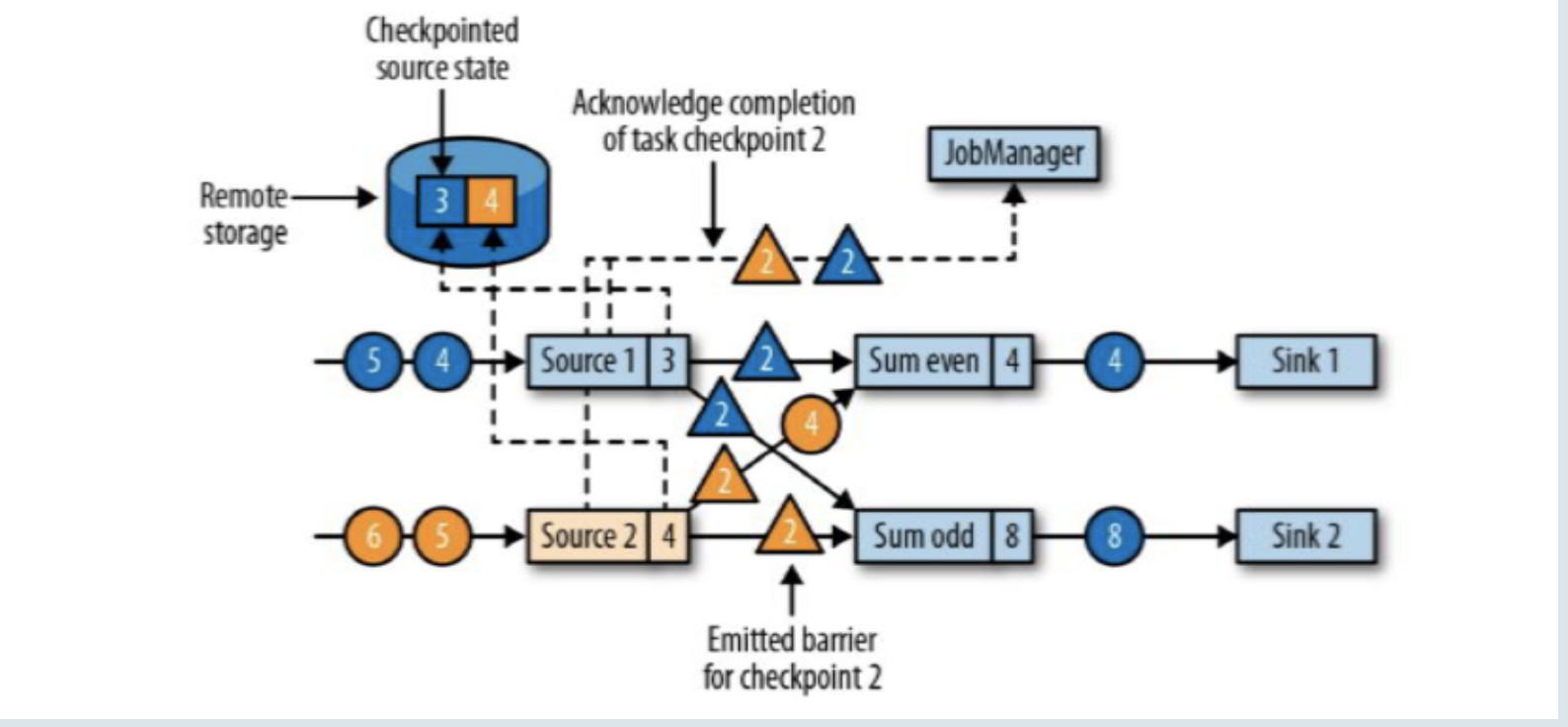
数据源将它们的状态写入检查点,并发出一个检查点barrier;
状态后端在状态存入检查点之后,会返回通知给source任务,source任务就会向JobManager确认检查点完成。
source1和source2收到检查点ID = 2时,分别存入自己的偏移量蓝3和黄4,存完之后返回一个ID2通知JobManager快照已保存好;(在保存快照时它会暂停发送和处理数据,同事它也会向下游发送带有检查点ID的barrier,发送的方式直接广播;这个过程中Sum和sink任务也没闲着都在处理数据)
