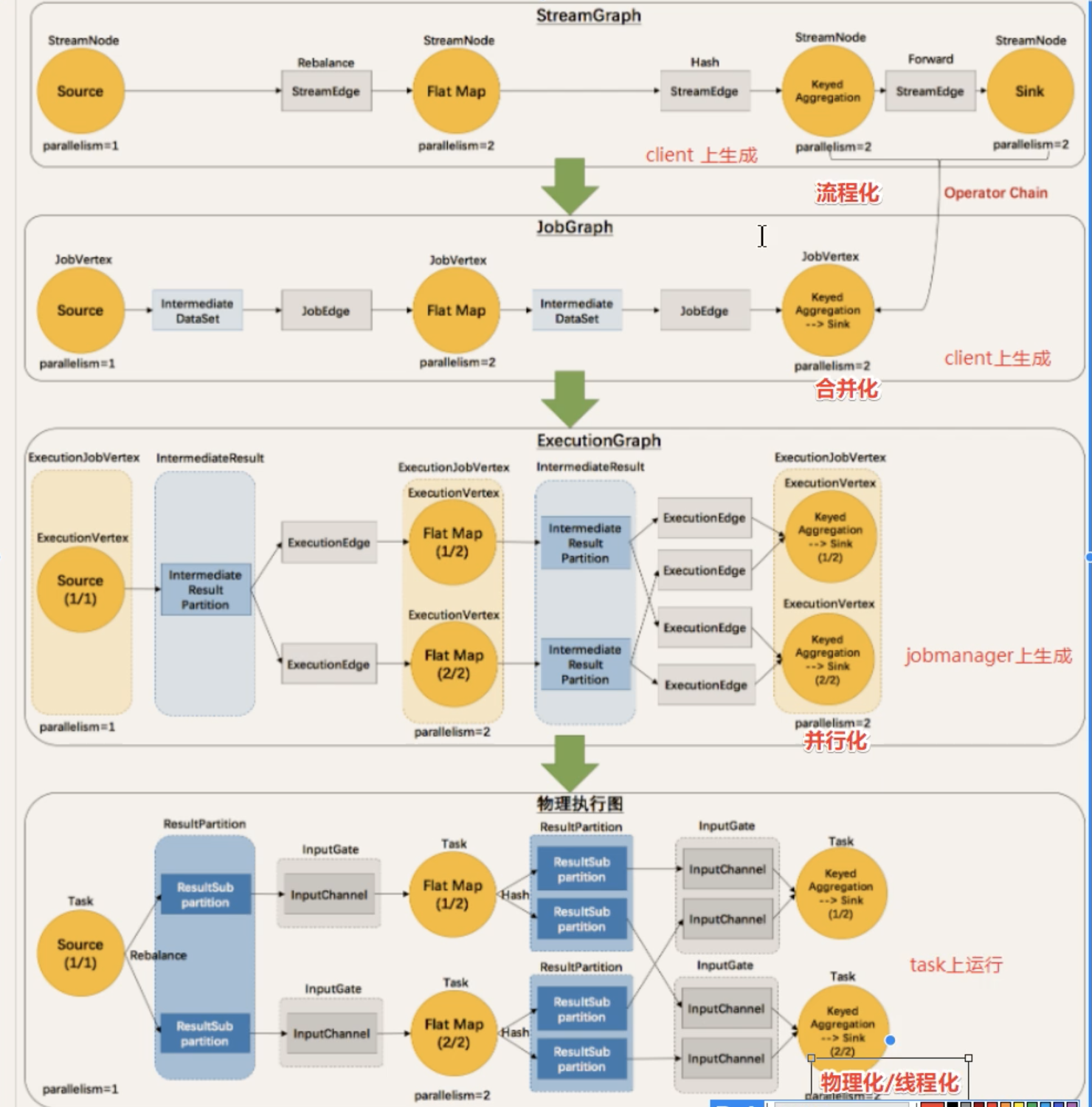
1
2
3
4
5
6
7
8
9
10
| spark与kafka有反压:
通过PIDRateEsimator 通过pid算法实现一个速率评估器(统计调度时间,任务处理时间,数据条数,得出一个消息处理最大速率,进而调整根据offset从kafka消费数据的速率 (是spark取拉kafka的数据))
flink:
1.5之后是自己实现了一个credit-based流控机制(1.5之前的背压解决方案有问题),在应用层模拟tcp的流控机制,就是ResultSubPartition向InputChanel发送消息的时候会发送一个backlog size告诉下游准备发送多少消息,下游会计算需要多少buffer去接受消息,算完之后若有充足的buffer就会返回一个credit,告知他可以发送消息,若是没有返回凭证上游等待下次通信返回,jobmanager针对每一个task没50ms发送100次 Thrad.getStackTrace()调用,求出每个task阻塞的占比
阻塞占比:
ok:0<= ratio <= 0.1 良好
low:0.1<ratio <= 0.5 有待观察
high: 0.5<ratio <=1 要处理 (增加并行度/subtask/是否数据倾斜/增加内存....)
这些信息在flink的监控平台可以看
|