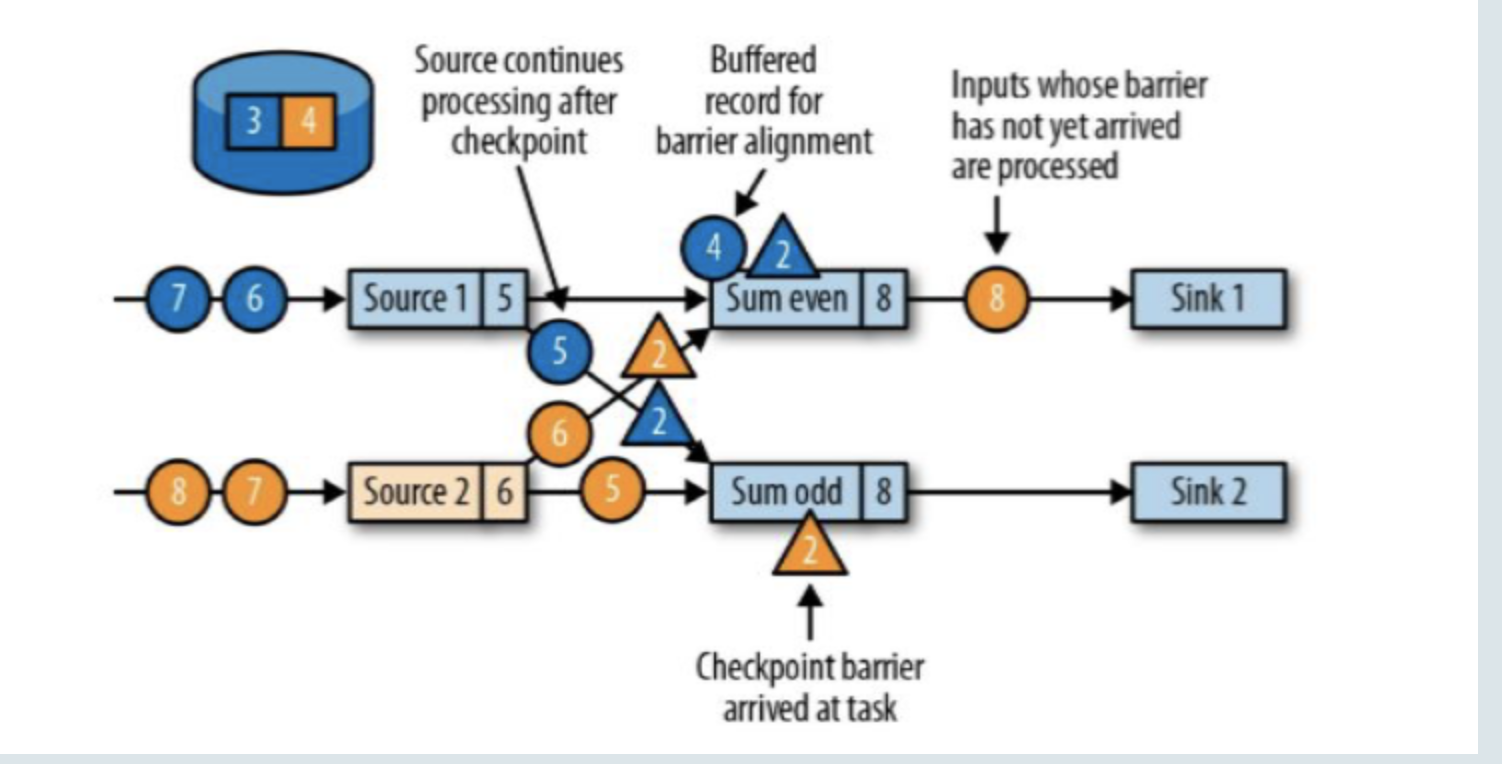
分界线对齐(barrier对齐):barrier向下游传递,sum任务会等待所有输入分区的的barrier到达;
对于barrier已经到达的分区,继续到达的数据会被缓存;而barrier尚未到达的分区,数据会被正常处理;
1 | (比如蓝2通知给了Sum even,它会等黄2的barrier到达,这时处理的数据4来了,会先被缓存因为它数据下一个checkpoint的数据; 黄2的checkpoint还没来这时它如果来数据还会正常处理更改状态,如上图的在黄2的barrier还没来之前,source2的数据来了条4,它会正常处理Sum event(**2** + **2 +** **4**)) |
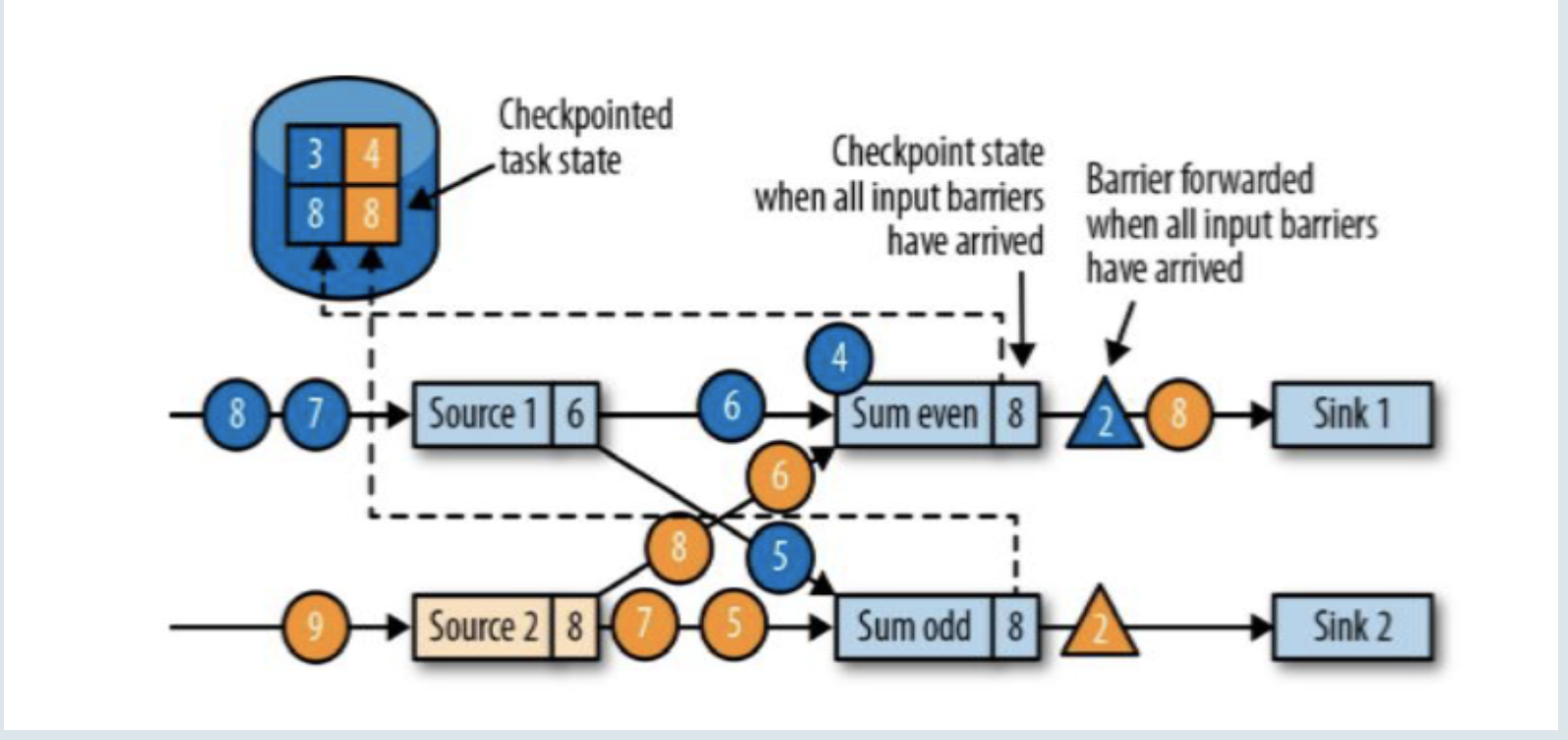
当收到所有输入分区的barrier时,任务就将其状态保存到状态后端的检查点中,然后将barrier继续向下游转发。
barrier对齐之后(Sum even和Sum odd都接收到了两个source发来的barrier),将它们各自的8状态存入checkpoint中;接下来继续向下游Sink广播barrier;
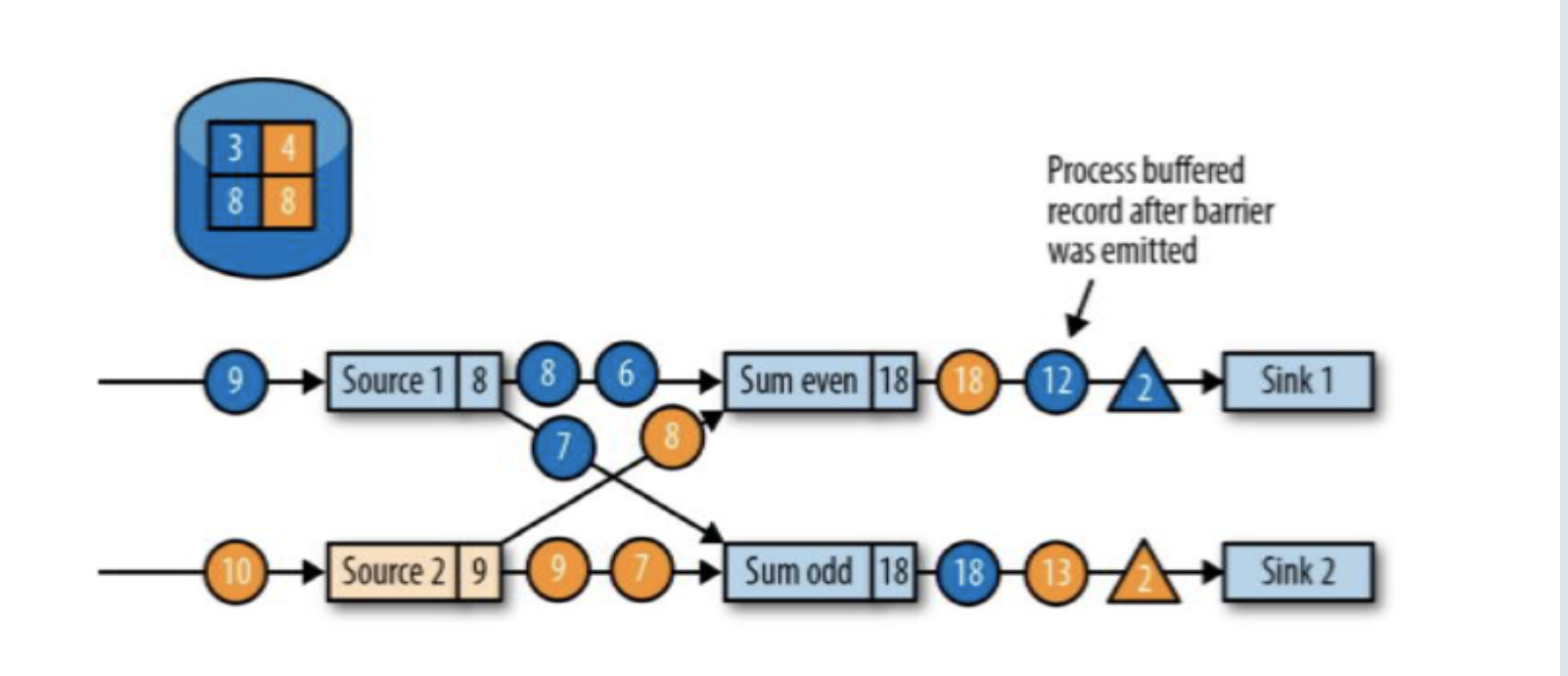
向下游转发检查点的barrier后,任务继续正常的数据处理;
先处理缓存的数据,蓝4加载进来Sum event 12,黄6进来Sum event 18。
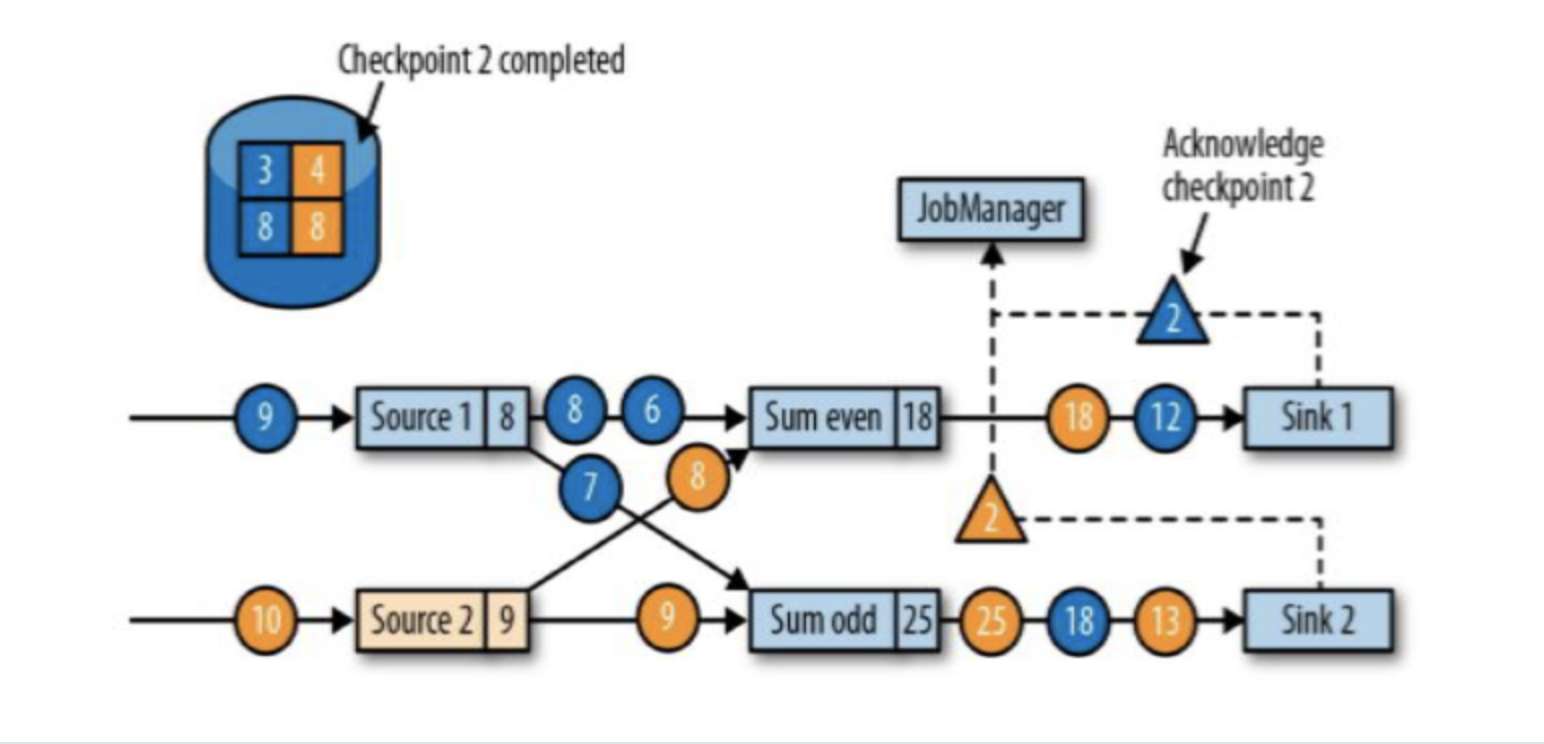
1:Sink任务向JobManager确认状态保存到checkpoint完毕;(Sink接收到barrier后先保存状态到checkpoint,然后向JobManager汇报;
2:当所有任务都确认已成功将状态保存到检查点时,检查点就真正完成了。
四 checkpoint的配置
1 | val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment |
五 重启策略配置
1 | import org.apache.flink.api.common.time.Time |
六 保存点(SavePoints)
1 | 1:Flink还提供了可以自定义的镜像保存功能,就是保存点(savepoints); |